score 表格如下:
题目: 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩

select `s_id`, avg(`s_score`), max(CASE when `c_id` = 01 then `s_score` else null end) as "语文", max(CASE when `c_id` = 02 then `s_score` else null end) as "数学", max(CASE when `c_id` = 03 then `s_score` else null end) as "英语" FROM score group BY `s_id` ORDER BY avg(`s_score`) desc
输出正确结果:

但是在想:既然case都判定课程编号了,那为什么还要用聚合函数max(sum也可以)呢?去掉聚合函数之后。
select `s_id`, avg(`s_score`), (CASE when `c_id` = 01 then `s_score` else null end) as "语文", (CASE when `c_id` = 02 then `s_score` else null end) as "数学", (CASE when `c_id` = 03 then `s_score` else null end) as "英语" FROM score group BY `s_id` ORDER BY avg(`s_score`) desc
输出结果:
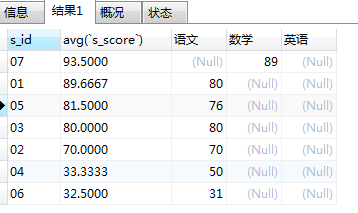
明显出现错误。
分析:这里跟case when没有多大关系,这是因为分组函数一定和聚合函数一同存在,要不然你想,比如上述数据,按照名字分组后,每个组内都有三个数据,而展示的时候就只展示第一条,而只有当与聚合函数一起使用的时候才会在聚合列的要选择字段进行迭代。
同理:sql书写要求:“出现在SELECT子句中的单独的列,必须出现在GROUP BY子句中作为分组列”