目录
- R-CNN
- SPP Net
- Fast R-CNN
- Faster R-CNN
- 总结
传统目标检测的主要问题
1)基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余
2)手工设计的特征对于多样性的变化没有很好的鲁棒性
候选区域/窗 + 深度学习分类也因此应运而生。
有人想到一个好方法:预先找出图中目标可能出现的位置,即region proposals或者 regions of interest(ROI)。利用图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口(几千甚至几百)的情况下保持较高的召回率(Recall)。
所以,问题就转变成找出可能含有物体的区域/框(也就是候选区域/框,比如选2000个候选框),这些框之间是可以互相重叠互相包含的,这样我们就可以避免暴力枚举的所有框了。

大牛们发明好多选定候选框Region Proposal的方法,比如Selective Search和EdgeBoxes。那提取候选框用到的算法"选择性搜索"到底怎么选出这些候选框的呢?具体可以看一下PAMI2015的"What makes for effective detection proposals?"
以下是各种选定候选框的方法的性能对比。
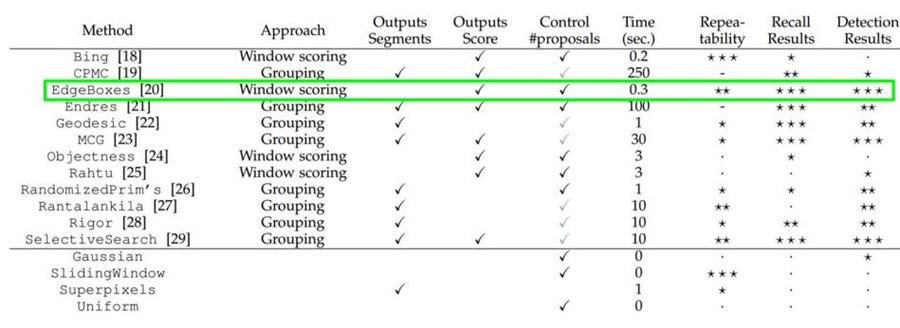
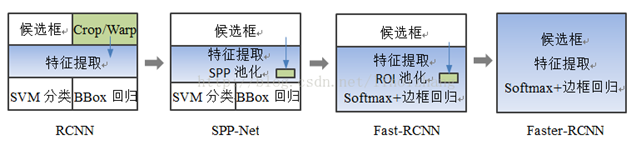
有了候选区域,剩下的工作实际就是对候选区域进行图像分类的工作(特征提取+分类)。本节只介绍R-CNN系列。
一、R-CNN
arxiv: http://arxiv.org/abs/1311.2524
github: https://github.com/rbgirshick/rcnn
slides: http://www.image-net.org/challenges/LSVRC/2013/slides/r-cnn-ilsvrc2013-workshop.pdf
再次做一个简单对比:
| 候选区域目标(RP) | 特征提取 | 分类 |
RCNN | selective search | CNN | SVM |
传统的算法 | objectness, constrainedparametric min-cuts, sliding window,edge boxes,.... | HOG , SIFT, LBP, BoW, DPM,... | SVM |
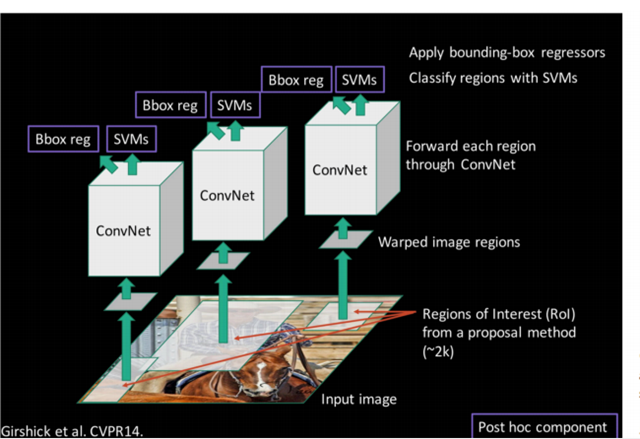
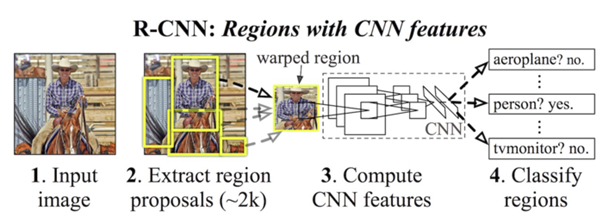
R-CNN的全称是Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。2014年,Ross B. Girshick使用Region Proposal + CNN代替传统目标检测使用的滑动窗口+手工设计特征,设计了R-CNN框架,使得目标检测取得巨大突破,并开启了基于深度学习目标检测的热潮。
1.1 选择性搜索(Selective Search)
采取过分割手段,将图像分割成小区域,再通过颜色直方图,梯度直方图相近等规则进行合并,最后生成约2000个建议框的操作。具体可见https://blog.csdn.net/mao_kun/article/details/50576003
step0:生成区域集R
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…} (颜色、纹理、尺寸和空间)
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
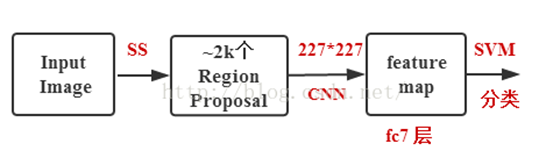
1.2 R-CNN的简要步骤
(1) 输入测试图像
(2) 利用选择性搜索Selective Search算法在图像中从下到上提取2000个左右的可能包含物体的候选区域Region Proposal
(3) 因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征
(4) 将每个Region Proposal提取到的CNN特征输入到SVM进行分类
具体步骤则如下
步骤一:训练(或者下载)一个分类模型(比如AlexNet)
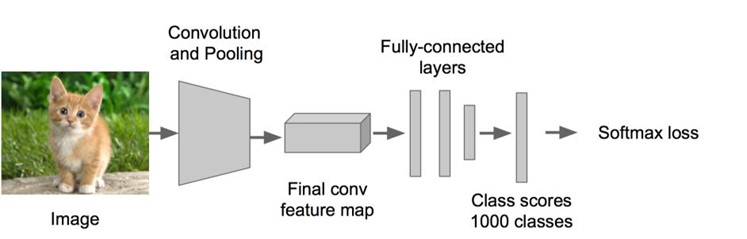
步骤二:对该模型做fine-tuning
• 将分类数从1000改为20,比如20个物体类别 + 1个背景
• 去掉最后一个全连接层

步骤三:特征提取
• 提取图像的所有候选框(选择性搜索Selective Search)
• 对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
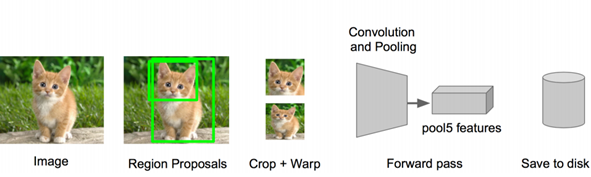
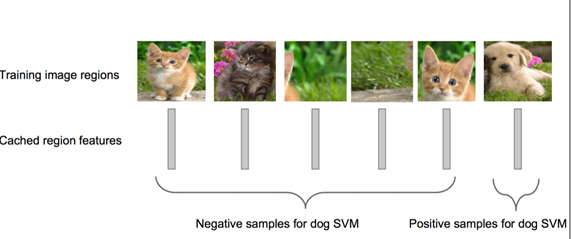
步骤四:训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative。
比如下图,就是狗分类的SVM
步骤五:使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。

R-CNN虽然不再像传统方法那样穷举,但R-CNN流程的第一步中对原始图片通过Selective Search提取的候选框region proposal多达2000个左右,而这2000个候选框每个框都需要进行CNN提特征+SVM分类,计算量很大,导致R-CNN检测速度很慢,一张图都需要47s。
1.3 创新点:
- 采用CNN网络提取图像特征,从经验驱动的人造特征范式HOG、SIFT到数据驱动的表示学习范式,提高特征对样本的表示能力;
- 采用大样本下有监督预训练+小样本微调的方式解决小样本难以训练甚至过拟合等问题。
1.4 简单回顾要点:
R-CNN 采用 AlexNet
R-CNN 采用 Selective Search 技术生成 Region Proposal.
R-CNN 在 ImageNet 上先进行预训练,然后利用成熟的权重参数在 PASCAL VOC 数据集上进行 fine-tune
R-CNN 用 CNN 抽取特征,然后用一系列的的 SVM 做类别预测。
R-CNN 的 bbox 位置回归基于 DPM 的灵感,自己训练了一个线性回归模型。
R-CNN 的语义分割采用 CPMC 生成 Region
1.5 问题点:
1)多个候选区域(2000个)对应的图像需要预先提取,占用较大的磁盘空间;
2)针对传统CNN需要固定尺寸的输入图像(共享参数),crop/warp(归一化)产生物体截断或拉伸,输入的图片Patch必须强制缩放成固定大小(原文采用227×227),会造成物体形变,导致检测性能下降。

众所周知,CNN一般都含有卷积部分和全连接部分,其中,卷积层不需要固定尺寸的图像,而全连接层是需要固定大小的输入。所以才如你在上文中看到的,在R-CNN中,"因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN"。
3)重复计算:R-CNN虽然不再是穷举,但通过Proposal(Selective Search)的方案依然有两千个左右的候选框,这些候选框都需要单独经过backbone网络提取特征,计算量依然很大,候选框之间会有重叠,因此有不少其实是重复计算。
4)速度慢:前面的缺点最终导致R-CN慢,GPU上处理一张图片需要十几秒,CPU上则需要更长时间。
有没有方法提速呢?答案是有的,这2000个region proposal不都是图像的一部分吗,那么我们完全可以对图像提一次卷积层特征,然后只需要将region proposal在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个region proposal的卷积层特征输入到全连接层做后续操作。
但现在的问题是每个region proposal的尺度不一样,而全连接层输入必须是固定的长度,所以直接这样输入全连接层肯定是不行的。SPP Net恰好可以解决这个问题。
二、SPP Net
arxiv: http://arxiv.org/abs/1406.4729
github: https://github.com/ShaoqingRen/SPP_net
SPP:Spatial Pyramid Pooling(空间金字塔池化)。SPP-Net是出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》。
针对卷积神经网络重复运算问题,2015年微软研究院的何恺明等提出一种SPP-Net算法,通过在卷积层和全连接层之间加入空间金字塔池化结构(Spatial Pyramid Pooling SPP)代替R-CNN算法在输入卷积神经网络前对各个候选区域进行剪裁、缩放操作使其图像子块尺寸一致的做法。利用空间金字塔池化结构有效避免:
- R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题,
- 解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
但是和R-CNN算法一样训练数据的图像尺寸大小不一致,导致候选框的ROI感受野大,不能利用BP高效更新权重。
下图便是R-CNN和SPP Net检测流程的比较:


2.1 特点:
1.结合空间金字塔方法实现CNNs的多尺度输入。
SPP Net的第一个贡献就是在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。
换句话说,在普通的CNN机构中,输入图像的尺寸往往是固定的(比如224*224像素),输出则是一个固定维数的向量。SPP Net在普通的CNN结构中加入了SPP-Layer,使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。
简言之,CNN原本只能固定输入、固定输出,CNN加上SSP之后,便能任意输入、固定输出。
ROI池化层一般跟在卷积层后面,此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出则是固定维数的向量,然后给到全连接FC层。
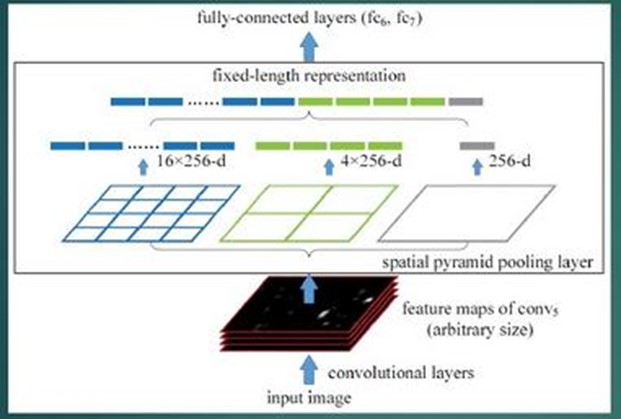
2.只对原图提取一次卷积特征
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。
而SPP Net根据这个缺点做了优化:只对原图进行一次卷积计算,便得到整张图的卷积特征feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层,完成特征提取工作。
如此这般,R-CNN要对每个区域计算卷积,而SPPNet只需要计算一次卷积,从而节省了大量的计算时间,比R-CNN有一百倍左右的提速。
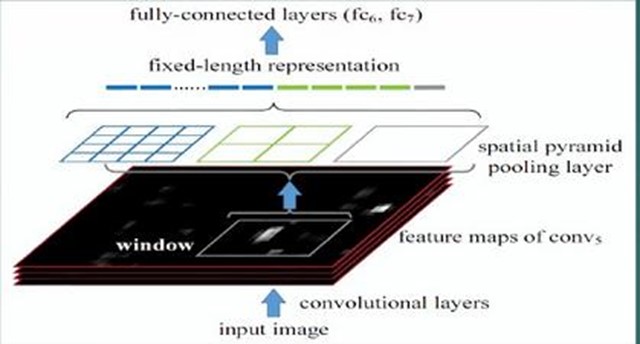
2.2 算法流程:
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度是大大地快啊。江湖传说可一个提高100倍的速度,因为R-CNN就相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
2.3 创新点:
- 利用空间金字塔池化结构;
- 对整张图片只进行了一次特征提取,加快运算速度。
2.4 缺点
尽管SPP-Net贡献很大,仍然存在很多问题:
1)和RCNN一样,训练过程仍然是隔离的,提取候选框 | 计算CNN特征| SVM分类 | Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数;
2)SPP-Net在无法同时Tuning在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN的效果;
3)在整个过程中,Proposal Region仍然很耗时。
三、 Fast R-CNN
arxiv: http://arxiv.org/abs/1504.08083
github: https://github.com/rbgirshick/fast-rcnn
slides: http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
针对SPP-Net算法的问题,2015年微软研究院的Ross B. Girshick又提出一种改进的Fast R-CNN算法,借鉴SPP-Net算法结构,设计一种ROI pooling的池化层结构,有效解决R-CNN算法必须将图像区域剪裁、缩放到相同尺寸大小的操作。

Fast-RCNN主要贡献在于对RCNN进行加速,问题在以下方面得到改进:
1)借鉴SPP思路,提出简化版的ROI池化层(注意,没用金字塔),同时加入了候选框映射功能,使得网络能够反向传播,解决了SPP的整体网络训练问题;
2) 多任务Loss层
A)SoftmaxLoss代替了SVM,证明了softmax比SVM更好的效果;
B)Smooth L1Loss取代Bouding box回归。
将分类和边框回归进行合并(又一个开创性的思路),通过多任务Loss层进一步整合深度网络,统一了训练过程,从而提高了算法准确度。
3)全连接层通过SVD加速,这个大家可以自己看,有一定的提升但不是革命性的。
4)结合上面的改进,模型训练时可对所有层进行更新,除了速度提升外(训练速度是SPP的3倍,测试速度10倍),得到了更好的检测效果(VOC07数据集mAP为70,注:mAP,mean Average Precision)。
1.1 算法流程
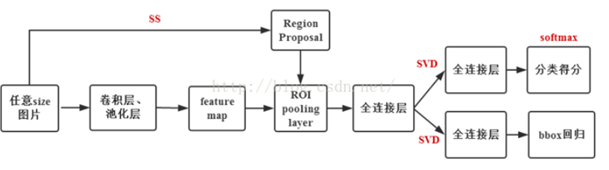
1.2 创新点
- 提出RoI Pooling 层,它将不同大小候选框的卷积特征图统一采样成固定大小的特征。
- 独立的SVM分类器和回归器需要大量特征作为训练样本,需要大量的硬盘空间,Fast-RCNN把类别判断和位置回归统一用深度神经网络实现,不再需要额外存储。
1.3 ROI
什么是ROI呢?
ROI是Region of Interest的简写,指的是在"特征图上的框";
1)在Fast RCNN中, RoI是指Selective Search完成后得到的"候选框"在特征图上的映射;
2)在Faster RCNN中,候选框是经过RPN产生的,然后再把各个"候选框"映射到特征图上,得到RoIs。
ROI Pooling的输入:输入有两部分组成:
- 特征图:在Fast RCNN中,它位于RoI Pooling之前,在Faster RCNN中,它是与RPN共享那个特征图,通常我们常常称之为"share_conv";
- ROIS :在Fast RCNN中,指的是Selective Search的输出;在Faster RCNN中指的是RPN的输出,一堆矩形候选框框,形状为1x5x1x1(4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)。
ROI Pooling的输出
输出是batch个vector,其中batch的值等于RoI的个数,vector的大小为channel * w * h;RoI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框;
ROI Pooling的过程
先把ROI中的坐标映射到feature map上,映射规则比较简单,就是把各个坐标除以"输入图片与feature map的大小的比值",得到了feature map上的box坐标后,使用Pooling得到输出;由于输入的图片大小不一,所以这里使用的类似Spp Pooling,在Pooling的过程中需要计算Pooling后的结果对应到feature map上所占的范围,然后在那个范围中进行取max或者取average。
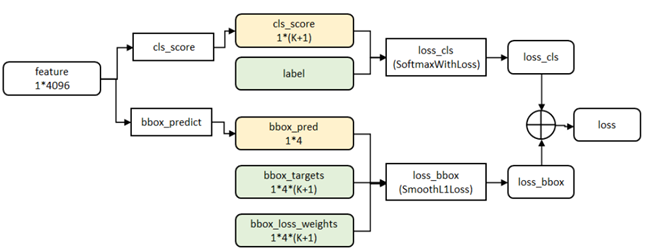
- cls_score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。
- bbox_prdict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
1.4 小结:
R-CNN有一些相当大的缺点(把这些缺点都改掉了,就成了Fast R-CNN)。
大缺点:由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。
解决:共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征
原来的方法:许多候选框(比如两千个)-->CNN-->得到每个候选框的特征-->分类+回归
现在的方法:一张完整图片-->CNN-->得到每张候选框的特征-->分类+回归
因为Fast RCNN使用的是selective search选择性搜索,这一过程十分耗费时间,其进行候选区域提取所花费的时间约为2~3秒,而提取特征分类仅需要0.32秒[19],这会造成无法满足实时应用需求,而且因为使用selective search来预先提取候选区域,Fast RCNN并没有实现真正意义上的端到端训练模式,因此在众人的努力下,Faster RCNN应运而生。
四、 Faster R-CNN
arxiv: http://arxiv.org/abs/1506.01497
github(official, Matlab): https://github.com/ShaoqingRen/faster_rcnn
github: https://github.com/rbgirshick/py-faster-rcnn
github(MXNet): https://github.com/msracver/Deformable-ConvNets/tree/master/faster_rcnn
github: https://github.com//jwyang/faster-rcnn.pytorch
github: https://github.com/mitmul/chainer-faster-rcnn
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,提取一副图像大概需要2s的时间,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?
候选框提取不一定要在原图上做,特征图上同样可以,低分辨率特征图意味着更少的计算量,基于这个假设,MSRA的任少卿等人提出RPN(Region Proposal Network 区域候选网络),完美解决了这个问题,
4.1 RPN网络结构
关注的它是不是物体,及其得分,没有考虑分类问题。
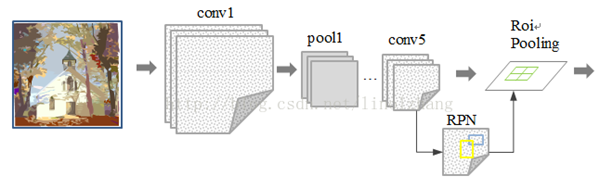
过添加额外的RPN分支网络,将候选框提取合并到深度网络中,允许GPU加速进行,这正是Faster-RCNN里程碑式的贡献。
Region Proposal Networks:RPN是Faster RCNN出新提出来的proposal生成网络。其替代了之前RCNN和Fast RCNN中的selective search方法,将所有内容整合在一个网络中,大大提高了检测速度。
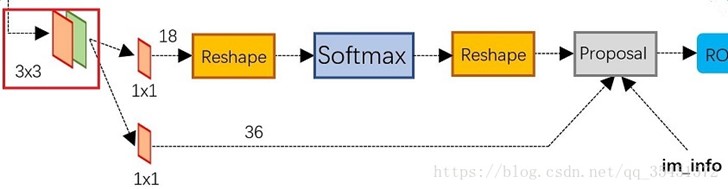
RPN网络结构:
生成anchors -> softmax判定foreground与background-> bbox reg回归fg anchors -> Proposal Layer生成proposals
RPN简介:
• 在feature map上滑动窗口
• 建一个神经网络用于物体分类+框位置的回归
• 滑动窗口的位置提供了物体的大体位置信息
• 框的回归提供了框更精确的位置
具体的,通过滑动窗口的方式实现候选框的提取,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高,不同比例,不同大小),提取对应k=9个候选窗口(anchor)(框的比例1:1,1:2,2:1,一共3*3个)的特征,用于目标分类和边框回归,与FastRCNN类似。目标分类只需要区分候选框内特征为前景或者背景。边框回归确定更精确的目标位置,基本网络结构如下图所示:
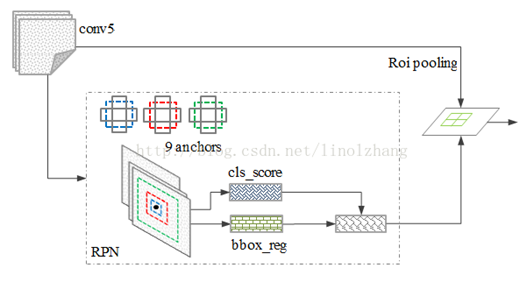
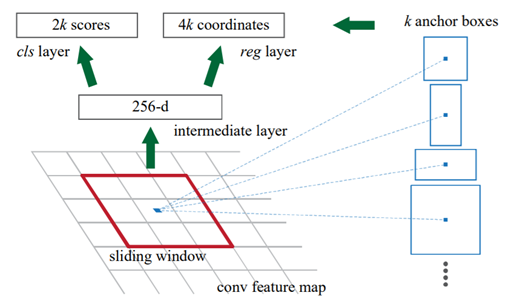
其中,cls score层(分类任务,判断是否为物体,有2种可能情况,一共2*9种);reg(用于回归4个值,即框的属性,一个4个值,一共4*9)
训练过程中,涉及到的候选框选取,选取依据:
1)丢弃跨越边界的anchor;
2)与样本IOU(重叠区域)大于0.7的anchor标记为物品,重叠区域小于0.3的标定为非物品,即背景。0.3-0.7暂时不管;
说明:这里也有损失函数,其设计的时候,分类和回归的损失有一个参数调节比重。
4.2 Faster RCNN的网络结构
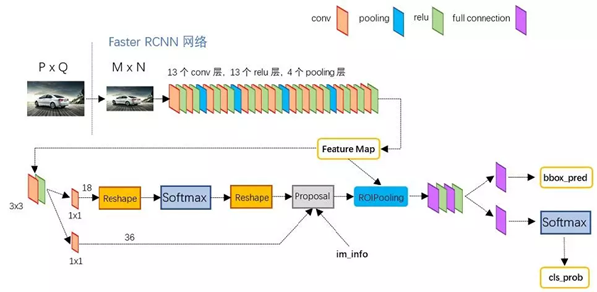
Faster RCNN的网络结构(基于VGG16),其实可以分为4个主要内容:
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
4.3 算法流程
- 把整张图片送入CNN,进行特征提取;
- 在最后一层卷积feature map上生成region proposal(通过RPN),每张图片大约300个建议窗口;
- 通过RoI pooling层(其实是单层的SPP layer)使得每个建议窗口生成固定大小的feature map;
- 继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量。第一个是分类,使用softmax,第二个是每一类的bounding box回归。利用SoftMax Loss和Smooth L1 Loss对分类概率和边框回归(Bounding Box Regression)联合训练。
4.4 创新点
- 采用RPN(Region Proposal Network)代替选择性搜索(Selective Search),利用GPU进行计算大幅度缩减提取region proposal的速度。
- 产生建议窗口的CNN和目标检测的CNN共享。
在主干网络中增加了RPN网络,通过一定规则设置不同尺度的锚点(Anchor)在RPN的卷积特征层提取候选框来代替Selective Search等传统的候选框生成方法,实现了网络的端到端训练。候选区域生成、候选区域特征提取、框回归和分类全过程一气呵成,在训练过程中模型各部分不仅学习如何完成自己的任务,还自主学习如何相互配合。这也是第一个真正意义上的深度学习目标检测算法。
五、总结
R-CNN(Selective Search + CNN + SVM)
SPP-net(ROI Pooling)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)
总的来说,从R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走来,基于深度学习目标检测的流程变得越来越精简,精度越来越高,速度也越来越快。可以说基于Region Proposal的R-CNN系列目标检测方法是当前目标检测技术领域最主要的一个分支。
对比:
| 使用方法 | 缺点 | 改进 |
R-NN | 1.Selective Search提取RP(多次提取约2K张,多个CNN) 2.CNN提取特征 3.SVM分类 4.BB盒回归 | 1.训练步骤繁琐(微调网络,SVM+训练bbox),选取图片强制伸缩,会造成失真 2.训练测试均很慢 3.训练占空间 | 1.从DPM HSC34%提升至66% 2.引进RP+ CNN 3.用时49S |
SPP | 1.CNN提取特征 2.Selective Search提取RP(spp) 3.SVM分类 4.BB盒回归 | 1)和RCNN一样,训练过程仍然是隔离的,众多均是独立训练,大量的中间结果需要转存,无法整体训练参数; 2)SPP-Net在无法同时Tuning在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN的效果; 3)在整个过程中,Proposal Region仍然很耗时。 | 速度提升至4.3S |
Fast R-CNN | 1.CNN提取特征 2.Selective Search提取RP(整体提取,一个CNN)使用ROI层 3.softmax分类 4.多任务损失函数边框回归 | 1.先CNN,后ss提取PR(耗时2-3S,特征提取0.32S),ROI Pooling 成相同大小 2.无法满足实时应用,没有真正端到端的训练测试
| 1.精度提升至77% 2.每张图耗时3S |
Faster R-CNN | 1.RPN提取RP 2.CNN提取特征 3.softmax分类 4.多任务损失函数边框回归 | 1.无法达到实时检测目标 2.获取region proposal,再对每个proposal分类计算量较大 | 1.提高了精度和速度 2.实现端到端目标检测框架 3.生成建议框仅需10ms |
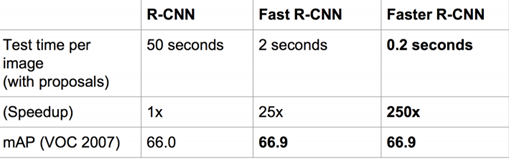
对标效果
主要来自: