Hadoop ha CDH5.15.1-hadoop集群启动后,两个namenode都是standby模式
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一说起周五,想必大家都特别开心对吧?其实我也很开心呀~眼看还剩下一个小时就下班了。然而在这一个小时内,我都心里活动真的是跌宕起伏呀~不是因为放假,而是身为一名大数据运维技术人员需要替公司大数据生态圈中面临都各种问题。
这不,遇到了一个奇葩的问题,让我花了接近一个小时才处理完呢!深感惭愧啊,要是有小伙伴遇到跟我同样的问题,别慌!恭喜你,在这里你需要花费1分钟看完我的处理过程,然后可能只需要不到10分钟就能这个问题给解决掉。因为这个坑我已经替你给添了。
一.踩坑环境准备
1>.昨天下午15:30左右对操作系统进行调优,修改一大波内核参数,具体参数如下:(如果大家对下面的参数觉得有任何不合理的地方,欢迎大家留言,帮我指正。)
net.ipv6.conf.all.disable_ipv6 = 1 net.core.rmem_default = 256960 net.core.rmem_max = 513920 net.core.wmem_default = 256960 net.core.wmem_max = 513920 net.core.netdev_max_backlog = 2000 net.core.somaxconn = 2048 net.core.optmem_max = 81920 net.ipv4.tcp_mem = 131072 262144 524288 net.ipv4.tcp_rmem = 8760 256960 4088000 net.ipv4.tcp_wmem = 8760 256960 4088000 net.ipv4.tcp_keepalive_time = 1800 net.ipv4.tcp_keepalive_intvl = 30 net.ipv4.tcp_keepalive_probes = 3 net.ipv4.tcp_sack = 1 net.ipv4.tcp_fack = 1 net.ipv4.tcp_timestamps = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30 net.ipv4.ip_local_port_range = 1024 65000 net.ipv4.tcp_max_syn_backlog = 2048 vm.dirty_ratio = 80 vm.dirty_background_ratio = 5 vm.swappiness = 1
2>.开发反馈spark程序和mapreduce程序跑的倍儿慢
开发说和之前想比较,同样的任务之前跑不到5分钟就可以跑完,现在跑个20分钟才能跑完。还有的任务跑的直接就提交不了!一个劲儿的报错,哎呀妈呀~我心里以嘀咕,这波参数调的有点小尴尬啊,没把集群调试更好,反而调试的更差啦!开发还给我发了相关日志记录,如下:


[root@rsync115 against_cheating_extract]# yarn logs -applicationId application_1542888832576_2698 > application_1542888832576_2698 18/11/23 15:48:02 INFO client.RMProxy: Connecting to ResourceManager at calculation101.aggrx/10.1.1.101:8032 18/11/23 15:49:06 WARN hdfs.BlockReaderFactory: I/O error constructing remote block reader. java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/10.1.3.115:48474 remote=/10.1.1.119:50010] at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:164) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:118) at java.io.FilterInputStream.read(FilterInputStream.java:83) at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:2305) at org.apache.hadoop.hdfs.RemoteBlockReader2.newBlockReader(RemoteBlockReader2.java:430) at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReader(BlockReaderFactory.java:890) at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:768) at org.apache.hadoop.hdfs.BlockReaderFactory.build(BlockReaderFactory.java:377) at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:666) at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:904) at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:963) at java.io.DataInputStream.readFully(DataInputStream.java:195) at java.io.DataInputStream.readLong(DataInputStream.java:416) at org.apache.hadoop.io.file.tfile.BCFile$Reader.<init>(BCFile.java:626) at org.apache.hadoop.io.file.tfile.TFile$Reader.<init>(TFile.java:804) at org.apache.hadoop.yarn.logaggregation.AggregatedLogFormat$LogReader.<init>(AggregatedLogFormat.java:488) at org.apache.hadoop.yarn.logaggregation.LogCLIHelpers.dumpAllContainersLogs(LogCLIHelpers.java:173) at org.apache.hadoop.yarn.client.cli.LogsCLI.run(LogsCLI.java:133) at org.apache.hadoop.yarn.client.cli.LogsCLI.main(LogsCLI.java:186) 18/11/23 15:49:06 WARN hdfs.DFSClient: Failed to connect to /10.1.1.119:50010 for block BP-1071333876-10.1.1.101-1538100459813:blk_1095494105_21758975, add to deadNodes and continue. java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/10.1.3.115:48474 remote=/10.1.1.119:50010] at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:164) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:118) at java.io.FilterInputStream.read(FilterInputStream.java:83) at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:2305) at org.apache.hadoop.hdfs.RemoteBlockReader2.newBlockReader(RemoteBlockReader2.java:430) at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReader(BlockReaderFactory.java:890) at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:768) at org.apache.hadoop.hdfs.BlockReaderFactory.build(BlockReaderFactory.java:377) at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:666) at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:904) at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:963) at java.io.DataInputStream.readFully(DataInputStream.java:195) at java.io.DataInputStream.readLong(DataInputStream.java:416) at org.apache.hadoop.io.file.tfile.BCFile$Reader.<init>(BCFile.java:626) at org.apache.hadoop.io.file.tfile.TFile$Reader.<init>(TFile.java:804) at org.apache.hadoop.yarn.logaggregation.AggregatedLogFormat$LogReader.<init>(AggregatedLogFormat.java:488) at org.apache.hadoop.yarn.logaggregation.LogCLIHelpers.dumpAllContainersLogs(LogCLIHelpers.java:173) at org.apache.hadoop.yarn.client.cli.LogsCLI.run(LogsCLI.java:133) at org.apache.hadoop.yarn.client.cli.LogsCLI.main(LogsCLI.java:186) 18/11/23 15:49:06 INFO hdfs.DFSClient: Successfully connected to /10.1.1.115:50010 for BP-1071333876-10.1.1.101-1538100459813:blk_1095494105_21758975 [root@rsync115 against_cheating_extract]# yarn logs -applicationId application_1542888832576_2698 > application_1542888832576_2698 18/11/23 15:49:24 INFO client.RMProxy: Connecting to ResourceManager at calculation101.aggrx/10.1.1.101:8032 [root@rsync115 against_cheating_extract]#
其实,上面的报错信息只是程序运行的日志,还有其他服务也出现类似的故障啦!并没有什么太大的参考意义。于是我将我的配置还原,把修改的参数使用默认的恢复回去,发现依旧没有解决问题,没法了,我就只得重启操作系统啦!在重启操作系统之前,需要把所有的服务都正常关闭。其次,我将上面一大坨参数进行了修改,只保留了一条优化:
vm.swappiness = 10 #这个是降低使用swap几率的内核参数,越小越好,但不推荐设置为0。
3>.重启操作系统后,hdfs集群没法正常使用了。
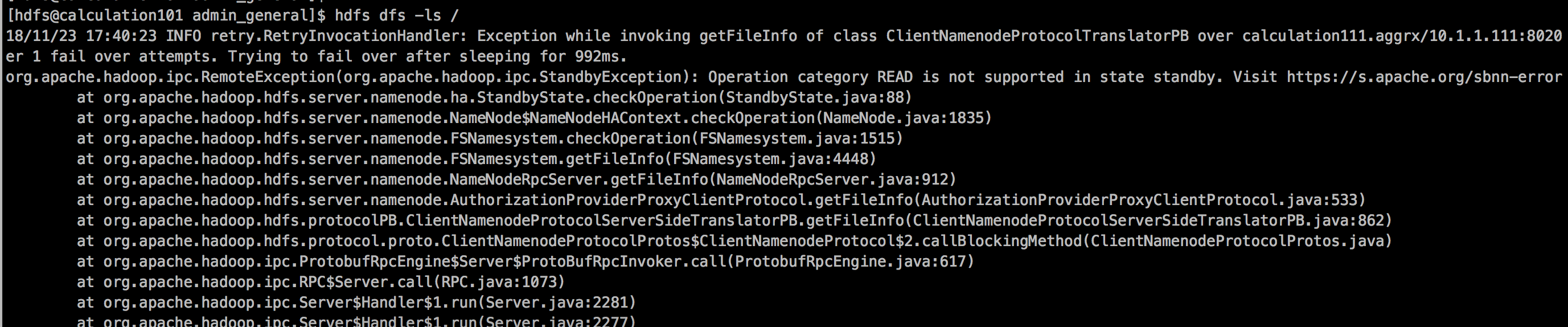
二.填坑步骤详解
1>.查看hdfs的WebUI

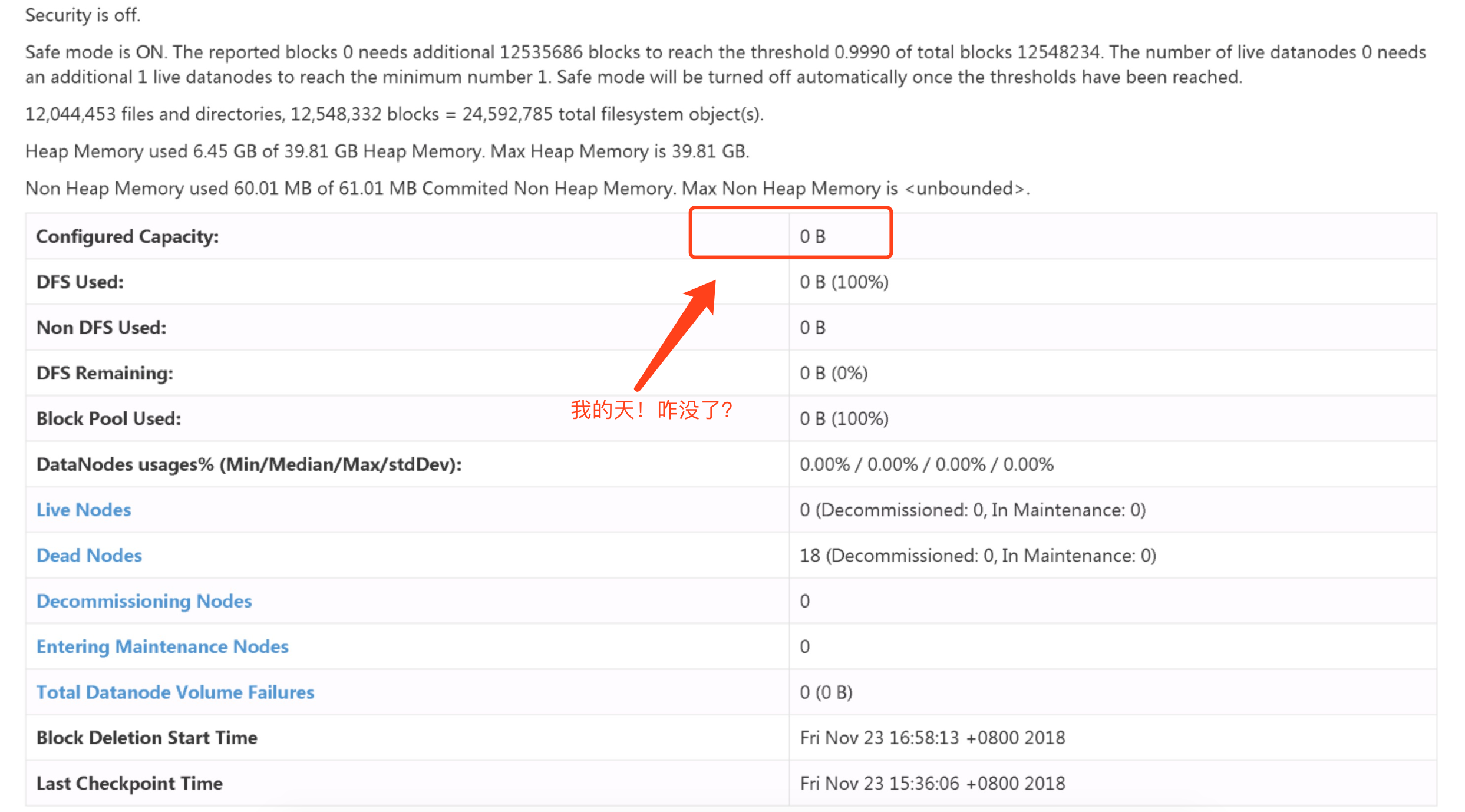
2>.查看webUI界面,发现NN节点容量竟然为0!
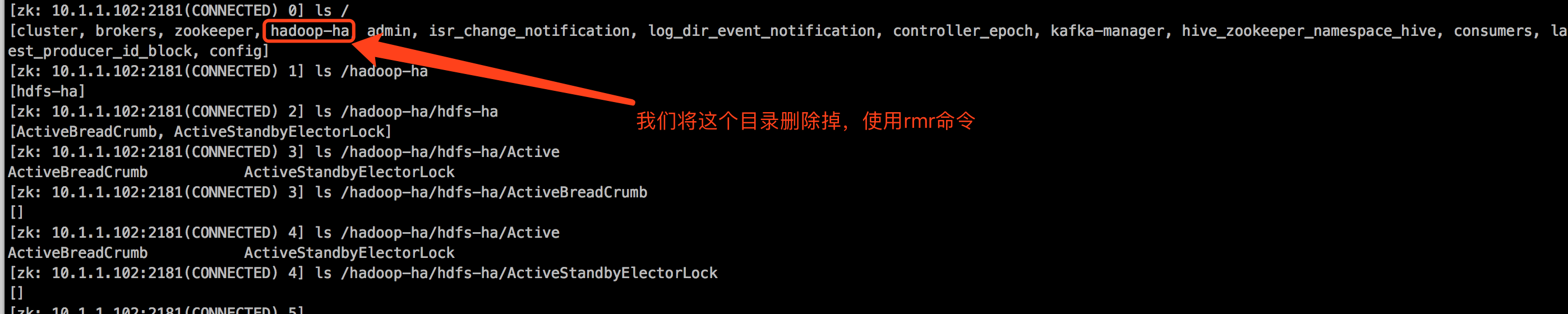
3>.集群处于安全模式
想必大家都懂hdfs的原理,NN节点在启动时需要加载编辑日志和镜像文件,而加载的过程也就是它校验,比如副本数,块数,权限之类的等等,等他将所有需要检验的数据校验完毕就会自动退出安全模式。
查看集群的安全模式:hadoop dfsadmin -safemode get DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Safe mode is ON in calculation101.aggrx/10.1.1.101:8020 Safe mode is ON in calculation111.aggrx/10.1.1.111:8020
4>.手动退出安全模式
手动退出安全模式:hdfs dfsadmin -safemode leave 再次查看集群的安全模式:hadoop dfsadmin -safemode get DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Safe mode is OFF in calculation101.aggrx/10.1.1.101:8020 Safe mode is OFF in calculation111.aggrx/10.1.1.111:8020
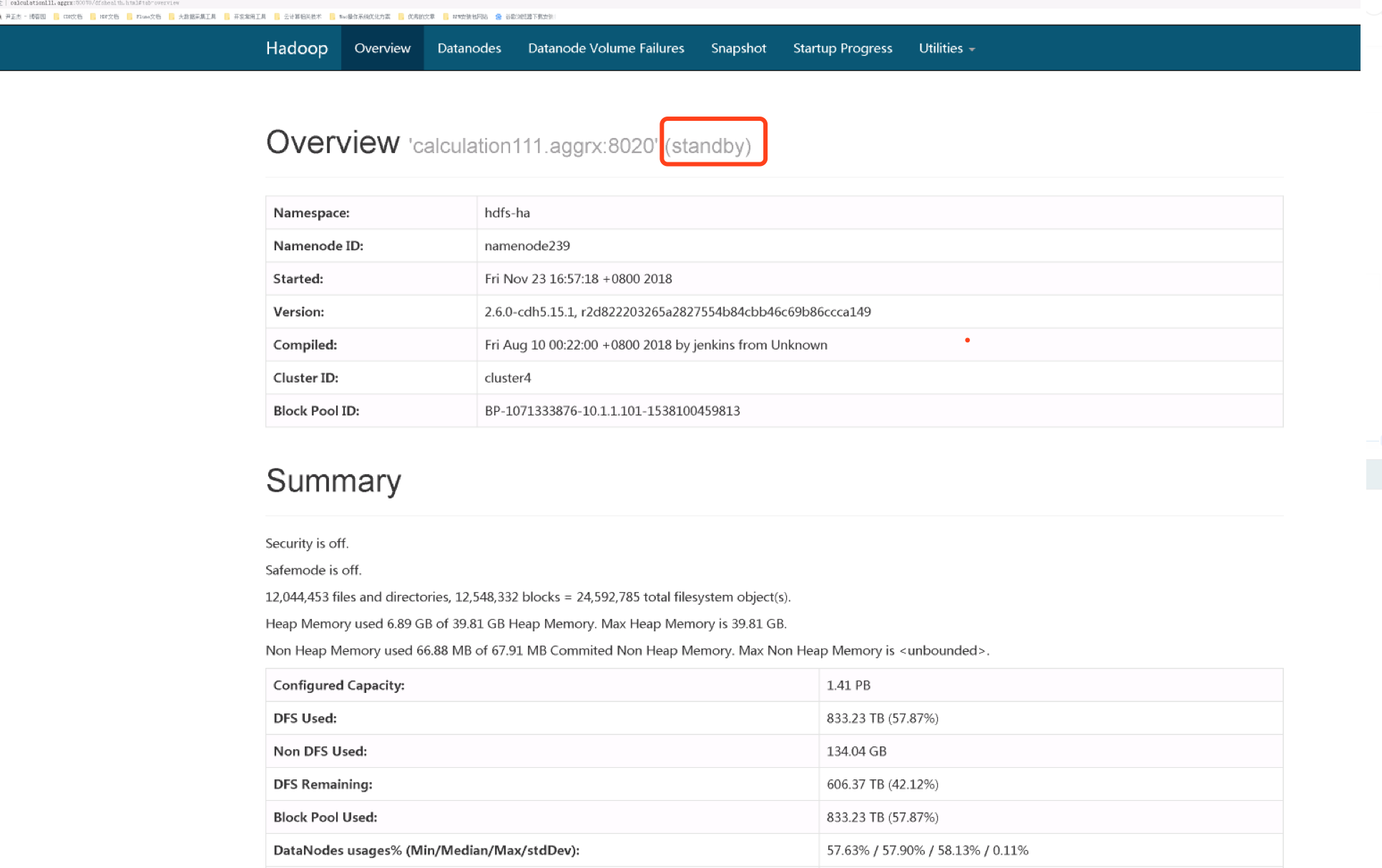
5>.发现是有数据了,但是查看10.1.1.101节点,其状态为standby模式

6>. 查看10.1.1.111节点,其状态依旧是standby模式
7>.手动切换NameNode节点的状态(很显然,权限被拒绝了。因为我开启了zkfc负责管理NN节点的状态,因此手动修改是无效的!)
[hdfs@calculation101 ~]$ hdfs haadmin -transitionToActive nn1 Automatic failover is enabled for NameNode at calculation101.aggrx/10.1.1.101:8022 Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state. If you are very sure you know what you are doing, please specify the forcemanual flag. You have new mail in /var/spool/mail/root [hdfs@calculation101 ~]$

8>.关闭自动容灾并重启hdfs集群(dfs.ha.automatic-failover.enabled)
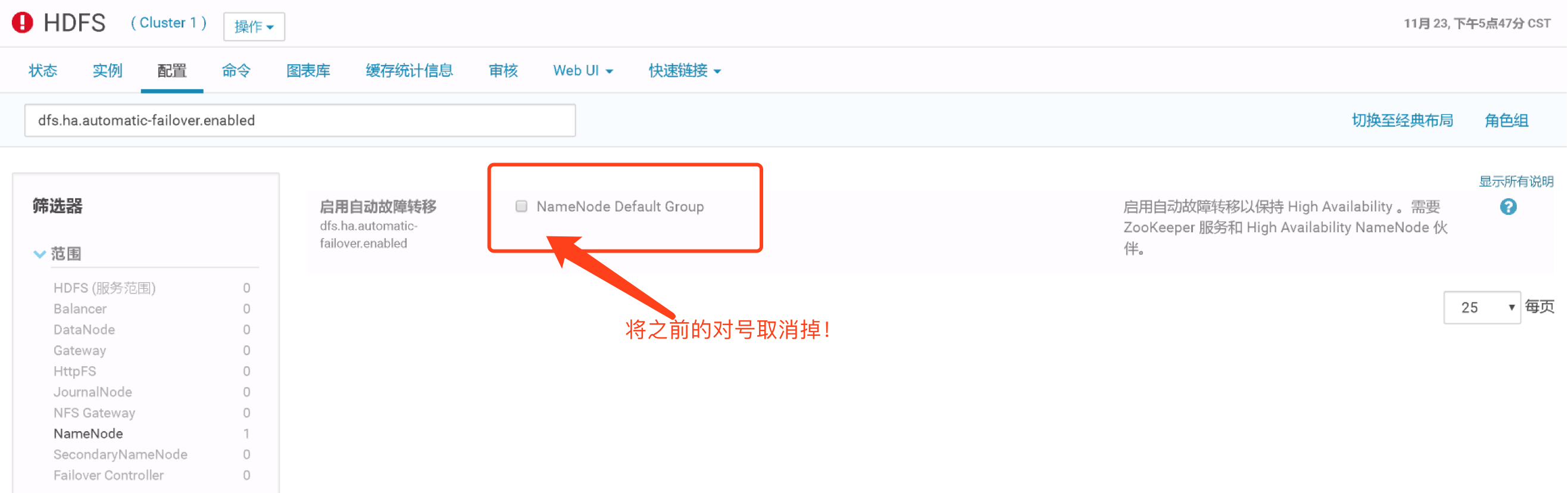
9>.关闭zkfs后,发现我的NN节点就有一个节点变为active模式啦!

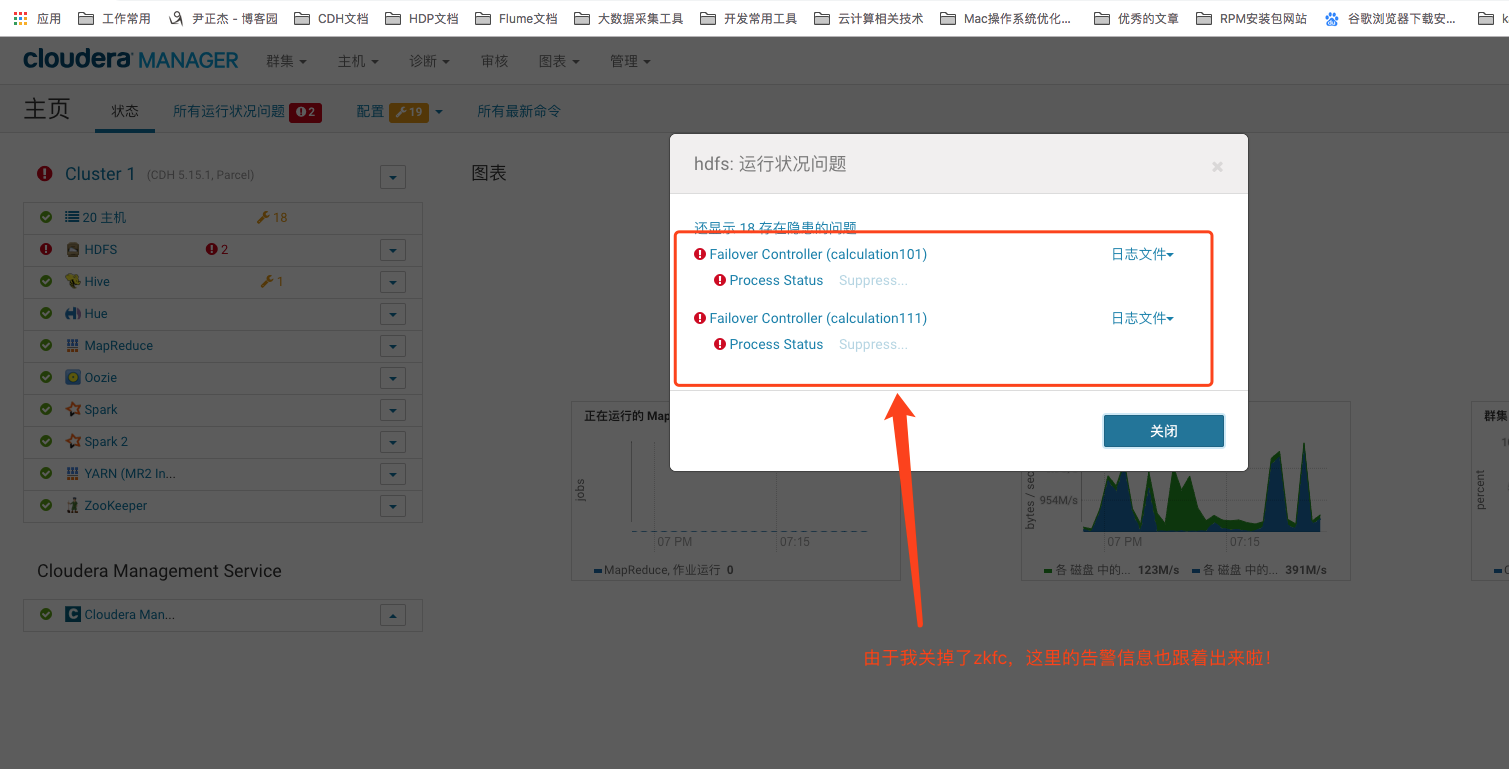
10>.告警信息预览(zkfc服务被我禁用掉啦!)
三.为什么会出现这种情况,如何防止?
1>.一般导致NameNode切换的原因
随着集群规模的变大和任务量变多,NameNode的压力会越来越大,一些默认参数已经不能满足集群的日常需求,除此之外,异常的Job在短时间内创建和删除大量文件,引起NN节点频繁更新内存的数据结构从而导致RPC的处理时间变长,CallQueue里面的RpcCall堆积,甚至严重的情况下打满CallQueue,导致NameNode响应变慢,甚至无响应,ZKFC的HealthMonitor监控自己的NN异常时,则会断开与ZooKeeper的链接,从而释放锁,另外一个NN上的ZKFC进行抢锁进行Standby到Active状态的切换。这是一般引起的切换的流程。
当然,如果你是手动去切换这也是可以的,当Active主机出现异常时,有时候则需要在必要的时间内进行切换。
2>.ZKFC的作用是什么?如何判断一个NN是否健康
在正常的情况下,ZKFC的HealthMonitor主要是监控NameNode主机上的磁盘还是否可用(空间),我们都知道,NameNode负责维护集群上的元数据信息,当磁盘不可用的时候,NN就该进行切换了。
除了可用状态(SERVICE_HEALTHY)之外,还有SERVICE_UNHEALTHY(磁盘空间不可用),SERVICE_NOT_RESPONDING(其他的一些情况)状态,在这两个状态中,它都认为NN是不健康的。
3>.NameNode HA是如何实现的?
详情请参考:https://www.cnblogs.com/lixiaolun/p/6897706.html
4>.NameNode因为断电导致不能切换的原理,怎样进行恢复
ActiveNN断电,网络异常,负载过高或者机器出现异常无法连接,Standby NN无法转化为Active,使得HA集群无法对外服务,原因是Active NN节点在断电和不能服务的情况下,zknode上保存着ActiveBreadCrumb, ActiveStandbyElectorLock两个Active NN的信息,ActiveStandbyElectorLock由于Active NN出现异常断开,Standby NN去抢锁的时候就会去检查ActiveBreadCrumb是否有上一次的Active NN节点,如果有,就会就会尝试让Active NN变为Standby NN,自己转化为Active NN,但是由于调用出现异常,所以会采用ssh的方式去Fence之前的Active NN,因为机器始终连接不上,所以无法确保old active NN变为Standby NN,自己也无法变为Active NN,所以还是保持Standby状态,避免出现脑裂问题。
解决方案是确定Active关机的情况下重新hdfs zkfc -formatZK就可以了。
如何上述问题解决不了,可以删除掉zkfc在zookeeper保存hdfs高可用状态的目录并重启服务或者格式化zkfc即可。