版权声明:本文为原创文章,未经允许不得转载。
复习内容:
Spark中Job的提交 http://www.cnblogs.com/yourarebest/p/5342404.html
1.Spark中Job如何划分为Stage
我们在复习内容中介绍了Spark中Job的提交,下面我们看如何将Job划分为Stage。
对于JobSubmitted事件类型,通过 dagScheduler的handleJobSubmitted方法处理,方法源码如下:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[],
func: (TaskContext, Iterator[]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
//根据jobId生成新的Stage,详见1
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
...
Stage的提交及TaskSet(tasks)的提交
...
}
1.newResultStage方法如下, 根据jobId生成一个ResultStage
private def newResultStage(
rdd: RDD[],
func: (TaskContext, Iterator[]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
//根据jobid和rdd得到父Stages和StageId,详见2
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
//根据父Stages和StageId生成ResultStage,详见4
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
2.getParentStagesAndId方法如下所示:
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId),详见3
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
3.getParentStages方法如下所示:
private def getParentStages(rdd: RDD[], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[]]
//将要遍历的RDD放到栈Stack中
val waitingForVisit = new Stack[RDD[]]
def visit(r: RDD[]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
//判断rdd的依赖关系,如果是ShuffleDependency说明是宽依赖,详见4
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
//是窄依赖
case _ =>
//遍历rdd的父RDD是否有父Stage存在
waitingForVisit.push(dep.rdd)
} } } }
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
//调用visit方法访问出栈的RDD
visit(waitingForVisit.pop())
}
parents.toList
}
4.getShuffleMapStage方法如下所示:
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies,详见5
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
//根据firstJobId生成ShuffleMapStage,详见6
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
5.getAncestorShuffleDependencies方法如下:
private def getAncestorShuffleDependencies(rdd: RDD[]): Stack[ShuffleDependency[, , ]] = {
val parents = new Stack[ShuffleDependency[, , ]]
val visited = new HashSet[RDD[]]
val waitingForVisit = new Stack[RDD[]]
def visit(r: RDD[]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
waitingForVisit.push(dep.rdd)
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
6.newOrUsedShuffleStage方法如下所示,根据给定的RDD生成ShuffleMapStage,如果shuffleId对应的Stage已经存在与MapOutputTracker,那么number和位置输出的位置信息都可以从MapOutputTracker找到
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[_, _, ],
firstJobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
for (i <- 0 until locs.length) {
stage.outputLocs(i) = Option(locs(i)).toList // locs(i) will be null if missing
}
stage.numAvailableOutputs = locs.count( != null)
} else {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
2.Stage描述
一个Stage是一组并行的tasks;一个Stage可以被多个Job共享;一些Stage可能没有运行所有的RDD的分区,比如first 和 lookup;Stage的划分是通过是否存在Shuffle为边界来划分的,Stage的子类有两个:ResultStage和ShuffleMapStage
对于窄依赖生成的是ResultStage,对于宽依赖生成的是ShuffleMapStage。当ShuffleMapStages执行完后,产生输出文件,等待reduce task去获取,同时,ShffleMapStages也可以通过DAGScheduler的submitMapStage方法独立作为job被提交
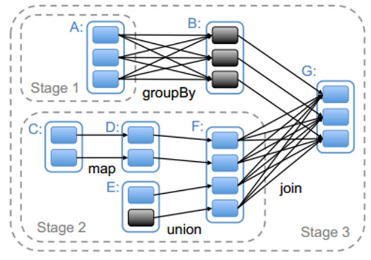
stage划分示意图
下一篇我们看Stage如何提交的。