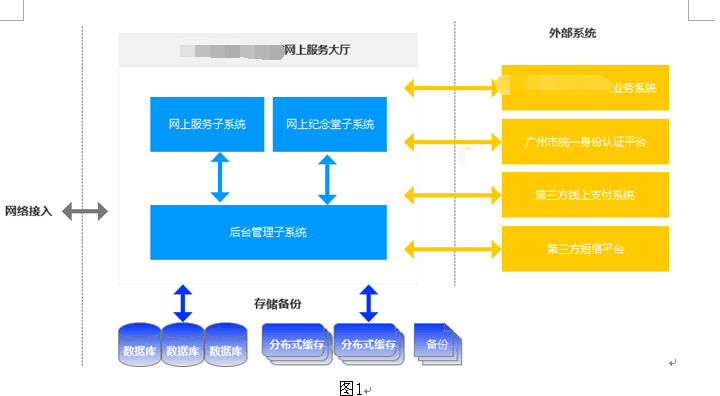
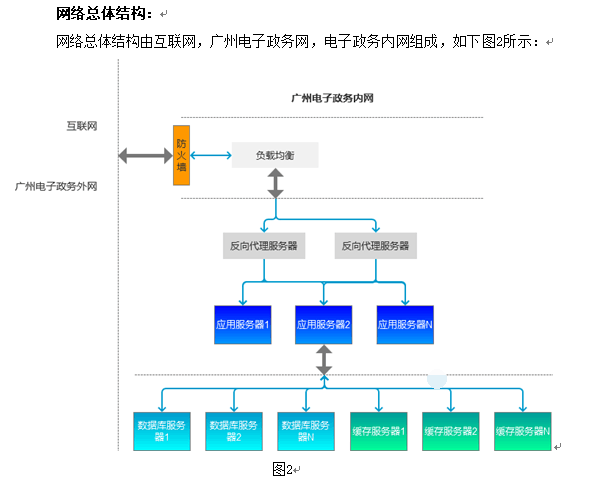
面试题:
1.Oracle,MySQL数据库,面试官基本都会问,大家要重视,有的会问有没有了解过mangodb。
2.存储过程
SQL语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
存储过程是可编程的函数,在数据库中创建并保存,可以由SQL语句和控制结构组成。
存储过程根据需要可能会有输入、输出、输入输出参数,共有三种参数类型,IN,OUT,INOUT
DELIMITER //
CREATE PROCEDURE in_param(IN p_in int)
BEGIN
SELECT p_in;
SET p_in=2;
SELECT p_in;
END;
//
DELIMITER ;
#调用
SET @p_in=1;
CALL in_param(@p_in);
SELECT @p_in;
执行结果:
3.Mysql连接数据库方式
1、 利用DriverManager连接数据库
2、 public static Connection getConnection() throws ClassNotFoundException{
3、 String url="jdbc:mysql:///jdbc";//我连的数据库是MySQL中的jdbc数据库
4、 String username="root";
5、 String password="";//我的MySQL数据库的密码是空字符串
6、 String driverClass="com.mysql.jdbc.Driver";
7、 Connection ct=null;
8、 Class.forName(driverClass);
9、 try {
10、 ct=DriverManager.getConnection(url, username, password);
11、 } catch (SQLException e) {
12、 e.printStackTrace();
13、 }
14、 return ct;
15、 }
2、利用io流读取文件的方式;
- // 读取类路径下的jdbc.propreties文件(配置文件)
- InputStream in = JDBCtool.class.getClassLoader().getResourceAsStream("jdbc.properties");
- // 以上为输入流
- Properties pt = new Properties();// 创建properties
- pt.load(in);// 取键值对(加载对应的输入流)
- driver = pt.getProperty("driver");
- jdbcurl = pt.getProperty("jdbcurl");
- user = pt.getProperty("user");
- password = pt.getProperty("password");
- 10. Connection ct = null;
将diver、jdbcurl、user、password这些信息存储到类路径下的jdbc.propreties文件中
3、利用c3p0连接池连接数据库
- <?xml version="1.0" encoding="UTF-8"?>
- <c3p0-config>
- <named-config name="helloc3p0">
- <!-- 连接数据源的基本属性 -->
- <property name="user">root</property>
- <property name="password"></property>
- <property name="driverClass">com.mysql.jdbc.Driver</property>
- <property name="jdbcUrl">jdbc:mysql:///jdbc</property>
10. <!-- 若数据库中连接数不足时,一次向数据库服务器申请多少个连接 -->
- 11. <property name="acquireIncrement">5</property>
12. <!-- 初始化数据库连接池时连接的数量 -->
- 13. <property name="initialPoolSize">5</property>
14. <!-- 数据库连接池中的最小的数据库连接数 -->
- 15. <property name="minPoolSize">5</property>
- 16. <!-- 数据库连接池中的最大的数据库连接数 -->
- 17. <property name="maxPoolSize">10</property>
18. <!-- c3p0数据库连接可以维护的statement的个数 -->
- 19. <property name="maxStatements">20</property>
20. <!-- 每个连接同时可以使用的statement对象的个数 -->
- 21. <property name="maxStatementsPerConnection">5</property>
- 22. </named-config>
23. </c3p0-config>
获取数据库连接的代码如下:
[java] view plain copy
- private static DataSource ds=null;
- //数据库连接池应只被初始化一次
- static{
- ds=new ComboPooledDataSource("helloc3p0");
- }
- //获取数据库连接
- public static Connection getConnection() throws ClassNotFoundException, SQLException, IOException{
- return ds.getConnection();
- 10.
- 11. }
4、利用mybatis-config.xml配置文件形式,利用MyBatis连接数据库
1配置文件:mybatis-config.xml
<configuration>
<environmentsdefault="environment">
<environmentid="environment">
<transactionManager type="JDBC"/>
<dataSourcetype="POOLED">
<propertyname="driver" value="com.mysql.jdbc.Driver" />
<propertyname="url"value="jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf8"/>
<property name="username" value="root" />
<propertyname="password" value="root" />
</dataSource>
</environment>
</environments>
</configuration>
2.源代码:
public class JDBCUtilsDemo5{
private static SqlSession session=null;
public static SqlSession getSession(){
try {
session= newSqlSessionFactoryBuilder().build(JDBCUtilsDemo5.class.getClassLoader().getResourceAsStream("mybatis-config.xml")).openSession();
关闭资源并在main方法中调用
4.左连接右链接内连接的区别
1、内联接(典型的联接运算,使用像
= 或 <> 之类的比较运算符)。包括相等联接和自然联接。
内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。例如,检索 students和courses表中学生标识号相同的所有行。
2、外联接。外联接可以是左向外联接、右向外联接或完整外部联接。
在 FROM子句中指定外联接时,可以由下列几组关键字中的一组指定:
1)LEFT JOIN或LEFT OUTER JOIN
左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
2)RIGHT JOIN 或 RIGHT OUTER JOIN
右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
3)FULL JOIN 或 FULL OUTER JOIN
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
例子:
-------------------------------------------------
a表 id name
b表
id job parent_id
1 张3
1 23 1
2 李四
2 34 2
3 王武
3 34
4
a.id同parent_id 存在关系
--------------------------------------------------
1) 内连接
select a.*,b.*
from a inner join
b on
a.id=b.parent_id
结果是
1 张3
1 23 1
2 李四
2 34 2
2)左连接
select a.*,b.*
from a left join
b on
a.id=b.parent_id
结果是
1 张3
1 23 1
2 李四
2 34 2
3 王武
null
3) 右连接
select a.*,b.*
from a right join
b on
a.id=b.parent_id
结果是
1 张3
1 23 1
2 李四
2 34 2
null
3 34 4
4) 完全连接
select a.*,b.*
from a full join
b on a.id=b.parent_id
结果是
1 张3
1 23 1
2 李四
2 34 2
null
3 34 4
3 王武
null
5.对各个框架的理解,基本原理
传统的Java Web应用程序是采用JSP+Servlet+Javabean来实现的,这种模式实现了最基本的MVC分层,使的程序结构分为几层,有负责前台展示的JSP、负责流程逻辑控制的Servlet以及负责数据封装的Javabean。但是这种结构仍然存在问题:如JSP页面中需要使用<%%>符号嵌入很多的Java代码,造成页面结构混乱,Servlet和Javabean负责了大量的跳转和运算工作,耦合紧密,程序复用度低等等;
Struts框架,它是一个完美的MVC实现,它有一个中央控制类(一个Servlet),针对不同的业务,我们需要一个Action类负责页面跳转和后台逻辑运算,一个或几个JSP页面负责数据的输入和输出显示,还有一个Form类负责传递Action和JSP中间的数据。JSP中可以使用Struts框架提供的一组标签,就像使用HTML标签一样简单,但是可以完成非常复杂的逻辑。从此JSP页面中不需要出现一行<%%>包围的Java代码了。
可是所有的运算逻辑都放在Struts的Action里将使得Action类复用度低和逻辑混乱,所以通常人们会把整个Web应用程序分为三层,Struts负责显示层,它调用业务层完成运算逻辑,业务层再调用持久层完成数据库的读写;
Hibernate框架,它需要你创建一系列的持久化类,每个类的属性都可以简单的看做和一张数据库表的属性一一对应,当然也可以实现关系数据库的各种表件关联的对应。当我们需要相关操作是,不用再关注数据库表。我们不用再去一行行的查询数据库,只需要持久化类就可以完成增删改查的功能。使我们的软件开发真正面向对象,而不是面向混乱的代码。我的感受是,使用Hibernate比JDBC方式减少了80%的编程量。
显示层的Struts需要调用一个业务类,就需要new一个业务类出来,然后使用;业务层需要调用持久层的类,也需要new一个持久层类出来用。通过这种new的方式互相调用就是软件开发中最糟糕设计的体现;
Spring的作用就是完全解耦类之间的依赖关系,一个类如果要依赖什么,那就是一个接口。至于如何实现这个接口,这都不重要了。只要拿到一个实现了这个接口的类,就可以轻松的通过xml配置文件把实现类注射到调用接口的那个类里。所有类之间的这种依赖关系就完全通过配置文件的方式替代了。所以Spring框架最核心的就是所谓的依赖注射和控制反转。
现在的结构是,Struts负责显示层,Hibernate负责持久层,Spring负责中间的业务层,这个结构是目前国内最流行的Java Web应用程序架构了。另外,由于Spring使用的依赖注射以及AOP(面向方面编程),所以它的这种内部模式非常优秀,以至于Spring自己也实现了一个使用依赖注射的MVC框架,叫做Spring MVC,同时为了很好的处理事物,Spring集成了Hibernate,使事物管理从Hibernate的持久层提升到了业务层,使用更加方便和强大。
SpringMVC原理:
Springmvc就是spring框架的一个模块,所以它可以和spring框架可以进行无缝整合,它是一个基于mvc设计思想的前端web框架,主要作用就是对前端请求进行处理。他的前端控制器是一个servlet.它的请求拦截是基于方法级别的.他的执行流程是
---》Spring的MVC框架主要由DispatcherServlet、处理器映射、处理器(控制器)、视图解析器、视图组成
1. 客户端请求提交到DispatcherServlet
2. 由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller
3. DispatcherServlet将请求提交到Controller
4. Controller调用业务逻辑处理后,返回ModelAndView
5. DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图
6. 视图负责将结果显示到客户端
mvc指的就是Model(业务模型)、View(视图)、Controller(控制器)
----》Mybatis是一个优秀的ORM框架.应用在持久层. 它对jdbc的 操作数据库过程 进行封装,使开发者只需要关注 SQL 本身,而不需要花费精力去处理例如注册驱动、创建connection、等jdbc繁杂的过程代码.一般使用mapper代理的方式开发.直接在xml里面写sql;
Mybatis的工作流程:
1、 mybatis配置
SqlMapConfig.xml,此文件作为mybatis的全局配置文件,配置了mybatis的运行环境等信息。
mapper.xml文件即sql映射文件,文件中配置了操作数据库的sql语句。此文件需要在SqlMapConfig.xml中加载。
2、 通过mybatis环境等配置信息构造SqlSessionFactory即会话工厂
3、 由会话工厂创建sqlSession即会话,操作数据库需要通过sqlSession(DefaultSqlSession)进行。
4、 mybatis底层自定义了Executor(BaseExecutor)执行器接口操作数据库,Executor接口有两个实现,一个是基本执行器、一个是缓存执行器。
5、 Mapped Statement也是mybatis一个底层封装对象,它包装了mybatis配置信息及sql映射信息等。mapper.xml文件中一个sql对应一个Mapped Statement对象,sql的id即是Mapped statement的id。
6、 Mapped Statement对sql执行输入参数进行定义,包括HashMap、基本类型、pojo,Executor通过 Mapped Statement在执行sql前将输入的java对象映射至sql中,输入参数映射就是jdbc编程中对preparedStatement设置参数。
7、 Mapped Statement对sql执行输出结果进行定义,包括HashMap、基本类型、pojo,Executor通过 Mapped Statement在执行sql后将输出结果映射至java对象中,输出结果映射过程相当于jdbc编程中对结果的解析处理过程。
6.对Aop,ioc的理解
(1)aop:面向切面编程,将跟业务逻辑没有关系的代码提取出来,在调用目标方法之前或者之后执行。常用的场景,事务,日志,权限控制,异常处理等方面。
(2)ioc:创建对象的权利,交给spring容器创建。
(3)di:如果一个对象A需要使用另一个对象B才能实现某个功能,这时就可以说A对象依赖于B对象,而Spring容器在创建A对象时,会自动将A对象需要的B对象注入到A对象中,此过程就是依赖注入。
核心容器:核心容器提供 Spring 框架的基本功能。核心容器的主要组件是 BeanFactory,它是工厂模式的实现。BeanFactory 使用控制反转 (IOC) 模式将应用程序的配置和依赖性规范与实际的应用程序代码分开。
7.对Session共享的理解
Java Servlet API引入session 机制来跟踪客户的状态,session指的是在一段时间内,单个客户和web服务器之间一连串的交互过程,在一个session中,一个客户可能会多次请求同一个网页,也可能请求多个不同服务器资源,例如:在一个邮件系统应用中,从一个客户登录到邮件系统,到写信,收信和发信等,到最后退出邮件系统,整个过程为一个session;再例如:大家在网上购物的时候,从购物到最后的付款,整个过程也是一个session 。
session对像是jsp中的内置对象,可以直接使用;在Servlet中使用session时,必须先创建出该对象,Servlet中创建session的方法:
HttpSession session=request.getSession();或 HttpSession session=request.getSession(boolean value);
在服务器上,通过session ID来区分每一个请求服务器的用户,用户只要一连接到服务器,服务器就会为之分配一个唯一的不会重复的session ID,session ID由服务器统一管理,人为不能控制。
session中的主要方法:sesson.setAttribute(String key,Object value);//将对象存到session中
session.getAttribute(String key);//获取session中存的Object对象
session.invalidate();方法,强制session死亡
8.高并发的处理
之前我将高并发的解决方法误认为是线程或者是队列可以解决,因为高并发的时候是有很多用户在访问,导致出现系统数据不正确、丢失数据现象,所以想到 的是用队列解决,其实队列解决的方式也可以处理,比如我们在竞拍商品、转发评论微博或者是秒杀商品等,同一时间访问量特别大,队列在此起到特别的作用,将 所有请求放入队列,以毫秒计时单位,有序的进行,从而不会出现数据丢失系统数据不正确的情况。
今天我经过查资料,高并发的解决方法有俩种,一种是使用缓存、另一种是使用生成静态页面;还有就是从最基础的地方优化我们写代码减少不必要的资源浪费:(
1.不要频繁的new对象,对于在整个应用中只需要存在一个实例的类使用单例模式.对于String的连接操作,使用StringBuffer或者StringBuilder.对于utility类型的类通过静态方法来访问。
2. 避免使用错误的方式,如Exception可以控制方法推出,但是Exception要保留stacktrace消耗性能,除非必要不要使用 instanceof做条件判断,尽量使用比的条件判断方式.使用JAVA中效率高的类,比如ArrayList比Vector性能好。)
首先缓存技术我一直没有使用过,我觉得应该是在用户请求时将数据保存在缓存中,下次请求时会检测缓存中是否有数据存在,防止多次请求服务器,导致服务器性能降低,严重导致服务器崩溃,这只是我自己的理解;
处理并发和同同步问题主要是通过锁机制。
我们需要明白,锁机制有两个层面。
一种是代码层次上的,如java中的同步锁,典型的就是同步关键字synchronized,这里我不在做过多的讲解,
另外一种是数据库层次上的,比较典型的就是悲观锁和乐观锁。这里我们重点讲解的就是悲观锁(传统的物理锁)和乐观锁。
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自 外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。一个典型的倚赖数据库的悲观锁调用:
select * from account where name=”Erica” for update
这条 sql 语句锁定了 account 表中所有符合检索条件( name=”Erica” )的记录。本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。
乐观锁,大多是基于数据版本 Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来 实现。 读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提 交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据 版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
尽量使用缓存,包括用户缓存,信息缓存等,多花点内存来做缓存,可以大量减少与数据库的交互,提高性能。
用jprofiler等工具找出性能瓶颈,减少额外的开销。
优化数据库查询语句,减少直接使用hibernate等工具的直接生成语句(仅耗时较长的查询做优化)。
优化数据库结构,多做索引,提高查询效率。
统计的功能尽量做缓存,或按每天一统计或定时统计相关报表,避免需要时进行统计的功能。
能使用静态页面的地方尽量使用,减少容器的解析(尽量将动态内容生成静态html来显示)。
9.Redis缓存的存储方式
RDB方式
RDB方式的持久化是通过快照的方式完成的。当符合某种规则时,会将内存中的数据全量生成一份副本存储到硬盘上,这个过程称作”快照”,Redis会在以下几种情况下对数据进行快照:
根据配置规则进行自动快照;用户执行SAVE, BGSAVE命令;执行FLUSHALL命令;执行复制(replication)时。
AOF方式
在使用Redis存储非临时数据时,一般都需要打开AOF持久化来降低进程终止导致的数据丢失,AOF可以将Redis执行的每一条写命令追加到硬盘文件中,这已过程显然会降低Redis的性能,但是大部分情况下这个影响是可以接受的,另外,使用较快的硬盘能提高AOF的性能。
10.多线程相关知识
11.Sturts2和SpringMVC比较
注意:说出几点即可
1、springmvc入口是一个servlet前端控制器,struts2入口是一个filter过虑器。
2、struts2通过在action类中定义成员变量接收请求参数,struts2只能使用多例模式管理action。
springmvc通过在controller方法中定义形参接收请求参数,springmvc可以使用单例模式管理controller。
3、springmvc是基于方法开发的,注解开发中使用requestMapping将url和方法进行映射,如果根据url找到controller类的方法生成一个Handler处理器对象(只包括一个method)。
struts2是基于类开发,每个请求过来创建一个action实例,实例对象中有若干的方法。
开发中建议使用springmvc,springmvc方法更类似service业务方法。
4、Struts采用值栈存储请求和响应的数据,通过OGNL存取数据, springmvc通过参数绑定器是将request请求内容解析,并给方法形参赋值。
12.Mybatis和hibernate比较
1. 在移植性方面hibernate配置一下方言即可.而一般情况下mybatis则需要修改sql语句
2. hibernate是一个完全的ORM框架.完全的面向对象.更符合我们开发者的思维模式.mybatis需要我们手动写sql语句
3. hibernate的优化成本比较高.因为hibernate的sql语句是自动生成的,所以在优化方面一般的新手无从下手.而mybatis只要修改sql就可以了.更加容易上手
(如果对某一个框架非常了解.这里话锋可以转向具体的详细介绍某一个框架)
13.如何用aop实现事务管理
事物特性:
1.原子性。
例如,转账,A账户减少,B账户增加。虽然是两条 DML语句,但是被当做是一个整体,一次事务。两条语句只能同时成功或者同时失败。
2.一致性。
账户A和B,要么都是转账前的状态,要么都是转账后的状态。(不能A账户的钱减少了但是B账户的钱没有增加)。
3.隔离性。
虽然在某个时间段很多人都在转账,但是每个人的转账都是在一个自己的事务中,彼此不会影响。
4.持久性。
事务提交成功后,数据修改永远生效。
(1)配置事务管理类
- <!-- 定义事务管理器 -->
- <bean id="transactionManager"
- class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
- <property name="dataSource" ref="dataSource" />
- </bean>
(2)配置事务属性
<!-- 配置事务的属性 -->
<tx:advice id="TestAdvice" transaction-manager="transactionManager">
<!--配置事务传播性,隔离级别以及超时回滚等问题 -->
<tx:attributes>
<tx:method name="search*" propagation="REQUIRED" read-only="true" isolation="DEFAUT" TIMEOUT="-1" />
<tx:method name="del*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="add*" propagation="REQUIRED" />
</tx:attributes>
</tx:advice>
(3)配置事务的AOP切入点
- <aop:config>
- <!--配置事务切点 -->
- <aop:pointcut id="services"
- expression="execution(public* com.pb.service.*.*(..))" />
- <aop:advisor pointcut-ref="services" advice-ref="TestAdvice" />
- </aop:config>
14.User表
写sql语句,查找表中名字相同的所有名字,还有数量
select u1.* from user u1
left join(select name,count(name) c from user
group by name
) t2 on t1.name=t2.name
where c>1
order by c desc
15.i++有几个步骤,是不是原子性操作
i++的操作分三步:
(1)栈中取出i
(2)i自增1
(3)将i存到栈
所以i++不是原子操作,上面的三个步骤中任何一个步骤同时操作,都可能导致i的值不正确自增.
16.在mapper.XML里面有大于号小于号的sql语句如何处理
1、因为这个是xml格式的,所以不允许出现类似“>”这样的字符,但是都可以使用<![CDATA[ ]]>符号进行说明,将此类符号不进行解析 :
mapper文件示例代码<![CDATA[ when min(starttime)<='12:00' and max(endtime)<='12:00' ]]>
2、用了转义字符把>和<替换掉SELECT * FROM test WHERE 1 = 1 AND start_date <= CURRENT_DATE AND end_date >= CURRENT_DATE
XML转义字符
|
< |
< |
小于号 |
|
> |
> |
大于号 |
|
& |
& |
和 |
|
' |
’ |
单引号 |
|
" |
" |
双引号 |
17.、关于负责均衡的理解
18.数据报表用什么方式实现
19.Excel导出如何实现
20.怎样用jQuery添加样式
对css样式操作的方法:
1、.css("样式"):获得样式值,比如$("input").css("color") 获得input中字体的颜色
2、.css("样式","value"):为样式赋值,如$("input").css("color","red");
3、.addClass("样式类1,样式类2,样式类3"):可以添加多个定义好的样式类
21.多表连接,给我一个订单表一个商品表,通过订单表关联商品,要是商品表里面商品已经删除了,如何连接查询这个订单信息(有高人事后跟我说这是个坑,商品表不能关联订单表查询,不合法,主要是试试你到底是不是真的在公司做过项目)
22.Oracle分页怎么写
23.jQuery选择器有哪些
一、基本选择器
基本选择器是jQuery中最常用也是最简单的选择器,它通过元素的id、class和标签名等来查找DOM元素。
1、ID选择器 #id
描述:根据给定的id匹配一个元素, 返回单个元素(注:在网页中,id名称不能重复)
示例:$("#test") 选取 id 为 test 的元素
2、类选择器 .class
描述:根据给定的类名匹配元素,返回元素集合
示例:$(".test") 选取所有class为test的元素
3、元素选择器 element
描述:根据给定的元素名匹配元素,返回元素集合
示例:$("p") 选取所有的<p>元素
4、*
描述:匹配所有元素,返回元素集合
示例:$("*") 选取所有的元素
高级选择器:交集、并集、后代、子元素、属性。。。。。
24.Jsp页面怎样引入一个类
<%@page import="com.ideal.dao.CommPayAppDao">
其中,类CommPayAppDao为代码src中包com/ideal/dao下面的dao类,这样你在jsp页面就可以像java类中写代码一样使用该类中的public方法。
25.Controller里面的数据通过什么方式返回到页面
Spring MVC返回数据到页面有几种不同的方式,它们各自适用的情况也不同,下面简单总结一下。
对于每种方式都给出Controller中的相应方法。
首先还是页面user_add.jsp。它既是发出请求的页面,也是接收返回结果的页面:
- <%@ page language="java" import="java.util.*" contentType="text/html;charset=utf-8"%>
- <html>
- <head>
- <title></title>
- </head>
- <body>
- <h1>添加用户信息4</h1>
- <form action="user/add4.do" method="post">
- <input type="submit" value="提交">
- </form>
- ${personId }
- </body>
- </html>
1、通过request对象:
- @RequestMapping("/add.do")
- public String add(HttpServletRequest request){
- request.setAttribute("personId",12);
- return "user_add";
- }
2、通过ModelAndView对象:
- @RequestMapping("/add.do")
- public ModelAndView add(){
- ModelAndView mav = new ModelAndView("user_add");
- mav.addObject("personId", 12);
- return mav;
- }
3、通过Model对象:
- @RequestMapping("/add.do")
- public String add(Model model){
- model.addAttribute("personId", 12);
- return "user_add";
- }
4、通过Map对象:
- @RequestMapping("/add.do")
- public String add(Map<String,Object> map){
- map.put("personId", 12);
- return "user_add";
- }
26.Mapper.XML里面要返回一个list集合怎么配,如果这个list集合里面是一个实体类对象又要怎么配
1、 直接写resultType="实体类",这样返回列表的话就自动变成了List<实体类>
2、 <resultMap type="HashMap" id="testMap">
<result column="UA_INFO" property="key" />
<association property="value" resultMap="com.xxx.xxx.BaseResultMap"></association>
</resultMap>
27.你们的项目数据库数据量最大的一张表数据量有多少
28.数据量大的表怎样提高查询效率