生存时间
设置命令
expire key long:设置数据在long秒后过期。
pexpire key long:设置数据在long毫秒后过期。
ttl key:查询数据剩余的生存时间。如果数据已过期被删除,返回-2(和版本有关),如果数据没有被设置过期时间,返回-1。
persist key:取消数据的生存时间,重新变成永久生存。
expireat key long:使用UNIX时间,设置数据存活到long时刻。long是从1980年8月1日开始到生存截止时间的秒数。
pexpireat key long:使用UNIX时间,设置数据存货到long时刻,long是从1980年8月1日开始到生存截止时间的毫秒数。
注意事项
(1)数据过期并不是表示一定会被立即删除
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。这会产生大量的性能消耗,同时也会影响数据的读取操作。
在Redis中,采用了定期删除和惰性删除的策略来防止用户获取过期了的数据。
- 定期删除:定期随机获取某些数据,检测它们是否已经过期,对过期数据进行删除。
- 惰性删除:用户查询某个数据前,检查它的生存时间是否已经过期,如果是,对它进行删除。
(2)Set和GetSet命令会清除过期时间
执行了Set和GetSet命令对key重新赋值,会同时清除掉它的生存时间。要注意目前只有这两个命令能清楚生存时间,其余的如hset、lpush等均不行。
删除策略
Redis的最大内存和删除策略都是在配置文件中进行配置。
配置参数
maxmemory:配置最大可用内存。
maxmemory-policy:配置达到最大内存后的删除策略。
maxmemory-samples:指定删除策略中随机取数的个数。
注意事项
(1)删除策略
volatile-lru:从设置了生存时间的数据中,找到使用最少的数据删除(LRU算法是找出使用时间最久远的数据)。
allkeys-lru:从所有数据中,找到使用最少的数据删除。
volatile-random:从设置生存时间的数据中,随机删除一个数据。
allkeys-random:从所有数据中,随机删除一个数据。
volatile-ttl:删除设置了生存时间中,ttl查询出来的时间最少的数据。
noeviction:不删除数据,返回错误。
(2)删除策略并不会全表扫描
和数据过期的情形一样,假如使用volatile-lru策略,按字面意思Redis需要遍历所有的数据,找出他们最后一次的使用时间,然后比较谁最久没有被使用,就删除它。但是实际这样操作会产生极为严重的性能消耗,降低Redis的读写性能。因此在删除策略中,Redis也是采用了随机数据的方式,每次随机取某些数据,在这些数据中执行LRU算法,RANDOM算法,或者是找出TTL时间最少的数据,而不会扫描全部数据。至于每次取多少数据,通过参数maxmemory-samples配置。
排序
排序其实只有一个命令SORT,但是在这个命令后面可以配置许多不同的参数来满足不同的情况需求。
详细命令
SORT KEY [BY 参考键] [ALPHA] [DESC|ASC] [LIMIT OFFSET COUNT] [GET 参考键] [STORE KEY]
命令说明
sort key:最简单的排序命令,可以使用在列表类型、集合类型和无序集合类型中,将数字类型的键值按照从小到大的顺序排列,键值是字符串将返回错误。
下面的命令都是建立在sort key的基础上的扩展。
- sort key alpha:新增可以对字符串的排序。
- sort key desc:排序顺序变为从大到小。
- sort key limit offset count:常用在分页上。排序后,按从左往右的顺序从下标为offset的元素开始返回,一共返回count个元素。
- sort key store key1:将返回结果保存在key1上。
- sort key by 参考键:依照参考键内容进行排序,排序结果仍返回key的键值。参考键可以是字符串类型和散列类型,必须带*,否则不会执行排序。
- sort key get 参考键:排序后返回参考键的键值,参考键可以是字符串类型和散列类型。
下面会进行相关的样例说明
样例1:创建一个列表类型list=[0 6 2 4 8 9 3 1],对它进行排序,排序结果[0 1 2 3 4 6 8 9]。
注意:这里只是对list的数据作有序返回,而并没有改变list里面元素的顺序。如果此时再通过lrange list 0 -1直接输出list的内容,将仍然是[0 6 2 4 8 9 3 1]

样例2:创建一个列表类型list=[b c e d a],先直接用sort对它排序,会返回一个错误,根据错误提示我们可以发现sort其实是将键值转为双精度浮点类型的数据来进行比较的。字符串类型需要添加参数alpha来进行标注,告诉redis这里是对字符串类型排序。

样例3:使用样例2的list,使用desc对它进行了倒序排序。
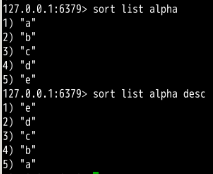
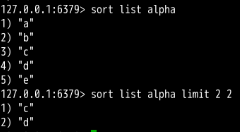
样例4:使用样例2的list,限制了返回值要从从下标为2的元素开始,连续取两个元素返回(Redis中的下标从左往右是从0开始,从右往左是从-1开始)。
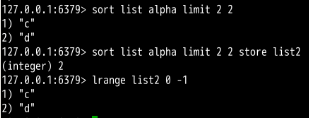
样例5:在样例4的基础上,使用store命令,将返回结果保存在list2中,查询list2的结果可以看到里面只有两个元素c和d
样例6:在样例2的list上,我们这里又创建了三个字符串类型数据s:a=3,s:b=5,s:c=-2。然后使用by 参考键来指定list的排序方式。
在这里有几个奇怪的地方:
- 返回的结果是字符串类型,但是我们没有使用alpha参数。
- 在不使用desc的情况下,默认是按从小到大的顺序排序,正常的应该是[a b c d e],但是实际返回的顺序是[c d e a b]
由于我们在这里使用了'by 参考键',因此它排序实际是依据s:*的键值来进行,因为我们list的键值是[a b c d e],用它们替代by s:*的通配符,分别对应[s:a s:b s:c s:d s:e],由于s:d和s:e并不存在,因此会使用0来作为他们的键值,因此取出来的数据是[3 5 -2 0 0],这些都是数字类型,因此并不需要使用alpha参数,同时对他们按从小到大的顺序排序[-2 0 0 3 5],分别对应[s:c s:d s:e s:a s:b],对应list的值就是[c d e a b],里面s:d和s:e都是0,当使用参考键的键值不能排序的时候,会再按照list里的键值进行排序,因此最终结果是[c d e a b]。

样例7:在样例6的基础上,我们使用'get 参考键'来获取数据,排序使用的是list的键值,因此排序结果是[a b c d e],然后匹配get后面的参考键s:*,可以匹配为[s:a s:b s:c s:d s:e],由于s:d和s:e不存在,因此返回nil。

注意事项
- by和get的参考键中没有*时,不会进行排序。
- by和get的参考键键值相等时,会在按照key的键值排序。
- 如果key的键值匹配by的参考键组成的键不存在,则默认键值为0。
- 在by和get的参考键中,*只能使用在字符串类型和散列类型的键上,不能使用在散列类型的域上。
- 由上一条引发出来的问题,如果将*使用在散列类型的域上,由于Redis检测参考键中有*,因此会进行排序,但是不会用key的键值替换*,因此只是按照key的键值进行的排序。
- get可以返回多个元素,以'get 参考键 get 参考键...'的形式排列,同时如果要返回*的内容,使用get #
排序时间复杂度
sort时间复杂度是O(n+mlogm),其中n是被排序数据的个数,m是返回结果的个数。
因此,如果要优化sort性能,只要考虑减小n和m的值即可。
- 尽可能减少待排序中元素的数量。
- 尽可能使用limit减少返回的元素数量。
- 尽可能得将返回结果使用store保存,而不是直接返回。