1. 说明
本文基于:spark-2.4.0-hadoop2.7-高可用(HA)安装部署
2. 启动Spark Shell
在任意一台有spark的机器上执行
1 # --master spark://mini02:7077 连接spark的master,这个master的状态为alive,而不是standby 2 # --total-executor-cores 2 总共占用2核CPU 3 # --executor-memory 512m 每个woker占用512m内存 4 [yun@mini03 ~]$ spark-shell --master spark://mini02:7077 --total-executor-cores 2 --executor-memory 512m 5 2018-11-25 12:07:39 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 6 Setting default log level to "WARN". 7 To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 8 Spark context Web UI available at http://mini03:4040 9 Spark context available as 'sc' (master = spark://mini02:7077, app id = app-20181125120746-0001). 10 Spark session available as 'spark'. 11 Welcome to 12 ____ __ 13 / __/__ ___ _____/ /__ 14 _ / _ / _ `/ __/ '_/ 15 /___/ .__/\_,_/_/ /_/\_ version 2.4.0 16 /_/ 17 18 Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112) 19 Type in expressions to have them evaluated. 20 Type :help for more information. 21 22 scala> sc 23 res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@77e1b84c
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
2.1. 相关截图
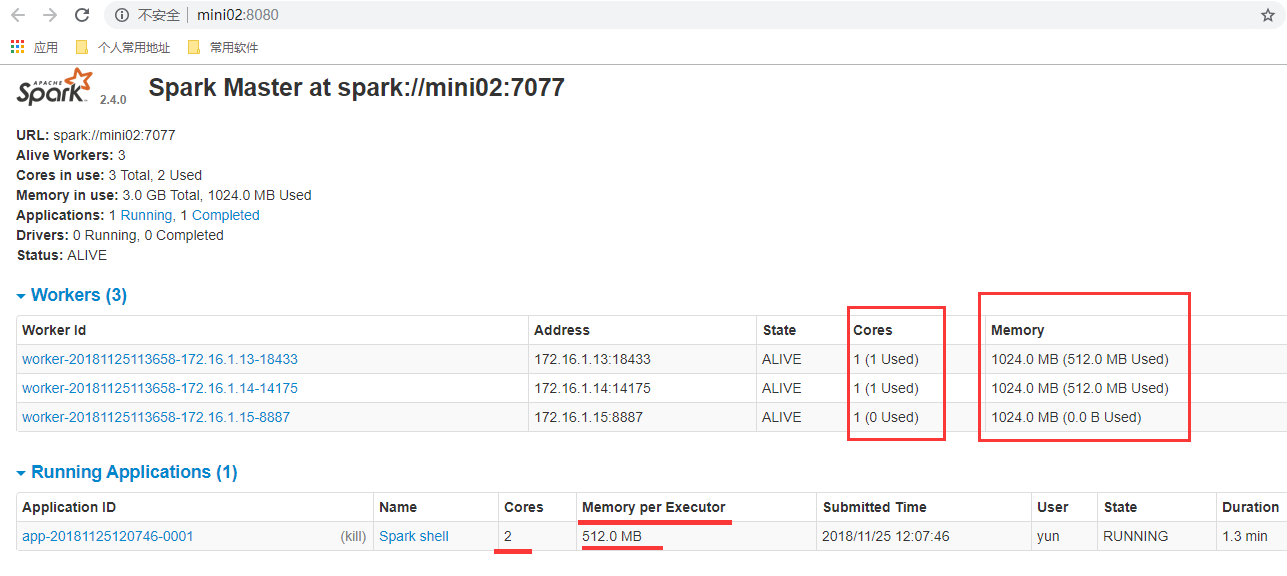
3. 执行第一个spark程序
该算法是利用蒙特•卡罗算法求PI
1 [yun@mini03 ~]$ spark-submit 2 --class org.apache.spark.examples.SparkPi 3 --master spark://mini02:7077 4 --total-executor-cores 2 5 --executor-memory 512m 6 /app/spark/examples/jars/spark-examples_2.11-2.4.0.jar 100 7 # 打印的信息如下: 8 2018-11-25 12:25:42 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 9 2018-11-25 12:25:43 INFO SparkContext:54 - Running Spark version 2.4.0 10 ……………… 11 2018-11-25 12:25:49 INFO TaskSetManager:54 - Finished task 97.0 in stage 0.0 (TID 97) in 20 ms on 172.16.1.14 (executor 0) (98/100) 12 2018-11-25 12:25:49 INFO TaskSetManager:54 - Finished task 98.0 in stage 0.0 (TID 98) in 26 ms on 172.16.1.13 (executor 1) (99/100) 13 2018-11-25 12:25:49 INFO TaskSetManager:54 - Finished task 99.0 in stage 0.0 (TID 99) in 25 ms on 172.16.1.14 (executor 0) (100/100) 14 2018-11-25 12:25:49 INFO TaskSchedulerImpl:54 - Removed TaskSet 0.0, whose tasks have all completed, from pool 15 2018-11-25 12:25:49 INFO DAGScheduler:54 - ResultStage 0 (reduce at SparkPi.scala:38) finished in 3.881 s 16 2018-11-25 12:25:49 INFO DAGScheduler:54 - Job 0 finished: reduce at SparkPi.scala:38, took 4.042591 s 17 Pi is roughly 3.1412699141269913 18 ………………
4. Spark shell求Word count 【结合Hadoop】
1、启动Hadoop
2、将文件放到Hadoop中
1 [yun@mini05 sparkwordcount]$ cat wc.info 2 zhang linux 3 linux tom 4 zhan kitty 5 tom linux 6 [yun@mini05 sparkwordcount]$ hdfs dfs -ls / 7 Found 4 items 8 drwxr-xr-x - yun supergroup 0 2018-11-16 11:36 /hbase 9 drwx------ - yun supergroup 0 2018-11-14 23:42 /tmp 10 drwxr-xr-x - yun supergroup 0 2018-11-14 23:42 /wordcount 11 -rw-r--r-- 3 yun supergroup 16402010 2018-11-14 23:39 /zookeeper-3.4.5.tar.gz 12 [yun@mini05 sparkwordcount]$ hdfs dfs -mkdir -p /sparkwordcount/input 13 [yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/1.info 14 [yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/2.info 15 [yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/3.info 16 [yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/4.info 17 [yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/input 18 Found 4 items 19 -rw-r--r-- 3 yun supergroup 45 2018-11-25 14:41 /sparkwordcount/input/1.info 20 -rw-r--r-- 3 yun supergroup 45 2018-11-25 14:41 /sparkwordcount/input/2.info 21 -rw-r--r-- 3 yun supergroup 45 2018-11-25 14:41 /sparkwordcount/input/3.info 22 -rw-r--r-- 3 yun supergroup 45 2018-11-25 14:41 /sparkwordcount/input/4.info
3、进入spark shell命令行,并计算
1 [yun@mini03 ~]$ spark-shell --master spark://mini02:7077 --total-executor-cores 2 --executor-memory 512m 2 # 计算完毕后,打印在命令行 3 scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).sortBy(_._2, false).collect 4 res6: Array[(String, Int)] = Array((linux,12), (tom,8), (kitty,4), (zhan,4), ("",4), (zhang,4)) 5 # 计算完毕后,保存在HDFS【因为有多个文件组成,则有多个reduce,所以输出有多个文件】 6 scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).sortBy(_._2, false).saveAsTextFile("hdfs://mini01:9000/sparkwordcount/output") 7 # 计算完毕后,保存在HDFS【将reduce设置为1,输出就只有一个文件】 8 scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_, 1).sortBy(_._2, false).saveAsTextFile("hdfs://mini01:9000/sparkwordcount/output1")
4、在HDFS的查看结算结果
1 [yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/ 2 Found 2 items 3 drwxr-xr-x - yun supergroup 0 2018-11-25 15:03 /sparkwordcount/input 4 drwxr-xr-x - yun supergroup 0 2018-11-25 15:05 /sparkwordcount/output 5 drwxr-xr-x - yun supergroup 0 2018-11-25 15:07 /sparkwordcount/output1 6 [yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/output 7 Found 5 items 8 -rw-r--r-- 3 yun supergroup 0 2018-11-25 15:05 /sparkwordcount/output/_SUCCESS 9 -rw-r--r-- 3 yun supergroup 0 2018-11-25 15:05 /sparkwordcount/output/part-00000 10 -rw-r--r-- 3 yun supergroup 11 2018-11-25 15:05 /sparkwordcount/output/part-00001 11 -rw-r--r-- 3 yun supergroup 8 2018-11-25 15:05 /sparkwordcount/output/part-00002 12 -rw-r--r-- 3 yun supergroup 34 2018-11-25 15:05 /sparkwordcount/output/part-00003 13 [yun@mini05 sparkwordcount]$ 14 [yun@mini05 sparkwordcount]$ hdfs dfs -cat /sparkwordcount/output/part* 15 (linux,12) 16 (tom,8) 17 (,4) 18 (zhang,4) 19 (kitty,4) 20 (zhan,4) 21 ############################################### 22 [yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/output1 23 Found 2 items 24 -rw-r--r-- 3 yun supergroup 0 2018-11-25 15:07 /sparkwordcount/output1/_SUCCESS 25 -rw-r--r-- 3 yun supergroup 53 2018-11-25 15:07 /sparkwordcount/output1/part-00000 26 [yun@mini05 sparkwordcount]$ hdfs dfs -cat /sparkwordcount/output1/part-00000 27 (linux,12) 28 (tom,8) 29 (,4) 30 (zhang,4) 31 (kitty,4) 32 (zhan,4)