1. Kafka简介
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
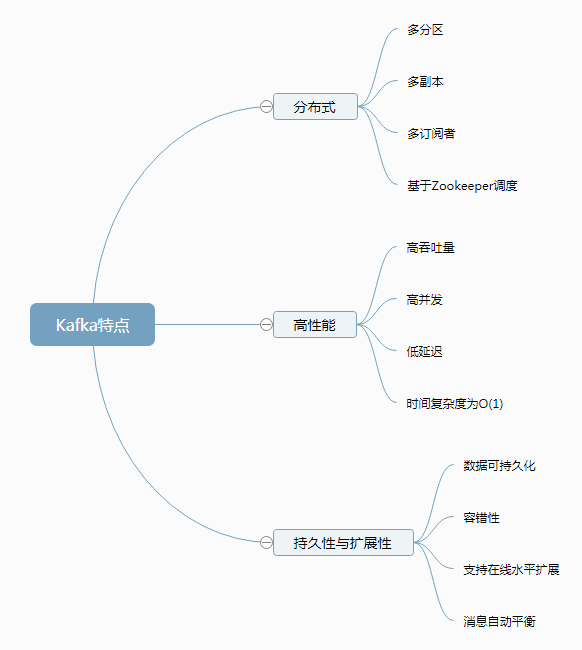
Kafka具有以下特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka的使用场景:
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
通过上面的介绍也可以看出:Kafka给自身的定位并不仅仅是一个消息系统,而是通过发布订阅消息机制实现的分布式流平台。
流平台有三个关键的能力:
- 发布订阅记录流,和消息队列或者企业新消息系统类似。
- 以可容错、持久的方式保存记录流
- 当记录流产生时就进行处理
Kafka通常用于应用中的两种广播类型:
- 在系统和应用间建立实时的数据管道,能够可信赖的获取数据。
- 建立实时的流应用,可以处理或者响应数据流。
2. Kafka基本概念及延伸
2.1 基本概念
Producer:数据生产者
- 消息和数据的生产者
- 向Kafka的一个topic发布消息的进程或代码或服务
Consumer:数据消费者
- 消息和数据的消费者
- 向Kafka订阅数据(topic)并且处理其发布的消息的进程或代码或服务
Consumer Group:消费者组
- 对于同一个topic,会广播给不同的Group
- 一个Group中,只有一个Consumer可以消费该消息
Broker:服务节点
- Kafka集群中的每个Kafka节点
Topic:主题
- Kafka消息的类别
- 对数据进行区分、隔离
Partition:分区
- Kafka中数据存储的基本单元
- 一个topic数据,会被分散存储到多个Partition
- 一个Partition只会存在一个Broker上
- 每个Partition是有序的
Replication:分区的副本
- 同一个Partition可能会有多个Replication
- 多个Replication之间数据是一样的
Replication Leader:副本的老大
- 一个Partition的多个Replication上
- 需要一个Leader负责该Partition上与Producer和Consumer交互
Replication Manager:副本的管理者
- 负责管理当前Broker所有分区和副本的信息
- 处理KafkaController发起的一些请求
- 副本状态的切换
- 添加、读取消息等
2.2 概念延伸
Partition:分区
- 每一个Topic被切分为多个Partition
- 消费者数目少于或等于Partition的数目
- Broker Group中的每一个Broker保存Topic的一个或多个Partition
- Consumer Group中的仅有一个Consumer读取Topic的一个或多个Partition,并且是惟一的Consumer
Replication:分区的副本
- 当集群中有Broker挂掉的情况,系统可以主动地使Replication提供服务
- 系统默认设置每一个Topic的Replication系数为1,可以在创建Topic时单独设置
- Replication的基本单位是Topic的Partition
- 所有的读和写都从Replication Leader进行,Replication Followers只是作为备份
- Replication Followers必须能够及时复制Replication Leader的数据
- 增加容错性与可扩展性
3. 基本结构
Kafka功能结构
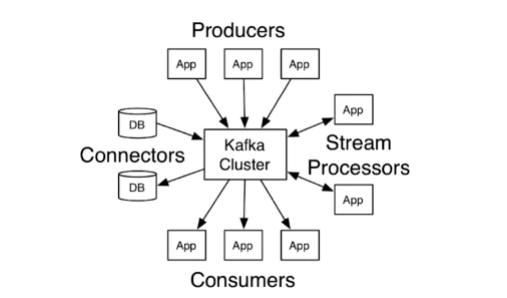
Kafka数据流势

Kafka消息结构

- Offset:当前消息所处于的偏移
- Length:消息的长度
- CRC32:校验字段,用于校验当前信息的完整性
- Magic:很多分布式系统都会设计该字段,固定的数字,用于快速判定当前信息是否为Kafka消息
- attributes:可选字段,消息的属性
- Timestamp:时间戳
- Key Length:Key的长度
- Key:Key
- Value Length:Value的长度
- Value:Value
4. Kafka安装部署
Kafka依赖于zookeeper实现分布式系统的协调,所以需要同时安装zookeeper。两个的安装包到官网下载。

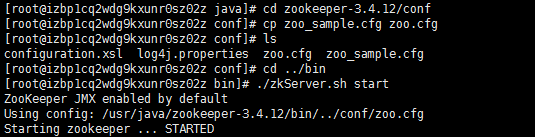
4.1 zookeeper安装配置
在zookeeper解压后的目录下找到conf文件夹,进入后,复制文件zoo_sample.cfg,并命名为zoo.cfg。zoo.cfg中一共五个配置项,可以使用默认配置。
4.2 Kafka安装配置
进入kafka根目录下的config文件夹下,打开server.properties,修改如下配置项(一般默认即为如下,无需修改)
zookeeper.connect=localhost:2181 broker.id=0 log.dirs=/tmp/kafka-logs
另外,config文件夹下也包含有zookeeper的配置文件,可以在其中设置配置项,启动zookeeper时引用这个配置文件,实现定制化。

Kafka的bin目录包含了大多数功能的启动脚本,可以通过它们控制Kafka的功能开启。

启动Kafka

4.3 使用控制台操作生产者和消费者
创建Topic:sudo ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic my-kafka-topic 查看Topic:sudo ./bin/kafka-topics.sh --list --zookeeper localhost:2181 启动生产者:sudo ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-kafka-topic 启动消费者:sudo ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-kafka-topic --from-beginning 生产消息:first message 生产消息:second message
5. 代码示例
引入依赖pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.zang</groupId> <artifactId>kafka</artifactId> <version>0.0.1-SNAPSHOT</version> <name>kafka</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.36</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
相应实体
package com.zang.kafka.common; import lombok.EqualsAndHashCode; import lombok.Getter; import lombok.Setter; import lombok.ToString; /** * 〈消息实体〉<br> */ @Getter @Setter @EqualsAndHashCode @ToString public class MessageEntity { /** * 标题 */ private String title; /** * 内容 */ private String body; }
package com.zang.kafka.common; import lombok.Getter; import lombok.Setter; import java.io.Serializable; /** * 〈REST请求统一响应对象〉<br> */ @Getter @Setter public class Response implements Serializable{ private static final long serialVersionUID = -1523637783561030117L; /** * 响应编码 */ private int code; /** * 响应消息 */ private String message; public Response(int code, String message) { this.code = code; this.message = message; } }
package com.zang.kafka.common; /** * 〈错误编码〉<br> */ public class ErrorCode { /** * 成功 */ public final static int SUCCESS = 200; /** * 失败 */ public final static int EXCEPTION = 500; }
生产者
package com.zang.kafka.producer; import com.alibaba.fastjson.JSON; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.support.SendResult; import org.springframework.stereotype.Component; import org.springframework.util.concurrent.ListenableFuture; import org.springframework.util.concurrent.ListenableFutureCallback; /** * 〈生产者〉 */ @Component public class SimpleProducer { private Logger logger = LoggerFactory.getLogger(getClass()); @Autowired private KafkaTemplate<String, Object> kafkaTemplate; public void send(String topic, String key, Object entity) { logger.info("发送消息入参:{}", entity); ProducerRecord<String, Object> record = new ProducerRecord<>( topic, key, JSON.toJSONString(entity) ); long startTime = System.currentTimeMillis(); ListenableFuture<SendResult<String, Object>> future = this.kafkaTemplate.send(record); future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() { @Override public void onFailure(Throwable ex) { logger.error("消息发送失败:{}", ex); } @Override public void onSuccess(SendResult<String, Object> result) { long elapsedTime = System.currentTimeMillis() - startTime; RecordMetadata metadata = result.getRecordMetadata(); StringBuilder record = new StringBuilder(128); record.append("message(") .append("key = ").append(key).append(",") .append("message = ").append(entity).append(")") .append("send to partition(").append(metadata.partition()).append(")") .append("with offset(").append(metadata.offset()).append(")") .append("in ").append(elapsedTime).append(" ms"); logger.info("消息发送成功:{}", record.toString()); } }); } }
消费者
package com.zang.kafka.consumer; import com.alibaba.fastjson.JSONObject; import com.zang.kafka.common.MessageEntity; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.support.KafkaHeaders; import org.springframework.messaging.handler.annotation.Header; import org.springframework.stereotype.Component; import java.util.Optional; /** * 〈消费者〉<br> */ @Component public class SimpleConsumer { private Logger logger = LoggerFactory.getLogger(getClass()); @KafkaListener(topics = "${kafka.topic.default}") public void listen(ConsumerRecord<?, ?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) { //判断是否NULL Optional<?> kafkaMessage = Optional.ofNullable(record.value()); if (kafkaMessage.isPresent()) { //获取消息 Object message = kafkaMessage.get(); MessageEntity messageEntity = JSONObject.parseObject(message.toString(), MessageEntity.class); logger.info("接收消息Topic:{}", topic); logger.info("接收消息Record:{}", record); logger.info("接收消息Message:{}", messageEntity); } } }
控制器
package com.zang.kafka.controller; import com.alibaba.fastjson.JSON; import com.zang.kafka.common.ErrorCode; import com.zang.kafka.common.MessageEntity; import com.zang.kafka.common.Response; import com.zang.kafka.producer.SimpleProducer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.*; /** * 〈生产者〉<br> */ @RestController @RequestMapping("/producer") public class ProducerController { private Logger logger = LoggerFactory.getLogger(getClass()); @Autowired private SimpleProducer simpleProducer; @Value("${kafka.topic.default}") private String topic; private static final String KEY = "key";/** * 消息发送 * @param message * @return */ @PostMapping("/send") public Response sendKafka(@RequestBody MessageEntity message) { try { logger.info("kafka的消息:{}", JSON.toJSONString(message)); this.simpleProducer.send(topic, KEY, message); logger.info("kafka消息发送成功!"); return new Response(ErrorCode.SUCCESS,"kafka消息发送成功"); } catch (Exception ex) { logger.error("kafka消息发送失败:", ex); return new Response(ErrorCode.EXCEPTION,"kafka消息发送失败"); } } }
配置application.properties
##----------kafka配置 ## TOPIC kafka.topic.default=my-kafka-topic # kafka地址 spring.kafka.bootstrap-servers=47.88.156.142:9092 # 生产者配置 spring.kafka.producer.retries=0 # 批量发送消息的数量 spring.kafka.producer.batch-size=4096 # 缓存容量 spring.kafka.producer.buffer-memory=40960 # 指定消息key和消息体的编解码方式 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer # 消费者配置 spring.kafka.consumer.group-id=my spring.kafka.consumer.auto-commit-interval=100 spring.kafka.consumer.auto-offset-reset=latest spring.kafka.consumer.enable-auto-commit=true # 指定消息key和消息体的编解码方式 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer # 指定listener 容器中的线程数,用于提高并发量 spring.kafka.listener.concurrency=3
启动类
package com.zang.kafka; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.EnableAutoConfiguration; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.kafka.annotation.EnableKafka; @SpringBootApplication @EnableKafka public class KafkaApplication { public static void main(String[] args) { SpringApplication.run(KafkaApplication.class, args); } }
6. Kafka的高级特性
6.1 消息事务
为什么要支持事务
- 满足“读取-处理-写入”模式
- 流处理需求的不断增强
- 不准确的数据处理的容忍度不断降低
数据传输的事务定义
- 最多一次:消息不会被重复发送,最多被传输一次,但也有可能一次不传输
- 最少一次:消息不会被漏发送,最少被传输一次,但也有可能被重复传输
- 精确的一次(Exactly once):不会漏传输也不会重复传输,每个消息都被传输一次且仅仅被传输一次,这是大家所期望的
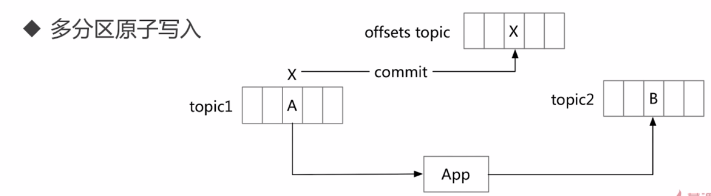
事务保证
- 内部重试问题:Procedure幂等处理
- 多分区原子写入
-
避免僵尸实例
- 每个事务Procedure分配一个 transactionl. id,在进程重新启动时能够识别相同的Procedure实例
- Kafka增加了一个与transactionl.id相关的epoch,存储每个transactionl.id内部元数据
- 一旦epoch被触发,任务具有相同的transactionl.id和更旧的epoch的Producer被视为僵尸,Kafka会拒绝来自这些Producer的后续事务性写入
6.2 零拷贝
零拷贝简介
- 通过网络传输持久性日志块
- 使用Java Nio channel.transforTo()方法实现
- 底层使用Linux sendfile系统调用
文件传输到网络的公共数据路径
- 第一次拷贝:操作系统将数据从磁盘读入到内核空间的页缓存
- 第二次拷贝:应用程序将数据从内核空间读入到用户空间缓存中
- 第三次拷贝:应用程序将数据写回到内核空间到socket缓存中
- 第四次拷贝:操作系统将数据从socket缓冲区复制到网卡缓冲区,以便将数据经网络发出
零拷贝过程(指内核空间和用户空间的交互拷贝次数为零)
- 第一次拷贝:操作系统将数据从磁盘读入到内核空间的页缓存
- 将数据的位置和长度的信息的描述符增加至内核空间(socket缓存区)
- 第二次拷贝:操作系统将数据从内核拷贝到网卡缓冲区,以便将数据经网络发出

来源:
慕课网课程:https://www.imooc.com/learn/1043
参考:
https://blog.csdn.net/liyiming2017/article/details/82790574
https://blog.csdn.net/YChenFeng/article/details/74980531