Apache Spark由于其出色的性能、简单的接口和丰富的分析和计算库而获得了广泛的行业应用。与大数据生态系统中的许多项目一样,Spark在Java虚拟机(JVM)上运行。因为Spark可以在内存中存储大量数据,因此它主要依赖于Java的内存管理和垃圾收集(GC)。但是现在,了解Java的GC选项和参数的用户可以调优他们的Spark应用程序的最佳性能。本文描述了如何为Spark配置JVM的垃圾收集器,并给出了实际的用例来解释如何调优GC,以提高Spark的性能。我们在调优GC时考虑关键因素,如收集吞吐量和延迟。
spark和GC的介绍:
随着Spark的广泛应用,Spark应用程序的稳定性和性能调优问题越来越成为人们关注的话题。由于Spark以内存为中心的方法,通常使用100GB或更多内存作为堆空间,这在传统的Java应用程序中很少见到。在与使用Spark的大公司合作时,我们收到了许多关于GC在执行Spark应用程序时所面临的各种挑战的担忧。例如,垃圾收集需要很长的时间,导致程序经历长时间的延迟,甚至在严重的情况下崩溃。在本文中,我们使用真实的例子,结合具体的问题,讨论可以缓解这些问题的Spark应用程序的GC调优方法。
Java应用程序通常使用这两种GC策略 : 并发标记清理(Concurrent Mark Sweep garbage collection简称CMS)垃圾收集和并行垃圾收集(ParallelOld garbage collection)。前者旨在降低延迟,而后者则是针对更高的吞吐量。这两种策略都有性能瓶颈:CMS GC不执行压缩,而并行GC只执行全堆压缩,这会导致相当大的停顿时间。我们建议客户按照应用的实际需求选择不同的策略。对于需要实时响应的应用,推荐CMS GC;对于离线分析的应用,推荐使用并行GC。
那么,对于像Spark这样支持流计算和传统批处理的计算框架,我们能找到一个最佳的GC收集器吗?Hotspot JVM1.6 版本引入了垃圾收集的第三个策略:The Garbage-First GC (简称G1 GC)。G1收集器由Oracle计划,作为CMS GC的长期替代品。最重要的是,G1收集器的目标是实现高吞吐量和低延迟的双特点。在详细介绍使用Spark的G1收集器之前,让我们先讨论一下Java GC基础的一些背景知识。
JVM GC工作流程:
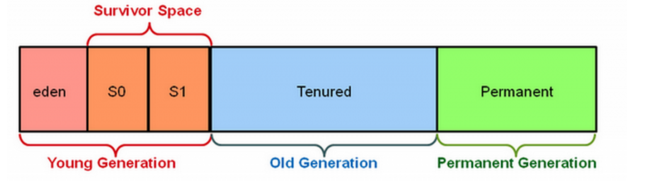
Spark的内存管理介绍
弹性分布数据集(RDD)是Spark的核心抽象。RDD的创建和缓存与内存消耗密切相关。Spark允许用户将数据进行缓存以便在应用程序中重用,从而避免重复计算造成的开销。持久化的数据自然是存放在JVM中的。Spark的executor将JVM堆空间划分为两个部分:一部分用于存放持久化的数据(storeage),另一部分用作RDD转换期间的内存消耗(shuffle)。我们可以使用spark.storage来调整这两个部分的比例(1.6版本之前)
当发现由GC延迟引起的效率下降时,我们应该首先检查并确保Spark应用程序是否以有效的方式使用有限的内存空间。内存空间RDD占用的空间越小,程序执行的堆空间就越多,从而可以提高GC效率;相反,RDDs的过度内存消耗导致了老年代大量的缓冲对象导致的性能损失。在这里,我们用一个例子来介绍这一点:
例如,有一个Spark应用程序,它执行简单的迭代计算。反复迭代计算,每步迭代的结果都会被持久化到内存空间中。在程序执行过程中,我们观察到当迭代次数增加时,进程所使用的内存空间会快速增长,从而导致GC变得更糟。当我们仔细研究时,我们发现它会在内存中缓存每一个RDD,而且不会随着时间的推移而释放它们,哪怕它们在下一次迭代之后不会被使用。那么这将导致内存消耗增长,从而引发更多GC尝试。我们在SPARK-2661中删除了这种不必要的缓存。在此修改缓存后,RDD大小在三个迭代和缓存空间被有效控制后稳定(如表1所示)。结果,GC效率大大提高,程序的总运行时间缩短了10%~20%。
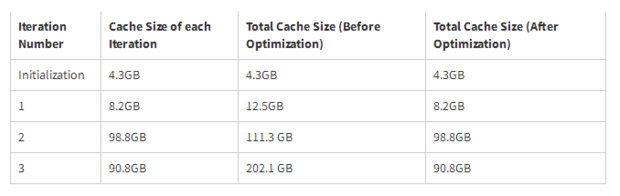
结论:
当GC时间很长时,它可能表明内存空间没有被Spark应用程序有效地使用。您可以通过显式地清理缓存后的RDD,从而提高性能。
怎么选择合适的GC策略
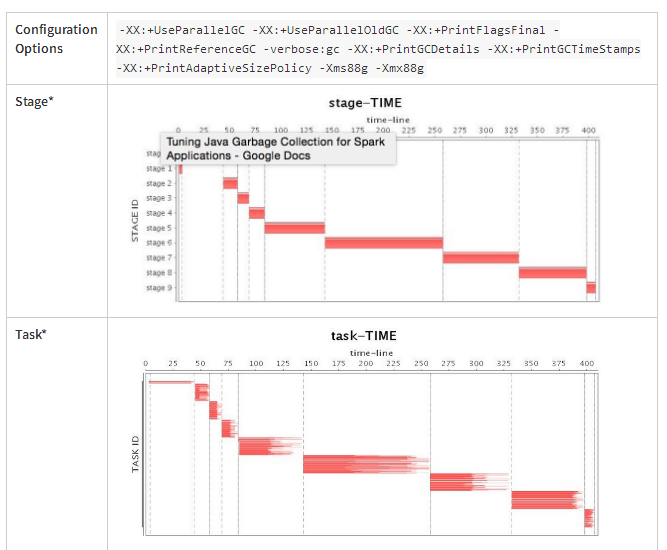
如果我们的应用程序已经可以高效地使用内存,那么下一步就是选择使用哪种GC策略以及如何进行GC调优了。在这里我们启用了一个四节点集群,给每个executor分配了88GB的堆内存,并以standalone模式启动Spark来进行我们的实验。最初我们使用默认的Spark Parallel GC,发现因为spark应用程序的内存开销比较大,大多数的对象不能在一个相当短的生命周期被回收,Parallel GC经常出现Full GC。更糟糕的是,Parallel GC提供了非常有限的性能调优选项,因此我们只能使用一些基本参数来调整性能,比如每一代的大小比例,以及在对象被提升到老年代之前的副本数量。但是这些调优策略也只是推迟了Full GC,所以并行GC调优对长时间运行的应用程序没有帮助。因此,在本文中,我们不进行 Parallel GC调优。表2显示了Parallel GC的操作,很明显,当发生FULL GC时,CPU利用率最低。
Table 2: Parallel GC Running Status (Before Tuning)
CMS GC对于Spark应用中FULL GC的调优选择同样少之又少。此外,CMS GC FULL GC暂停时间比Parallel GC还要长,大大降低了应用程序的吞吐量。
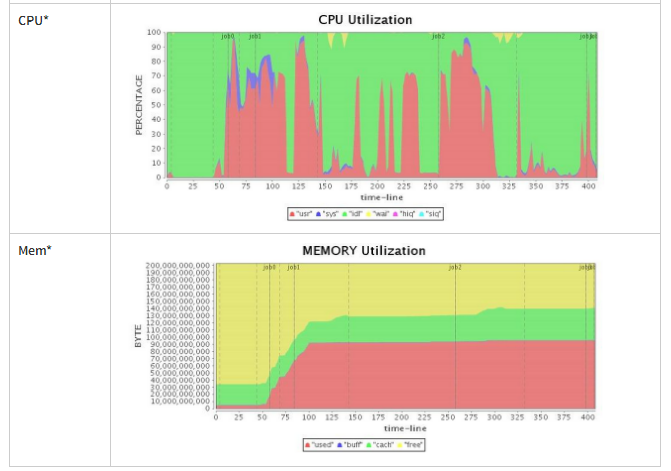
接下来,我们使用G1 GC策略(默认配置)运行我们的应用程序。令我们惊讶的是,G1 GC也提供了让人难以接受的FULL GC(请参阅图3中的“CPU利用率”,显然作业3暂停了将近100秒),一个长时间的暂停显著地拖了整个应用程序的运行。如表4所示,虽然总运行时间略长于Parallel GC,但G1 GC的性能略优于CMS GC。
Table 3: G1 GC Running Status (Before Tuning)

三种GC策略下,spark应用消耗的时间(均使用默认参数,未做任何优化)
Table 4 Comparison of Three Garbage Collectors’ Program Running Time (88GB Heap before tuning)

基于输出的日志对G1 GC进行优化
首先,我们希望JVM能够在日志中记录更多的GC细节。对于Spark,我们可以通过spark.executor.extraJavaOptions设置一些关于JVM的参数。比如:
-XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark
定义了这些参数以后,我们可以详细的跟踪GC的日志记录(output to $SPARK_HOME/work/$ app_id/$executor_id/stdout at each worker node)接下来,我们可以根据GC日志分析问题的根源,并学习如何提高程序性能。
G1 GC日志的结构(具体见原文)

从日志中我们可以看到G1 GC日志有一个非常清晰的层次结构。日志列出了暂停发生的时间和原因,以及不同线程的时间消耗、及CPU时间的最大值和平均值。最后,G1 GC在暂停之后列出清理结果,以及总时间消耗。
在当前G1 GC运行日志中,我们发现了这样一个特殊的块:(具体见原文)
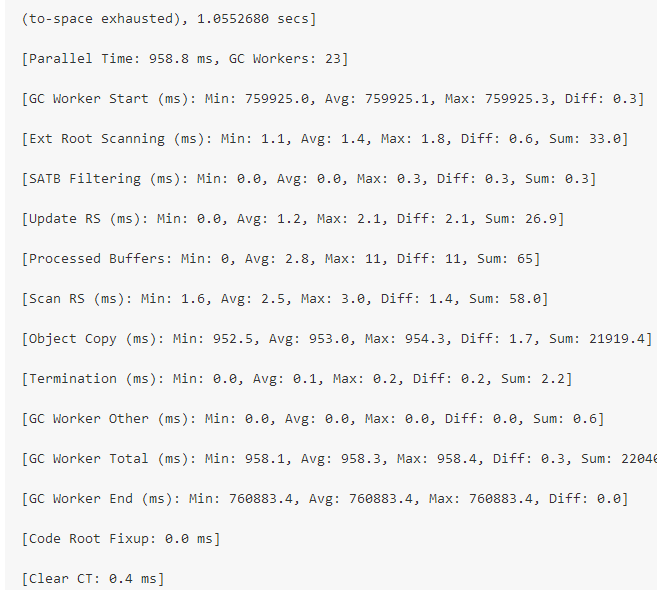
我们可以看到,最大的性能下降是由FULL GC引起的,并且在日志输出的结果中显示内存耗尽,内存溢出等等(对于不同的JVM版本日志显示略有不同)。而这个原因是G1 GC收集器试图给某些区域进行垃圾回收时,它没有找到可以复制活动对象的自由区域(在GC时,不被引用的对象会被回收掉,还处于引用的对象会被转存到另外一个区域),这种情况称为“疏散失败”,并且将导致FULL GC发生。显然,G1 GC中的FULL GC比Parallel GC更糟糕,因此我们必须尽量避免GC,以获得更好的性能。为了避免G1 GC的FULL GC,有两种常用的方法:
一:减小initiatingheapancypercent选项的值(默认值是45),让G1 GC可以较早的启动初始并发标记,这样可以很大概率避免FULL GC的发生。
二:增加ConcGCThreads选项的值,为并发标记提供更多的线程,这样我们就可以加速并发标记阶段。需要注意的是,这个选项也会占用一些工作线程资源,这取决于你实际有多少CPU以及CPU的利用率。
对这两个选项进行调优,可以尽可能的避免FULL GC的发生。FULL GC被限制后,性能得到显著提高。但是,我们仍然在GC期间发现了长时间的暂停。在进一步的调查中,我们发现在我们的日志中有以下事件:
280.008: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: occupancy higher than threshold, occupancy: 62344134656 bytes, allocation request: 46137368 bytes, threshold: 42520176225 bytes (45.00 %), source: concurrent humongous allocation]
在这里我们可以看到一些极大的对象(这些对象的大小是标准区域的50%甚至更大)。G1 GC会将这些对象放到相邻的区域集合中。由于复制这些对象会消耗大量的资源,所以这些对象会被直接分配到老年代,然后将其分类为巨大的区域。在jdk 1.8.0_u40之前,需要一个完整的堆分析来回收这些巨大的区域[JDK-8027959]。如果有许多这样的对象,堆将很快被填满,并且回收它们的代价太大。即使后来官方有了修复,但连续区域的分配仍然很昂贵(特别是在遇到严重堆碎片时),因此我们希望避免创建这种大小的对象。我们可以增加 g1heapregions 大小的值,以减少创建巨大区域的可能性,但是如果我们使用相对较大的堆,32M已经是它的最大值了。这意味着我们只能分析程序来找到这些对象并减少它们的创建。否则,它可能会导致更多的并发标记阶段,在此之后,您需要仔细地调整混合GC相关的knobs(e.g., -XX:G1HeapWastePercent -XX:G1MixedGCLiveThresholdPercent),以避免长期混合GC暂停(由大量巨大的对象引起)。
接下来,我们可以分析从单个GC不断循环的开始一直到混合GC的结束这段时间的间隔。如果时间太长,可以考虑增加ConcGCThreads的值,但是注意这将占用更多的CPU资源。
G1 GC也有减少STW暂停长度的方法,以在垃圾收集的并发阶段做更多的工作。如上所述,G1 GC为每个区域维护一个Remembered Set(简称RSet),以跟踪外部区域对给定区域的对象引用,G1收集器将在STW阶段和并发阶段更新RSet。如果您想要减少G1 GC暂停的时间,您可以降低G1RSetUpdatingPauseTimePercent的值,同时增加G1ConcRefinementThreads的值。前者用于指定总STW时间内rset更新时间的期望比率,默认值为10%,而后者用于定义在程序运行期间维护rset的线程数。有了这两个选项,我们可以将更多的rset的工作负载从STW阶段转移到并发阶段。
此外,对于长时间运行的应用程序,我们使用AlwaysPreTouch 选项,因此JVM在启动时应用了OS所需要的所有内存,并避免了动态应用程序。这提高了运行时性能,以延长启动时间。
最终,经过几轮GC参数调整后,我们到达了表5中的结果。与之前的结果相比,我们最终获得了更令人满意的运行效率。
Table 5 G1 GC Running Status (after Tuning)
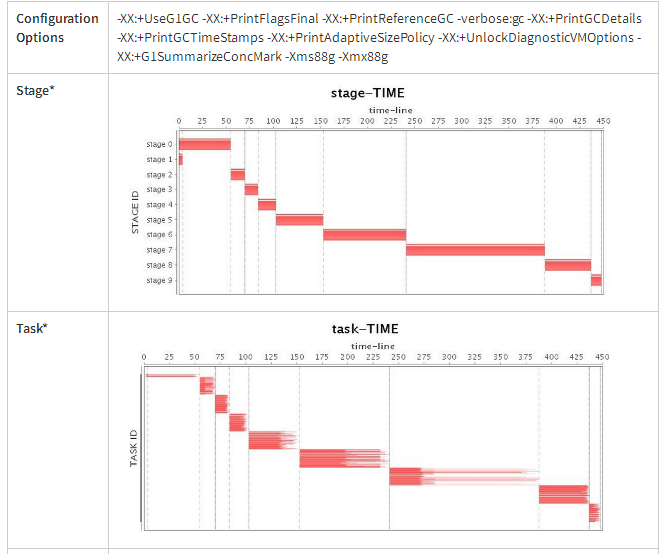
Configuration Options:
-Xms88g -Xmx88g
-XX:+UseG1GC
-XX:+UnlockDiagnosticVMOptions
-XX:+G1SummarizeConcMark
-XX:InitiatingHeapOccupancyPercent=35
-XX:ConcGCThread=20
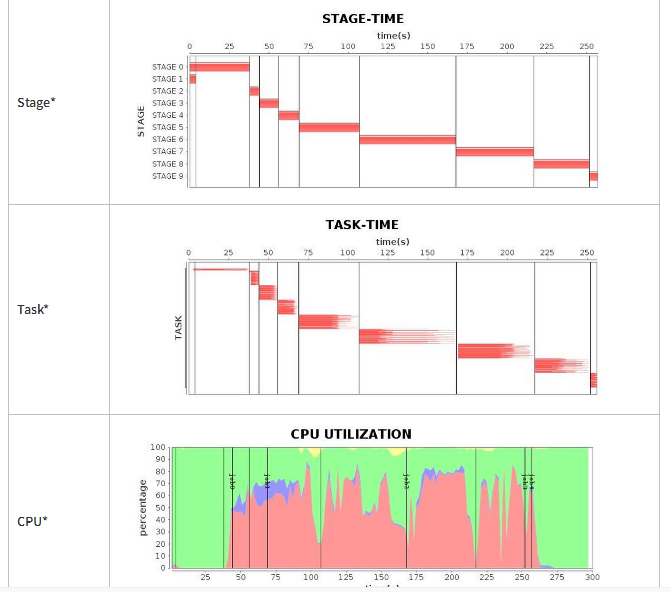
通过GC日志分析可以获得细粒度的优化。调优后,我们成功地将应用程序的运行时间缩短到4.3分钟。与调优前的运行时间相比,性能提高了1.7倍;与Parallel GC相比,性能提升了差不多1.5倍。
总结
对于严重依赖内存计算的Spark应用程序来说,GC调优尤为重要。当GC出现问题时,不要急于调试GC本身。首先考虑Spark程序的内存管理是否低效,比如持久化和释放缓存中的RDD。在进行GC调优时,我们首先建议使用G1 GC来运行Spark应用程序。G1 GC可以很好地处理不断增长的堆大小。对于G1,需要更少的选项来提供更高的吞吐量和更低的延迟。当然,GC调优没有固定模式。各种应用程序具有不同的特性,为了解决不可预测的情况,必须根据日志和其他取证来掌握GC调优的技术。最后,我们不要忘记通过程序的逻辑和代码进行优化,比如减少中间对象的创建或复制,控制大型对象的创建,将长时间的对象存储在堆外,等等。
通过使用G1 GC,我们在Spark应用程序中取得了重大的性能改进。Spark未来的工作将把内存管理责任从Java的垃圾收集器转移到Spark本身。这将大大减少Spark应用程序的调优需求。但是现在来说,GC策略的选择和调优依旧是提高Sparkd应用性能的关键。
原文:
https://databricks.com/blog/2015/05/28/tuning-java-garbage-collection-for-spark-applications.html?from=timeline