在上一篇文章《使用 ML.NET 识别乐高颜色块》,我们使用C#和 ML.NET 写了一个程序来训练ML模型,以识别乐高色块。在这篇文章中,我们将看看如何评估分类器的准确性,并修改分类器的可用参数,看看如何改进它。
机器学习有意思的地方在于使计算机可以学习做一些颇具想像力的事情,同时它有一个问题——我们不知道算法是如何工作的,最重要的是它何时能工作。正因如此,创建ML模型时我们需要对结果进行评测,并且只有在我们认为它足够好(这完全取决于应用程序)时才正式使用它。以下是一些用于评估ML模型的指标的基本内容:
Accuracy:测量分类器做出正确预测的比率。在多分类问题中,它被称为 micro-accuracy,并计算所有类的正样本预测。
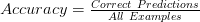
Per-Class Accuracy:在多分类场景中,每个类的精度可能不同,因此我们可以计算每个类的准确性。计算与Accuracy相同,但使用单个类实例。它也被称为 macro-Accuracy。
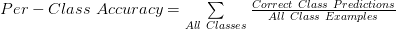
Log-Loss:使用复杂的信息理论方程来测量分类器的置信度,我不会在这里写这个方程。。重要的是要知道 og-loss 越低越好,最低值为0,以获得完美的准确度。
Log-Loss Reduction:一种可以解释为分类器比随机预测更好的测量值。它的范围从负无穷大到 1, 其中 1 是完美的预测, 0 是平均预测。我不知道负值(或平均预测)是什么意思,但总的来说更接近正数的那一个越好。
那么,我们实际上是如何做到这一点的呢? 当然是使用内置的函数在交叉验证时进行模型评估。在交叉验证中,输入的训练集被分为多个子集,然后神经网络将接受示例的训练,并与那些数据集一起进行评估。这样做是因为我们评估的不是一个特定的模型,而是神经网络的架构和用于创建模型的超参。什么是超参?超参是控制神经网络学习过程的参数。超参的一个例子是为训练模型而完成的迭代数。每个机器学习算法/框架都有不同的超参。
让我们来看看在示例中是什么样子:
static void Evaluate(MLContext mlContext, IDataView trainingDataView, IEstimator<ITransformer> trainingPipeline) { Console.WriteLine("=============== Cross-validating to get model's accuracy metrics ==============="); var crossValidationResults = mlContext.MulticlassClassification.CrossValidate(trainingDataView, trainingPipeline, numberOfFolds: 5, labelColumnName: "Label"); PrintMulticlassClassificationFoldsAverageMetrics(crossValidationResults); }
此交叉验证的结果是交叉验证结果列表,其中每个结果包含该数据集评估的指标。通过平均所有数据集上的指标,我们可以很好地了解我们的ML训练器和模型将如何进行的。
现在,我们可以测试对超参的修改,看看我们是否可以得到一个模型,可以正确识别我们的乐高样品。这是示范传递给ML训练器的参数而编写的实例。为了保持简单,我们将只修改其中两个:架构和迭代数。架构超参值定义了训练器使用哪个基础神经网络架构。做图像分类是一个很难解决的问题,需要很多时间,并且已经有非常复杂的神经网络模型,可以识别形状,轮廓甚至猫等。ML.NET 所做的是将现有的模型之一作为我们神经网络的起点,并从那里用我们的例子来训练它。这称为转移学习。ML.NET 有4种不同的架构。更改非常简单:
ImageClassificationTrainer.Options
var trainer = mlContext.MulticlassClassification.Trainers.ImageClassification( new ImageClassificationTrainer.Options() { Arch = architecture, Epoch = epoch, FeatureColumnName = "Features", LabelColumnName = "Label", }) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
为了了解这些超参如何影响分类器,我们现在使用所有可用的架构运行评估,以及 50、100、200 和 400 的迭代值(默认值为 200)。结果如下表所示。

正如你所看到的,MobilenetV2胜过其他算法。更有趣的是,少跑一些训练迭代,就产生了更好的分类器效果。这不是我所期望的,而且由于训练量相对较小,因此没有可以从中吸取的一般结论。
最后,在我们的测试集上使用 MobilnetV2 运行分类器为我们提供了正确的结果:
Testing with black piece. Prediction: Black.
Testing with blue piece. Prediction: Blue.
Testing with green piece. Prediction: Green.
Testing with yellow piece. Prediction: Yellow.
本示例文件的完整代码可以在 [https://github.com/BeanHsiang/Vainosamples/tree/master/CSharp/ML/LegoColorIdentifier2] 上找到。
引用: