一.KNN算法介绍
近朱者赤,近墨者黑
k近邻(K-Nearest Neighbor,简称KNN)学习是一种常用的监督学习算法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。
思考点:1.是一种监督学习算法,常用作处理分类问题,但也可用于处理回归问题
2.基于某种距离度量,这里的距离有很多种,具体使用时怎么确定使用哪一种距离?
最常用的是欧式距离,即普遍意义中空间里两点的直线距离:

3.KNN中K的含义是寻找的最近邻居的数量,是一个超参数,如何确定?
4.怎么高效率,低成本找出最近的K个样本?
5.不同属性对距离的贡献权重
5.1 由于不同属性往往有不同的取值空间,所以会对距离计算产生不同的贡献权重,此时可以对数据进行归一化,但归一化方法也有多种,如何选择?
5.2 每个属性对距离的贡献权重都一样吗?如何确定每个属性的最优权重?
6.距离不同的邻居对最终结果的贡献权重
最近的邻居和第K个近的邻居对最终结果的贡献权重一样吗?如何确定不同距离邻居的贡献权重?
二.KNN算法的特点
1. 原理非常简单,易于理解
2. 训练时间为零,只是把样本保存起来,没有显示训练过程,是一种典型的懒惰学习(lazy learning),基于实例的学习
3. 特别适合多分类问题(multi-model,对象具有多个类别标签),KNN比SVM的表现要好
4. 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
5. 计算量巨大,时间复杂度高,空间复杂度高
6. 样本不平衡时,对稀有类别的预测准确率低
7. 非常依赖训练数据的准确性
三.KNN算法的代码实现
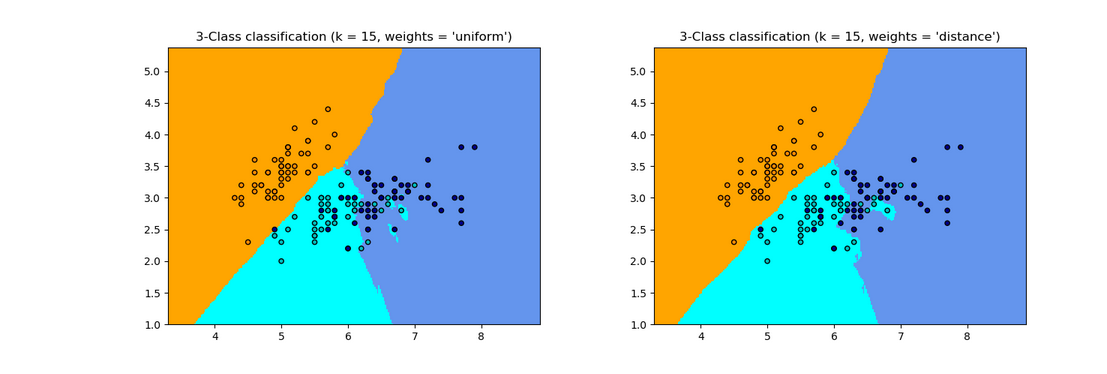
1.分类
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
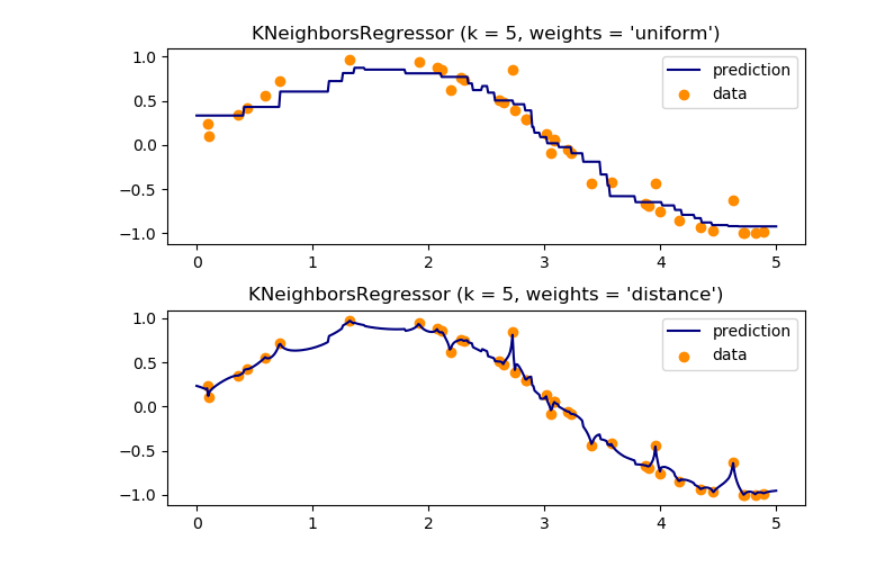
2.回归
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
3.重要参数解释
1. n_neighbors(default = 5) : K值
2. weights(default = uniform) : 权重,通常有三种方式:
2.1 ‘uniform’ 众生平等
2.2 ‘distance’ 距离与权重成反比
2.3 自定义
3. algorithm(default = auto) : 寻找最近K个样本的算法
3.1 ‘brute’: 暴力搜索
3.2 'kd_tree': KD树
3.3 ‘ball_tree’ : 球树
3.4 ‘auto’ 自动选择合适的算法