mysql判断sql语句是不是慢查询,是根据语句的执行时间来衡量的,mysql会用语句的执行时间和long_query_time这个系统参数做比较,如果语句执行时间大于long_query_time,都会把这个语句记录到慢查询日志里面。long_query_time的默认值是10s,一般生产环境不会设置这么大的值,一般设置1秒。
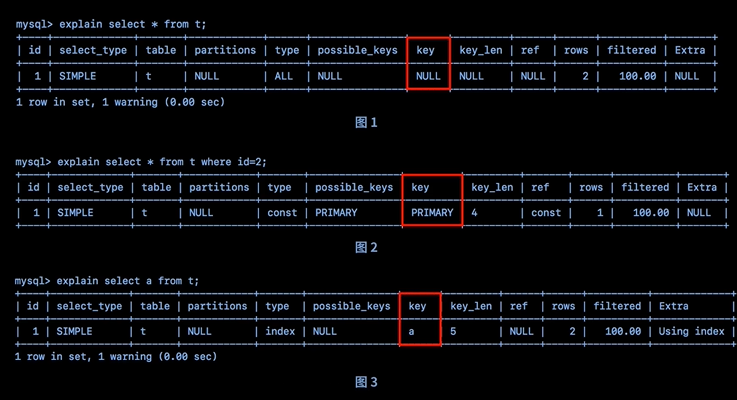
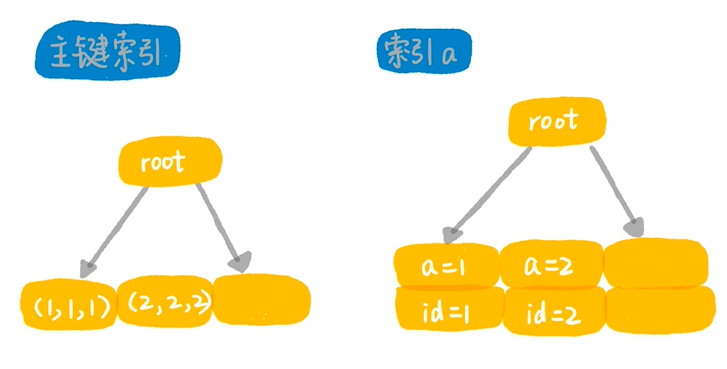
语句是否用到索引,是指语句在执行的时候有没有用到表的索引。图一:未用到索引,图二:使用主键索引,图三:使用了“a”索引。
图二:如果数据的压力非常高,那么该sql执行的时间也有可能超过long_query_time,会记录到慢查询日期里面
图三:是扫描了整个“a”的索引树,如果数据大于100W行效率就会变慢
是否执行索引只是表示了一个SQL语句执行的过程,而是否记录慢查询,是有执行时间决定的,而这个执行时间,可能会受外部因素的影响,也就是说是否使用索引,和是否记录慢查询之间并没有必然的联系。
什么叫做使用了索引,innoDB是索引组织表,所有的数据都是存储在索引树上面的。如下图所示,该表建立了两个索引,一个主键索引,一个普通索引a,在innoDB里数据是放在主键索引里的。
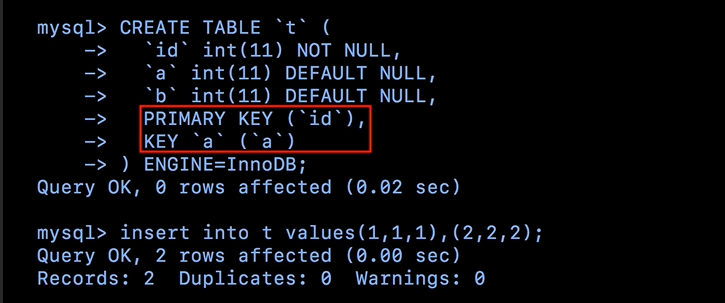
数据索引示意图:
如果执行explanin select * from t where id > 0 如下图:但是从数据上这个sql一定是做了全表扫描,但是优化器认为,这个sql的执行过程中需要根据主键索引定位到第一个满足id>0的值。即便这个sql使用到了索引,实际上也可能是全表扫描。

因此innoDB只有一种情况没有使用到索引,就是从主键索引的最左边的叶子节点开始,向右扫描整个索引树,也就是说没有使用索引并不是一个准确的描述,你可以用全表扫描表示一个查询遍历了整个主键索引树,也可以用全索引扫描说明像 select a from t这样的查询,它扫描了整个普通的索引树,而像select * from t where id=2 这样的语句,才是我们平时说的使用了索引,它表示的意思是,我们使用了索引的快速搜索功能,并且有效的减少了扫描行数。
索引的过滤性
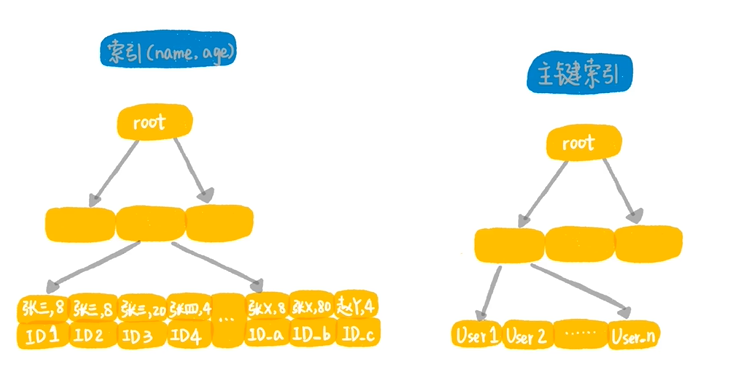
假设现在维护了一张记录了整个中国人的基本信息表,假设你要查询所有年龄在10到15岁之间的基本信息,通常语句就会是:select * from t_people where age between 10 and 15; 一般都会在age这个字段增加一个索引,否则就是一个全表扫描,但是在建了age上的索引后,这个语句还是执行慢,因为满足这个条件的数据有超过1亿行。建立索引表的组织结构图如下: 那么上面的sql语句执行流程是,从索引age上用树搜索,取出第一个age=10的记录,得到它的主键ID的值,根据ID值去主键索引树取整行的信息,作为结果集的一部分返回,在索引age上向右扫描,取出下一个ID值,到主键索引上取出整行信息,作为结果集的一部分返回。重复改操作,只到碰到第一个age > 15的记录。

其实最终关系的是扫描行数,对于一个大表,不止要有索引,索引的过滤性也要足够好,像刚才的例子age这个索引,它的过滤性就不够好,在设计表结构的时候,我们要让索引的过滤性足够好,也就是区分度比较高,那么过滤性好了,是不是标识查询的扫描行数就一定少呢?在看一个例子,参考下图:
如果有一个索引是姓名、年龄的联合索引,那这个联合索引的过滤性应该不错,如果你的执行语句是:select * from t_people where name ='张三' and age = 8; 就可以在联合索引上快速找到第一个姓名是张三,并且年龄是8的小朋友,这样的数据应该不会很多,因此向右扫描的行数也很少,查询效率就很高,但是在查询的过滤性和索引的过滤性不一定是一样的,如果现在你的需求是查出所有名字第一个字是张,并且年龄是8的所有小朋友,SQL语句通常这样写:select * from t_people where name like '张%' and age = 8;
在mysql5.5之前的版本中,这个语句的执行流程是这样的 (参考下图)从联合索引树上找到第一个姓名字段上第一个姓张的记录,取出主键ID,然后到主键索引上,根据ID取出
整行的值,判断年龄是否等于8,如果是就做为结果集的一行返回,如果不是就丢弃。我们把根据ID到主键索引上查找整行数据的这个动作,叫做回表,在联合索引上向右遍历,并重复做回表和判断的逻辑。直到碰到联合索引树上,第一个姓名第一个字不是张的记录为止。可以看到这个执行过程里面,最耗时的步骤就是回表。假设全国名字第一个字姓张的人有8000W,那么这个该过程就回表8000W次。在定位第一行记录的时候,只能使用索引和联合索引的最左前缀,称为最左前缀原则。可以看到这个执行过程它的回表次数特别多,性能不够好,有没有优化的方法呢?
在Mysql5.6版本引入了index condition pushdown的优化。优化的执行流程是:从联合索引树上找到第一个年龄字段是张开头的记录,判断这个索引记录上的年龄值是不是8,如果是就回表,取出整行数据,做为结果集返回的一部分,如果不是就就丢弃,不需要回表,在联合索引树上向右遍历,并判断年龄字段后,根据需要做回表,知道碰到联合索引树上,名字的第一个字不是张的记录为止。这个过程跟上面的过程的差别,是在遍历联合索引的过程中,将age=8这个条件下推到索引遍历的过程中,减少了回表次数。假设全国名字第一个字是张的人里面,有100W个年龄是8的小朋友,那么这个查询过程中,在联合索引里要遍历8000W次,而回表只需要100w次。可以看到index condition pushdown优化的效果还是很不错的,但是这个优化还是没有绕开最左前缀原则的限制,因此在联合索引里,还是要扫描8000W行,有没有更进一步的优化呢?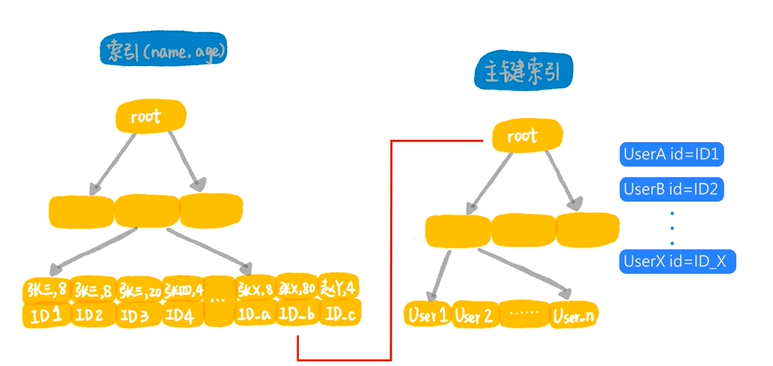
虚拟列的优化方式
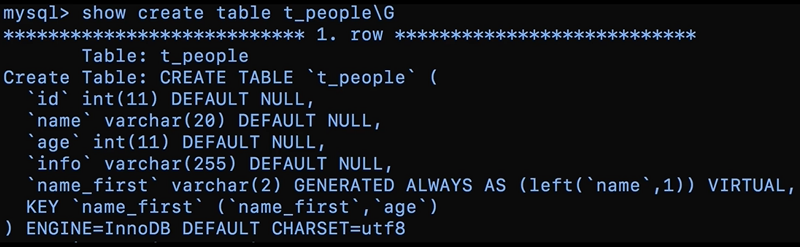
可以把名字的第一个字,和年龄做一个联合索引来试试,可以使用mysql5.7引入的虚拟列来实现,对应的修改表结构的sql语句是这么写的:
alert table t_people add name_first varchar(2) generated always as (left(name,1)),add index(name_first,age);
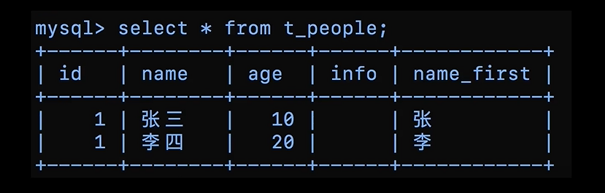
虚拟列的值,总是等于name字段的前两个字节,虚拟列在插入数据的时候,不能指定值,在更新的时候也不能主动修改,它的值会根据定义自动生成,在那么字段修改的时候,也会自动跟着修改。有了这个新的联合索引,我们再找名字的第一个字是张,并且年龄是8的小朋友的时候,这个SQL语句就可以这么写:
select * from t_people where name_first='张' and age=8;
这个SQL语句执行的过程,就只需要扫描联合索引的100W行,并回表100W次,这个优化的本质是我么创建了一个更紧凑的索引,来加速了查询的过程。
使用sql优化的过程,往往就是减少扫描行数的过程