1、创建hadoop用户,hadoopgroup组
groupadd -g 102 hadoopgroup # 创建用户组 useradd -d /opt/hadoop -u 10201 -g 102 hadoop #创建用户 passwd hadoop #给用户设置密码
2、安装ftp工具
yum -y install vsftpd 启动ftp:systemctl start vsftpd.service 停止ftp:systemctl stop vsftpd.service 重启ftp:systemctl restart vsftpd.service systemctl start vsftpd.service # 启动,无提示信息 ps -ef|grep vsft #查看进程已存在,直接使用ftp工具连接 root 1257 1 0 09:41 ? 00:00:00 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf root 1266 1125 0 09:42 pts/0 00:00:00 grep --color=auto vsft systemctl restart vsftpd.service
2、安装jdk、hadoop
- 将下载的jdk、hadoop拷贝到服务器上,解压,修改目录名
- 修改目录名,是为了方便书写

3、配置Java、hadoop环境变量
在最后添加Java、hadoop环境变量,注意路径不要写错即可
vim .bashrc more .bashrc #.bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions #jdk export JAVA_HOME=/opt/hadoop/jdk1.8 export JRE_HOME=${JAVA_HOME}/jre export CLASS_PATH=${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH #hadoop export HADOOP_HOME=/opt/hadoop/hadoop3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
4、切换root用户,修改各机/etc/hosts
vim /etc/hosts more /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.80.5 venn05 192.168.80.6 venn06 192.168.80.7 venn07
其他几台机操作相同
5、创建ssh密钥
mkdir .ssh # 创建.ssh 目录 cd .ssh/ ls pwd /opt/hadoop/.ssh ssh-keygen -t rsa -P ‘’ # 创建ssh秘钥,一路回车下去
每台机都执行以上步骤,创建 ssh 密钥
修改/etc/ssh/sshd_config文件
#$OpenBSD: sshd_config,v 1.100 2016/08/15 12:32:04 naddy Exp $ # This is the sshd server system-wide configuration file. See # sshd_config(5) for more information. # This sshd was compiled with PATH=/usr/local/bin:/usr/bin # The strategy used for options in the default sshd_config shipped with # OpenSSH is to specify options with their default value where # possible, but leave them commented. Uncommented options override the # default value. # If you want to change the port on a SELinux system, you have to tell # SELinux about this change. # semanage port -a -t ssh_port_t -p tcp #PORTNUMBER # #Port 22 #AddressFamily any #ListenAddress 0.0.0.0 #ListenAddress :: HostKey /etc/ssh/ssh_host_rsa_key #HostKey /etc/ssh/ssh_host_dsa_key HostKey /etc/ssh/ssh_host_ecdsa_key HostKey /etc/ssh/ssh_host_ed25519_key # Ciphers and keying #RekeyLimit default none # Logging #SyslogFacility AUTH SyslogFacility AUTHPRIV #LogLevel INFO # Authentication: #LoginGraceTime 2m #PermitRootLogin yes #StrictModes yes #MaxAuthTries 6 #MaxSessions 10 #PubkeyAuthentication yes # The default is to check both .ssh/authorized_keys and .ssh/authorized_keys2 # but this is overridden so installations will only check .ssh/authorized_keys AuthorizedKeysFile .ssh/authorized_keys #AuthorizedPrincipalsFile none #AuthorizedKeysCommand none #AuthorizedKeysCommandUser nobody # For this to work you will also need host keys in /etc/ssh/ssh_known_hosts #HostbasedAuthentication no # Change to yes if you don't trust ~/.ssh/known_hosts for # HostbasedAuthentication #IgnoreUserKnownHosts no # Don't read the user's ~/.rhosts and ~/.shosts files #IgnoreRhosts yes # To disable tunneled clear text passwords, change to no here! #PasswordAuthentication yes #PermitEmptyPasswords no PasswordAuthentication yes # Change to no to disable s/key passwords #ChallengeResponseAuthentication yes ChallengeResponseAuthentication no # Kerberos options #KerberosAuthentication no #KerberosOrLocalPasswd yes #KerberosTicketCleanup yes #KerberosGetAFSToken no #KerberosUseKuserok yes # GSSAPI options GSSAPIAuthentication yes GSSAPICleanupCredentials no #GSSAPIStrictAcceptorCheck yes #GSSAPIKeyExchange no #GSSAPIEnablek5users no # Set this to 'yes' to enable PAM authentication, account processing, # and session processing. If this is enabled, PAM authentication will # be allowed through the ChallengeResponseAuthentication and # PasswordAuthentication. Depending on your PAM configuration, # PAM authentication via ChallengeResponseAuthentication may bypass # the setting of "PermitRootLogin without-password". # If you just want the PAM account and session checks to run without # PAM authentication, then enable this but set PasswordAuthentication # and ChallengeResponseAuthentication to 'no'. # WARNING: 'UsePAM no' is not supported in Red Hat Enterprise Linux and may cause several # problems. UsePAM yes #AllowAgentForwarding yes #AllowTcpForwarding yes #GatewayPorts no X11Forwarding yes #X11DisplayOffset 10 #X11UseLocalhost yes #PermitTTY yes #PrintMotd yes #PrintLastLog yes #TCPKeepAlive yes #UseLogin no #UsePrivilegeSeparation sandbox #PermitUserEnvironment no #Compression delayed #ClientAliveInterval 0 #ClientAliveCountMax 3 #ShowPatchLevel no #UseDNS yes #PidFile /var/run/sshd.pid #MaxStartups 10:30:100 #PermitTunnel no #ChrootDirectory none #VersionAddendum none # no default banner path #Banner none # Accept locale-related environment variables AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE AcceptEnv XMODIFIERS # override default of no subsystems Subsystem sftp /usr/libexec/openssh/sftp-server # Example of overriding settings on a per-user basis #Match User anoncvs # X11Forwarding no # AllowTcpForwarding no # PermitTTY no # ForceCommand cvs server
重启服务:systemctl restart sshd
6、合并每台机器的公钥,放到每台机器上
Venn05 : 复制公钥到文件 : cat id_rsa.pub >> authorized_keys 拷贝到 venn 06 : scp authorized_keys hadoop@venn06:~/.ssh/authorized_keys Venn 06 : 拷贝venn06的公钥到 authorized_keys : cat id_rsa.pub >> authorized_keys 拷贝到 venn07 : scp authorized_keys hadoop@venn07:~/.ssh/authorized_keys Venn07 : 复制公钥到文件 : cat id_rsa.pub >> authorized_keys 拷贝到 venn 05 : scp authorized_keys hadoop@venn05:~/.ssh/authorized_keys 拷贝到 venn 06 : scp authorized_keys hadoop@venn06:~/.ssh/authorized_keys
多机类推
至此,配置完成,现在各机hadoop用户可以免密登录。
7、修改 hadoop环境配置:hadoop-env.sh
进入路径: /opt/hadoop/hadoop3/etc/hadoop,打开 hadoop-env.sh 修改:
export JAVA_HOME=/opt/hadoop/jdk1.8 # 执行jdk
8、修改hadoop核心配置文件 : core-site.xml
添加如下内容
<configuration> <!--hdfs临时路径--> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/hadoop3/tmp</value> </property> <!--hdfs 的默认地址、端口 访问地址--> <property> <name>fs.defaultFS</name> <value>hdfs://venn05:8020</value> </property> </configuration>
9、修改yarn-site.xml,添加如下内容
<configuration> <!-- Site specific YARN configuration properties --> <!--集群master,--> <property> <name>yarn.resourcemanager.hostname</name> <value>venn05</value> </property> <!-- NodeManager上运行的附属服务--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--容器可能会覆盖的环境变量,而不是使用NodeManager的默认值--> <property> <name>yarn.nodemanager.env-whitelist</name> <value> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value> </property> <!-- 关闭内存检测,虚拟机需要,不配会报错--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
10、修改mapred-site.xml ,添加如下内容
<configuration> <!--local表示本地运行,classic表示经典mapreduce框架,yarn表示新的框架--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!--如果map和reduce任务访问本地库(压缩等),则必须保留原始值 当此值为空时,设置执行环境的命令将取决于操作系统: Linux:LD_LIBRARY_PATH=$HADOOP_COMMON_HOME/lib/native. windows:PATH =%PATH%;%HADOOP_COMMON_HOME%\bin. --> <property> <name>mapreduce.admin.user.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop3</value> </property> <!-- 可以设置AM【AppMaster】端的环境变量 如果上面缺少配置,可能会造成mapreduce失败 --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop3</value> </property> </configuration>
11、修改hdfs-site.xml ,添加如下内容
<configuration> <!--hdfs web的地址 --> <property> <name>dfs.namenode.http-address</name> <value>venn05:50070</value> </property> <!-- 副本数--> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 是否启用hdfs权限检查 false 关闭 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <!-- 块大小,默认字节, 可使用 k m g t p e--> <property> <name>dfs.blocksize</name> <!--128m--> <value>134217728</value> </property> </configuration>
12、修workers 文件
[hadoop@venn05 hadoop]$ more workers venn05 # 第一个为master venn06 venn07
至此,hadoop master配置完成
13、scp .bashrc 、jdk 、hadoop到各个节点
进入hadoop home目录
cd ~ scp -r .bashrc jdk1.8 hadoop3 hadoop@192.168.80.6:/opt/hadoop/ scp -r .bashrc jdk1.8 hadoop3 hadoop@192.168.80.7:/opt/hadoop/
至此hadoop集群搭建完成。
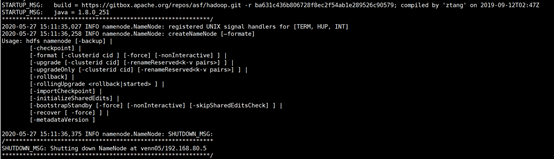
14、启动hadoop:
格式化命名空间: hdfs namenode –formate 启动集群: start-all.sh 输出: start-all.sh WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds. WARNING: This is not a recommended production deployment configuration. WARNING: Use CTRL-C to abort. Starting namenodes on [venn05] Starting datanodes Starting secondary namenodes [venn05] Starting resourcemanager Starting nodemanagers
问题:提示权限不够(解决花费时间:2h)
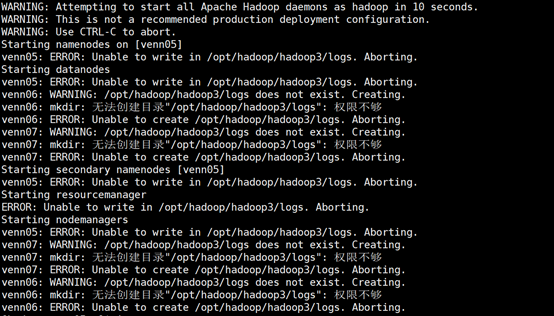
解决:sudo chmod -R a+w /opt/hadoop
问题:非root用户不能无密码访问(解决花费时间:3天)
解决:
chmod 700 hadoop chmod 700 hadoop/.ssh chmod 644 hadoop/.ssh/authorized_keys chmod 600 hadoop/.ssh/id_rsa
问题:Cannot write namenode pid /tmp/hadoop-hadoop-namenode.pid.
解决:sudo chmod -R 777 /tmp
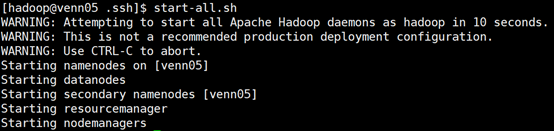
jps 查看进程: [hadoop@venn05 ~]$ jps 5904 Jps 5733 NodeManager 4871 NameNode 5431 ResourceManager 5211 SecondaryNameNode [hadoop@venn05 ~]$ 查看其它节点状态: [hadoop@venn06 hadoop]$ jps 3093 NodeManager 3226 Jps 2973 DataNode
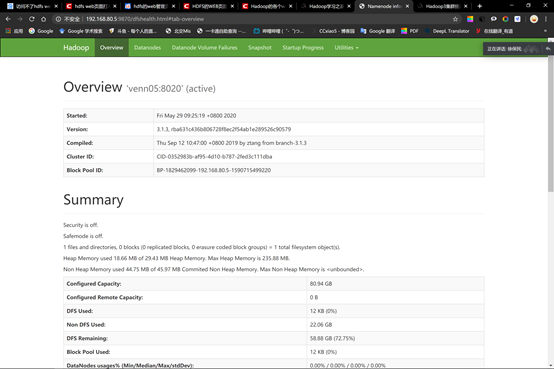
hadoop启动成功
查看yarn web 控制台:
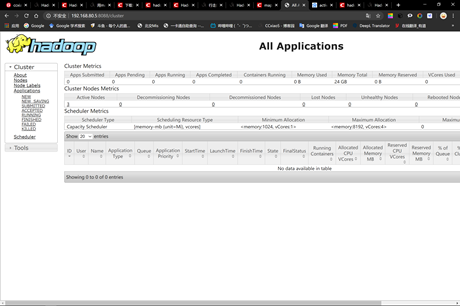
问题:访问不了HDFS web页面(解决花费时间:4h)
解决:HaDoop3.0之前web访问端口是50070,hadoop3.0之后web访问端口为9870,在hdfs-site.xml 把端口号改成9870即可,然后重新hdfs namenode –formate。Start-all.up。如果还是不能访问,关闭linux防火墙。
15 hive 安装
1)下载hive包
wget http://archive.apache.org/dist/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz
2)解压到hadoop目录
tar -zxvf apache-hive-2.3.3-bin.tar.gz #解压 mv apache-hive-2.3.3-bin hive2.3.3 #修改目录名,方便使用
3)配置hive环境变量
[hadoop@venn05 ~]$ more .bashrc # .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions #jdk export JAVA_HOME=/opt/hadoop/jdk1.8 export JRE_HOME=${JAVA_HOME}/jre export CLASS_PATH=${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH #hadoop export HADOOP_HOME=/opt/hadoop/hadoop3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH #hive export HIVE_HOME=/opt/hadoop/hive2.3.3 export HIVE_CONF_DIR=$HIVE_HOME/conf export PATH=$HIVE_HOME/bin:$PATH
4) 修改hive-env.sh
[hadoop@venn05 ~]$ cd hive2.3.3/conf [hadoop@venn05 conf]$ cp hive-env.sh.template hive-env.sh [hadoop@venn05 conf]$ vim hive-env.sh # HADOOP_HOME=${bin}/../../hadoop 打开注释修改 HADOOP_HOME=/opt/hadoop/hadoop3 # export HIVE_CONF_DIR= 打开注释修改 HIVE_CONF_DIR=/opt/hadoop/hive2.3.3/conf
5) 修改hive-log4j.properties
[hadoop@venn05 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties [hadoop@venn05 conf]$ vim hive-log4j2.properties 找到 property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} 修改 property.hive.log.dir = /opt/hadoop/hive2.3.3/logs
6) 确保万一,还可修改hive-site.xml
[hadoop@venn05 conf]$ cp hive-default.xml.template hive-site.xml [hadoop@venn05 conf]$ vim hive-site.xml 修改1:将hive-site.xml 中的 “${system:java.io.tmpdir}” 都缓存具体目录:/opt/hadoop/hive2.3.3/tmp 4处 修改2: 将hive-site.xml 中的 “${system:user.name}” 都缓存具体目录:root 3处 <property> <name>hive.exec.local.scratchdir</name> <value>/opt/hadoop/hive2.3.3/tmp/root</value> <description>Local scratch space for Hive jobs</description> </property> <property> <name>hive.downloaded.resources.dir</name> <value>/opt/hadoop/hive2.3.3/tmp/${hive.session.id}_resources</value> <description>Temporary local directory for added resources in the remote file system.</description> </property> <property> <name>hive.querylog.location</name> <value>/opt/hadoop/hive2.3.3/tmp/root</value> <description>Location of Hive run time structured log file</description> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>/opt/hadoop/hive2.3.3/tmp/root/operation_logs</value> <description>Top level directory where operation logs are stored if logging functionality is enabled</description>
7) 在hdfs上创建hive目录
hadoop fs -mkdir -p /user/hive/warehouse #hive库文件位置 hadoop fs -mkdir -p /tmp/hive/ #hive临时目录 #授权,不然会报错: hadoop fs -chmod -R 777 /user/hive/warehouse hadoop fs -chmod -R 777 /tmp/hive
在配置文件添加hive-site.xml
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> <property> <name>hive.exec.scratchdir</name> <value>/tmp/hive</value> <description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description> </property>
8)配置元数据库
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hive'; #创建hive用户 Query OK, 0 rows affected (0.00 sec) mysql> GRANT ALL ON *.* TO 'hive'@'%'; #授权 Query OK, 0 rows affected (0.00 sec) mysql> FLUSH PRIVILEGES; mysql> quit;
9)修改数据库配置:
vim hive-site.xml
<property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <!-- 链接地址 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://venn05:3306/hive?createDatabaseIfNotExist=true</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <!-- 用户名 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>Username to use against metastore database</description> </property> <!-- 密码 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property>
10)修改hive-env.sh
export HADOOP_HOME=/opt/hadoop/hadoop3 export HIVE_CONF_DIR=/opt/hadoop/hive2.3.3/conf export HIVE_AUX_JARS_PATH=/opt/hadoop/hive2.3.3/lib
11)上传mysql驱动包
下载地址:https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-8.0.19.zip

上传到 hive2.3.3/lib
12) 初始化hive
schematool -initSchema -dbType mysql
问题:(解决花费时间:3天)
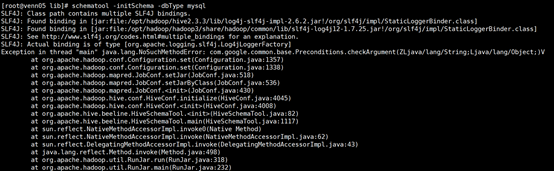
解决:从报错信息来看:java.lang.NoSuchMethodError
原因:1.系统找不到相关jar包
2.同一类型的 jar 包有不同版本存在,系统无法决定使用哪一个
com.google.common.base.Preconditions.checkArgument
根据百度可知,该类来自于guava.jar
查看该jar包在hadoop和hive中的版本信息
hadoop(路径:/opt/hadoop/hadoop3/share/hadoop/common/lib)中该jar包为 guava-27.0-jre.jar 
hive (路径:/opt/hadoop/hive2.3.3/lib)中该jar包为guava-14.0.1.jar 
删除hive中低版本的guava-14.0.1.jar包,
将hadoop中的guava-27.0-jre.jar复制到hive的lib目录下即可。

成功!!!!!!!!!!!

具体处理天气数据
1 运行环境说明
1.1 硬软件环境
- 主机操作系统:Windows 64 bit,双核4线程,主频2.2G,8G内存
- 虚拟软件:VMware® Workstation 15
- 虚拟机操作系统:CentOS 64位,单核,1G内存
- JDK:1.8
- Hadoop:3.1.3
1.2 机器网络环境
集群包含三个节点:1个namenode、2个datanode,其中节点之间可以相互ping通。节点IP地址和主机名分布如下:
|
序号 |
IP地址 |
机器名 |
类型 |
用户名 |
|
1 |
192.168.80.5 |
Venn05 |
名称节点 |
Hadoop |
|
2 |
192.168.80.6 |
Venn06 |
数据节点 |
Hadoop |
|
3 |
192.168.80.7 |
Venn07 |
数据节点 |
Hadoop |
所有节点均是CentOS7 64bit系统,防火墙均禁用,所有节点上均创建了一个hadoop用户,用户主目录是/opt/hadoop。
2 业务说明
求每日最高气温
2.1 下载数据集
由于老师提供的数据集无法下载,就找了类似的天气数据集(NCDC)。ftp://ftp.ncdc.noaa.gov/pub/data/noaa。
wget -D --accept-regex=REGEX -P data -r –c ftp://ftp.ncdc.noaa.gov/pub/data/noaa/2017/5*
2.2 解压数据集,并保存在文本文件中
zcat data/ftp.ncdc.noaa.gov/pub/data/noaa/2017/5*.gz > data.txt

查阅《1951—2007年中国地面气候资料日值数据集台站信息》,可知数据格式含义
1-4 0169 5-10 501360 # USAF weather station identifier 11-15 99999 # WBAN weather station identifier16-23 20170101 #记录日期
24-27 0000 #记录时间
28 429-34 +52130 #纬度(1000倍)
35-41 +122520 #经度(1000倍)
42-46 FM-1247-51 +0433 #海拔(米)
52-56 9999957-60 V02061-63 220 #风向
64 1 #质量代码
65 N66-69 001070 171-75 02600 #云高(米)
76 177 978 979-84 003700 #能见距离(米)
85 186 987 988-92 -0327 #空气温度(摄氏度*10)
93 194-98 -0363 #露点温度(摄氏度*10)
99 1100-104 10264 #大气压力
105 12.3 编写MapReduce程序进行数据清理
Mapper程序
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private static final int MISSING = 9999; @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String data = line.substring(15, 21); int airTemperature; if (line.charAt(87) == '+') { airTemperature = Integer.parseInt(line.substring(88, 92)); } else { airTemperature = Integer.parseInt(line.substring(87, 92)); } String quality = line.substring(92, 93); if (airTemperature != MISSING && quality.matches("[01459]")) { context.write(new Text(data), new IntWritable(airTemperature)); } } }
Reducer程序
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); } context.write(key, new IntWritable(maxValue)); } }
MaxTemperature程序
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; public class MaxTemperature extends Configured implements Tool { public static void main(String[] args) throws Exception { if (args.length != 2) { System.err .println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } Configuration conf = new Configuration(); conf.set("mapred.jar", "MaxTemperature.jar"); Job job = Job.getInstance(conf); job.setJarByClass(MaxTemperature.class); job.setJobName("Max temperature"); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(MaxTemperatureMapper.class); job.setReducerClass(MaxTemperatureReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } @Override public int run(String[] arg0) throws Exception { // TODO Auto-generated method stub return 0; } }
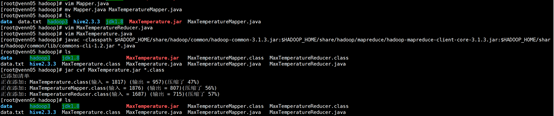
2.4编译java文件,打成jar包
注意自己hadoop的版本。
[root@venn05 hadoop]# javac -classpath $HADOOP_HOME/share/hadoop/common/hadoop-common-3.1.3.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.3.jar:$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar *.java [root@venn05 hadoop]# jar cvf MaxTemperature.jar *.class
2.5将数据上传至hdfs上
[root@venn05 hadoop]# hadoop fs -put data.txt /data.txt
2.6 运行程序
hadoop jar MaxTemperature.jar MaxTemperature /data.txt /out
问题:java.net.NoRouteToHostException:主机没有路由问题的解决。(解决花费时间:10min)


解决:只是关闭了venn05的防火墙,venn06、venn07的防火墙没有关闭
问题:找不到/bin/java(解决花费时间:2h)
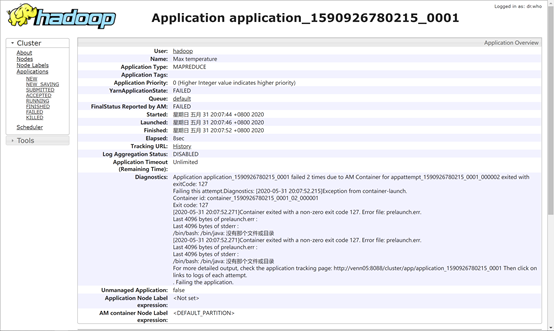
解决:建立软连接ln -s /opt/hadoop/jdk1.8/bin/java /bin/java
问题:
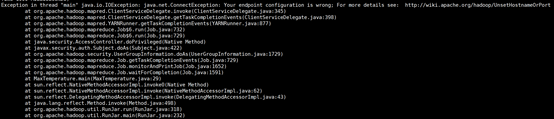
解决:由于没有启动historyserver引起的,在mapred-site.xml配置文件中添加
<property> <name>mapreduce.jobhistory.address</name> <value>venn05:10020</value> </property>
成功!!!!!!
2020-06-01 00:01:31,548 INFO client.RMProxy: Connecting to ResourceManager at venn05/192.168.80.5:8032 2020-06-01 00:01:33,190 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2020-06-01 00:01:33,274 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1590940656612_0001 2020-06-01 00:01:33,616 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2020-06-01 00:01:35,332 INFO input.FileInputFormat: Total input files to process : 1 2020-06-01 00:01:35,543 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2020-06-01 00:01:35,632 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2020-06-01 00:01:35,671 INFO mapreduce.JobSubmitter: number of splits:3 2020-06-01 00:01:35,744 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 2020-06-01 00:01:36,020 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2020-06-01 00:01:36,171 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1590940656612_0001 2020-06-01 00:01:36,171 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2020-06-01 00:01:36,550 INFO conf.Configuration: resource-types.xml not found 2020-06-01 00:01:36,551 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2020-06-01 00:01:37,251 INFO impl.YarnClientImpl: Submitted application application_1590940656612_0001 2020-06-01 00:01:37,486 INFO mapreduce.Job: The url to track the job: http://venn05:8088/proxy/application_1590940656612_0001/ 2020-06-01 00:01:37,487 INFO mapreduce.Job: Running job: job_1590940656612_0001 2020-06-01 00:02:26,088 INFO mapreduce.Job: Job job_1590940656612_0001 running in uber mode : false 2020-06-01 00:02:26,094 INFO mapreduce.Job: map 0% reduce 0% 2020-06-01 00:03:24,492 INFO mapreduce.Job: map 6% reduce 0% 2020-06-01 00:03:30,433 INFO mapreduce.Job: map 26% reduce 0% 2020-06-01 00:03:31,480 INFO mapreduce.Job: map 31% reduce 0% 2020-06-01 00:03:36,616 INFO mapreduce.Job: map 33% reduce 0% 2020-06-01 00:03:43,030 INFO mapreduce.Job: map 39% reduce 0% 2020-06-01 00:03:58,376 INFO mapreduce.Job: map 100% reduce 0% 2020-06-01 00:04:19,353 INFO mapreduce.Job: map 100% reduce 100% 2020-06-01 00:04:29,534 INFO mapreduce.Job: Job job_1590940656612_0001 completed successfully 2020-06-01 00:04:35,358 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=18428403 FILE: Number of bytes written=37725951 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=346873253 HDFS: Number of bytes written=132 HDFS: Number of read operations=14 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Killed map tasks=1 Launched map tasks=3 Launched reduce tasks=1 Data-local map tasks=3 Total time spent by all maps in occupied slots (ms)=223517 Total time spent by all reduces in occupied slots (ms)=26522 Total time spent by all map tasks (ms)=223517 Total time spent by all reduce tasks (ms)=26522 Total vcore-milliseconds taken by all map tasks=223517 Total vcore-milliseconds taken by all reduce tasks=26522 Total megabyte-milliseconds taken by all map tasks=228881408 Total megabyte-milliseconds taken by all reduce tasks=27158528 Map-Reduce Framework Map input records=1423111 Map output records=1417569 Map output bytes=15593259 Map output materialized bytes=18428415 Input split bytes=276 Combine input records=0 Combine output records=0 Reduce input groups=12 Reduce shuffle bytes=18428415 Reduce input records=1417569 Reduce output records=12 Spilled Records=2835138 Shuffled Maps =3 Failed Shuffles=0 Merged Map outputs=3 GC time elapsed (ms)=6797 CPU time spent (ms)=19450 Physical memory (bytes) snapshot=529707008 Virtual memory (bytes) snapshot=10921758720 Total committed heap usage (bytes)=429592576 Peak Map Physical memory (bytes)=157679616 Peak Map Virtual memory (bytes)=2728787968 Peak Reduce Physical memory (bytes)=137711616 Peak Reduce Virtual memory (bytes)=2735394816 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=346872977 File Output Format Counters Bytes Written=132 2020-06-01 00:04:37,460 INFO mapred.ClientServiceDelegate: Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
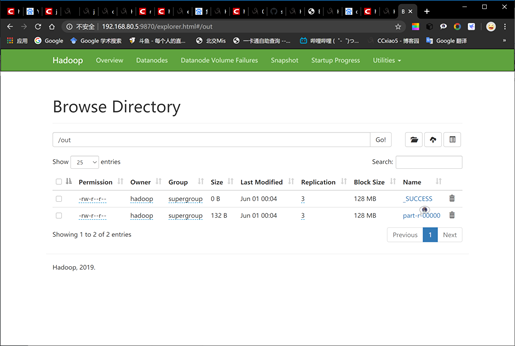
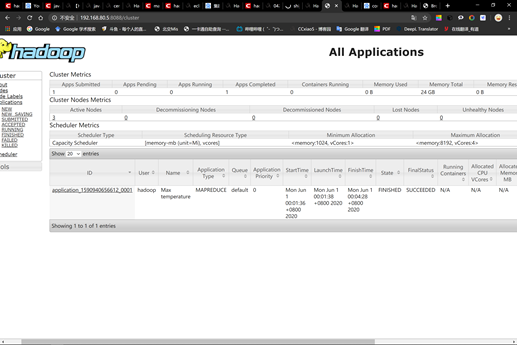
2.7 查看结果
由于这里的气温是摄氏度的10倍,所以看起来很大。把记录保存下来。
hadoop fs -cat /out/part-r-00000
hadoop fs -copyToLocal /out/part-r-00000 result.txt

2.8导入hive数据库
在导入前,将数据温度转变成正常温度。
1)登录hive
2)创建表
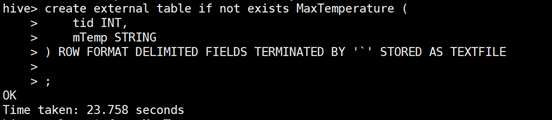
3)导入
create external table if not exists MaxTemperature ( tid INT, mTemp STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '`' STORED AS TEXTFILE; hive> load data local inpath '/opt/hadoop/data.txt' into table MaxTemperature;

问题:执行select语句出错(解决花费时间:2h)

解决1:是由于权限不够,更改权限即可。切换成hadoop用户,执行上面的修改权限指令,因为hadoop的用户是hdfs,所以不能用root修改。
[hadoop@venn05 ~]# hadoop fs -ls /tmp Found 2 items drwx------ - hadoop supergroup 0 2020-06-01 00:01 /tmp/hadoop-yarn drwx-wx-wx - root supergroup 0 2020-06-01 00:23 /tmp/hive [hadoop@venn05 ~]$ hadoop fs -chown -R root:root /tmp
解决2:上述操作执行后继续报错。(未解决,查资料可知是因为hive版本和hadoop版本不匹配)
Exception in thread "main" java.lang.IllegalAccessError: tried to access method com.google.common.collect.Iterators.emptyIterator()Lcom/google/common/collect/UnmodifiableIterator; from class org.apache.hadoop.hive.ql.exec.FetchOperator at org.apache.hadoop.hive.ql.exec.FetchOperator.<init>(FetchOperator.java:108) at org.apache.hadoop.hive.ql.exec.FetchTask.initialize(FetchTask.java:87) at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:541) at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1317) at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1457) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1227) at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:233) at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:184) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:403) at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:318) at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
2.9 导入mysql数据库
[hadoop@venn05 ~]mysql –u root –p; mysql> CREATE DATABASE Temperature; mysql> use Temperature; mysql> use Temperature; mysql> CREATE TABLE MaxTemperature( > tid VARCHAR(20), > mTemp VARCHAR(20)); LOAD DATA LOCAL INFILE '/opt/hadoop/result.txt' INTO TABLE MaxTemperature
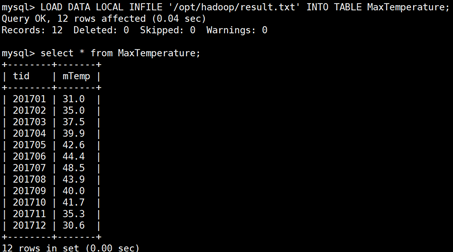
2.10 excel 展示数据
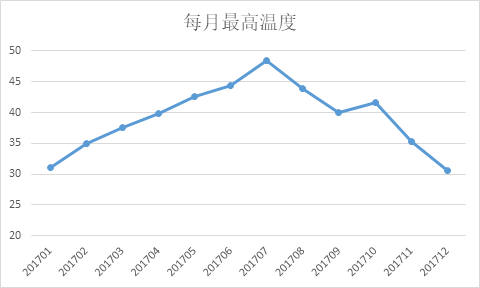
zcat data/ftp.ncdc.noaa.gov/pub/data/noaa/2017/5*.gz > data.txt