目录:
使用场景
基本架构
数据划分
类型映射
Sqoop Import
Sqoop Export
线上业务系统使用的存储一般是MySQL等关系型数据库,MySQL的优势是能快速应对频繁的增删改查,但对于针对历史数据等大数据量进行统计分析,数据挖掘等需求就不能满足了,这也是大数据技术出现的原因,Hadoop 的 MapReduce 计算框架就是针对大数据量统计分析设计的。而 Sqoop 的作用是将我们线上业务系统数据库中的数据导入到大数据平台中,如 HDFS 或者 Hive 中,之后我们就可以用大数据技术来对海量数据进行统计分析,同时,我们也可以将大数据平台上的结构化数据导入到 MySQL 等关系型数据库中,用于支持业务系统的数据需求。所以 Sqoop 搭建了业务系统数据库中的结构化数据到大数据系统之间的桥梁,实现了数据的同步。
本文所涉及的 Sqoop 版本为1.4,这也是官方推荐的版本。Sqoop 可以实现从关系型数据库导入到 HDFS,从 HDFS 导出到关系型数据库,从关系型数据库导入 Hive 等,Sqoop 还支持各种存储格式和压缩算法。Sqoop 底层调用了 Hadoop 中的 MapReduce 计算框架,所以实现了数据导入的并行化,能够处理大数据量的导入导出,以 MySQL 和 HDFS 中数据同步为例:
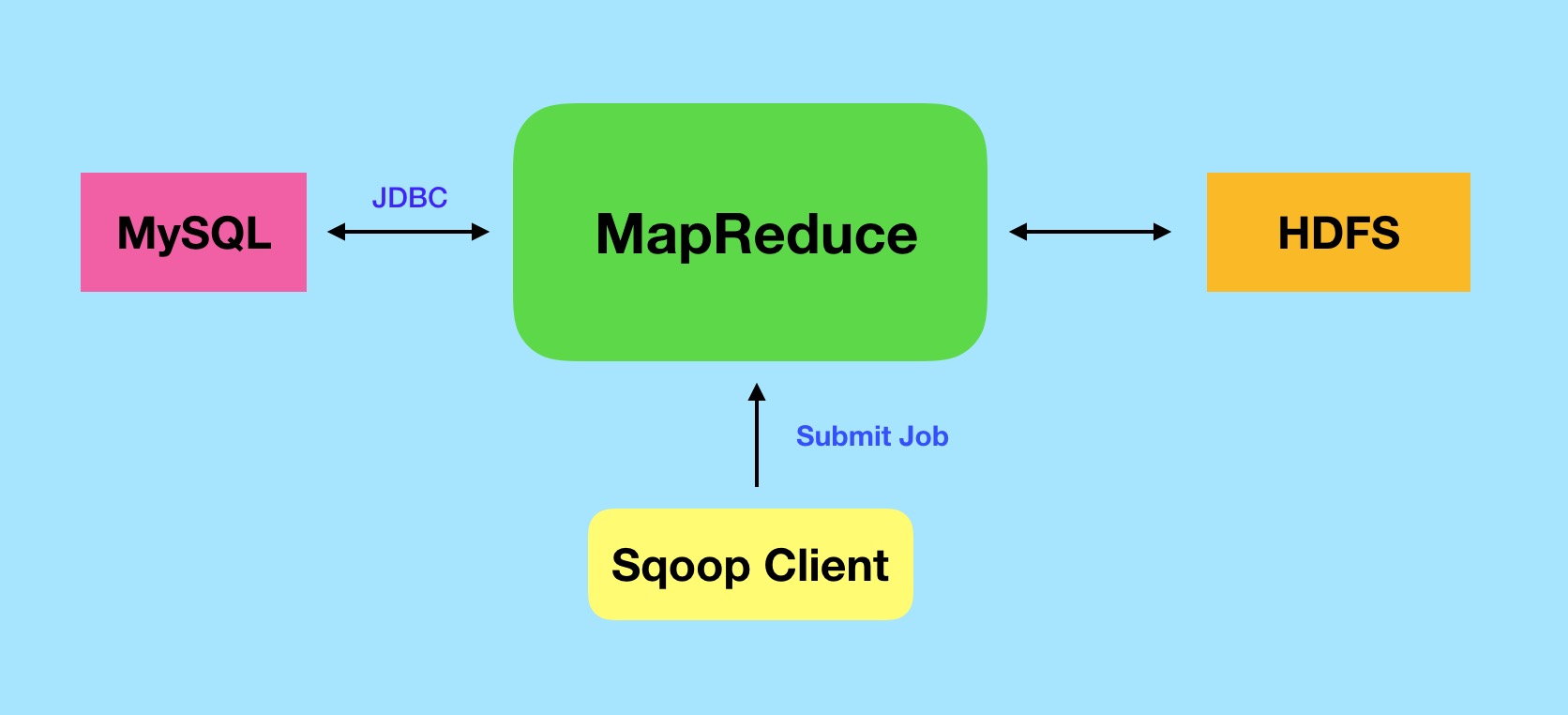
以从 MySQL 中导入数据到 HDFS 为例,Sqoop 通过提交任务给 Hadoop 集群,然后 MapReduce 通过 JDBC 从 MySQL 中读取数据,并存入 HDFS ,注意只需要 Map 阶段即可,并不需要 Reduce 阶段,根据启动的 Map 的数量,数量越大,并行度越高,以此可以实现大数据量的同步。
Sqoop 底层使用的是MapReduce,我们可以通过 -m 或 --num-mappers 参数后面跟数字来指定 Sqoop 导入时需要启动的 Mapper 个数,如果不指定该参数,默认 Sqoop 会启动 4 个 Mapper,Mapper 个数越多,Sqoop 导入的并行度就越高,速度自然也会越快;但并不是越多越好,要考虑到关系型数据库的负载,太高的并发连接会给数据库很大的压力,反而导致性能下降,同时,Mapper 的数量太多也会造成 Hadoop 集群资源浪费。
设定好 Mapper 的数量之后,Sqoop 要根据 Mapper 数量对数据进行划分,一般来说,我们希望数据划分的均匀些,假如数据量有1000条,Mapper 数量有 5 个,那么均匀的划分就是每个 Mapper 导入 200 条数据,划分均匀才能体现并发的优势,如果数据划分不均匀,并发的性能会大大折扣。一般采用表的主键来进行数据划分,因为关系型数据库一般采用自增主键,自增主键非常适合均匀划分数据,划分好数据之后,每个 Mapper 会导入自己分配的那部分数据,通过执行SQL 语句,我们这里数据量是 1000 条,有 5 个 Mapper,那么第一个 Mapper 的数据范围就是 1 到 200 ,导入完成后,会在 HDFS 导入目录下生成几个文件,文件数量跟 Mapper 数量是对应的。
SELECT * FROM table_name WHERE id >= 1 AND id <= 200
Sqoop 是如何获取分片字段的范围的呢? Sqoop 会执行 select min(<split-by>), max(<split-by>) from <table name> 来获取分片字段的最大最小值,再根据分片字段范围划分出每个 Mapper 需要读取的数据范围,我们可以通过 --boundary-query 参数来替换掉获取分片范围的查询语句。
需要注意的是,如果表的主键不适合用来做数据划分或表本身没有主键,我们可以通过 --split-by 参数后面跟分片字段来指定一个合适的分片字段,确保数据划分均匀。如果我们的表没有设置主键且我们在导入的时候也没有指定分片字段,那么 Sqoop 任务将会失败,只有当我们的 Mapper 数量设置为1时不会出错,因为一个 Mapper 就不需要对数据进行划分了。
导出任务的数据划分有些不一样,导出任务是从 HDFS 导出到关系型数据库中,导出任务的数据划分按照 HDFS 的 FileInputFormat 的 Split 划分,默认使用 CombineInputFormat ,尽量把同一个节点的数据使用同一个 Mapper 来处理,这样可以减少由于很多小文件而导致的 Mapper 任务数量过多而导致的资源浪费,如果导出文件是压缩格式,且无法分片,Sqoop 将按照单个文件进行划分,每个文件对应一个 Mapper。所以,导出任务中,用户指定的分片参数不一定会生效,具体的任务数量取决于导出数据的性质。
Sqoop 在创建导入导出任务前,会先根据数据的结构,将每一条数据记录构造成一个 JavaBean 对象,这样就可以将对数据的操作转化为对 JavaBean 的操作,这其中比较重要的一点是数据类型映射,也就是如何将数据库中的数据类型与 JavaBean 中的数据类型对应起来,Sqoop 默认的对应关系是:

如果想要更改对应关系,可以通过 --map-column-java 参数来指定,例如:如果数据库中有张 user 表,字段为 id,name,age,通过 --map-column-java id=String, name=String, age=Integer ,这样就实现了自定义类型映射。
Sqoop Import 将关系型数据库中的数据导入到 HDFS 或 HIVE 上,导入过程实际上是通过 select 语句,可以通过 sqoop import 或 sqoop-import 后跟参数使用。
常规的参数包括 --connect 用于指定 JDBC 连接地址,--username 用于指定数据库用户名, --password 用于指定数据库密码,也可以通过 --password-file 后跟存有密码的文件名来指定密码,或者通过 -P 参数在控制台输入密码,--driver参数用于指定使用的 JDBC 驱动,例如 MySQL 用到的驱动是 com.mysql.jdbc.Driver, 要确保驱动的 jar 包存在 Sqoop 安装目录下的 lib 目录下。
数据格式,默认情况下导入到 HDFS 上的数据格式是 text 文本类型,可以通过参数 --as-textfile 显式的声明出来,--as-avrodatafile 存储为 Avro 格式, --as-sequencefile 存储为 sequence 格式,--as-parquetfile 存储为 parquet格式。
--delete-target-dir 参数设定后,如果导入路径已经存在,Sqoop 将会删除该文件,再进行导入,如果不配置该参数,如果导入路径已经存在,Sqoop 会抛出 FileAlreadyExistsException。
-m 或 --num-mappers 用于指定导入时启动的 mapper 个数;--split-by 指定用于分片的字段,默认会使用表的主键进行分片,注意不能同 --autoreset-to-one-mapper 一起使用。
--table 指定需要导入的表名,默认导入的是表的所有字段,顺序与数据库中的字段顺序一致,通过 --columns 可以指定需要导入的字段,并且可以更改字段顺序;--where 字段可以帮助我们筛选需要的数据,例如:--where "id > 100" 这样 Sqoop 只会导入 id 超过 100 的行号。
除了使用 --table, --columns, --where 等方式,也可以通过 -e 或 -query 后跟 SQL 语句来自定义导入例如: select id, name from table_user where id>100 and $CONDITIONS , 如果我们的 Mapper 数量为4,这条语句就会被四个 Mapper 执行,每个 Mapper的数据范围是不同的,所以在 where 语句中要添加 $CONDITIONS ,这个变量将会在执行的时候被 Sqoop 替换成相应的数据分片范围,--query 后面的查询语句不能太复杂,否则会出错。注意 -query 与 --table 不能同时使用。
--target-dir 指定导入到 HDFS 中的目录地址,--warehouse-dir 指定的地址是父目录地址。注:--warehouse-dir 不能和 --query 一起使用,只能用在 --table 的情况下。
-z 或 --compress 指定是否对导入文件进行压缩,--compression-codec 指定压缩格式,默认 gzip
--fields-terminated-by 指定导入数据的字段分隔符,默认使用逗号;--lines-terminated-by 指定行之间的分隔符,默认使用换行符 ( )
--direct 参数可以设置导入使用数据库特有的工具,而不使用 JDBC 连接,例如 MySQL 中的 mysqldump 可以实现快速导出数据,比 JDBC 要快。
--incremental 参数有两个取值,append 和 lastmodified,设定为 append 模式, 同时通过 --check-column 设定字段,--last-value 设定导入范围,例如:--incremental append --check-column id, --last-value 10 ,Sqoop 将会导入 id 超过 10 的字段,并追加到目标目录下面,注意 --check-column 后面的字段不能是字符类型,如果不指定 --last-value 的值,Sqoop 将会导入全部的数据并追加到目标目录下面。设置为 lastmodified 模式时,--check-column 后面只能跟 timestamp 类型或 time 类型,同时指定 --last-value 跟时间类型,Sqoop 会将超过 --last-value 的值插入到目标目录下, 如果不指定该值则 Sqoop 会将所有的数据导入,此外还必须增加一个参数,--append 表示把大于 --last-value 的值追加到目标目录下,--merge-key 跟字段名表示插入的时候按照字段名进行更新,如果原目录下有相同的该字段名,就直接将其覆盖掉,如果没有则追加上。--append 和 --merge-key 必须设置一个,不能省略。注意:append 模式和 lastmodified 模式不同的地方在于 append 模式只能追加数据,不能更新,通过 --check-column 和 --last-value 来确定追加的数据范围,--last-value 可以省略,--check-column 不能省略, lastmodified 模式多了一个参数,--append 或 --merge-key ,这个参数不能省略,--append 表示追加,与 append 模式是一样的,--merge-key 可以覆盖数据。
利用 --incremental 可以实现增量导入和对数据的更新,例如如果是订单表,我们可以通过 HIVE 新建分区的方式,每天导入一个分区,对于用户表,数据量不大,我们可以不建分区表,然后采用 lastmodified 的模式进行更新,通过控制参数 --merge-key 实现对用户状态的更新,注意 --merge-key 模式会覆盖目录下所有的重复值,也就是对目录中所有的数据进行了去重处理。
Sqoop Export 将 HDFS 或 HIVE 上的数据导出到关系型数据库中,导出的时候,Sqoop 会读取 HDFS 上的文件,然后按照我们指定的分隔符将其分成字段,根据我们传递的参数,Sqoop 会生成 insert 语句或 update 语句,将数据插入到关系型数据库中,使用方法可以通过 sqoop export 或 sqoop-export 后跟参数。
导出参数中的常规参数与导入一致,如:数据库连接地址,用户名和用户密码等参数。
--export-dir 指定需要导出的目录地址,--table 指定需要导出的数据库中的表,--columns 指定导出的字段,如果不指定该参数,将导出所有字段,注意:不在 --columns 参数指定的字段必须有默认值,或者可以为空值,否则导出任务会失败。
export 同样可以有 --direct 参数,比 JDBC 的效率更高。
--input-fields-terminated-by 设置导入文件的字段分隔符,默认是逗号;--input-lines-terminated-by 设置导入文件的行分隔符,默认是换行符。
Sqoop export 过程中,事务是分成多个的,所以可能会出现 export 任务失败了,但表中导入了部分数据,这会引起很多麻烦,所以 Sqoop export 提供了一个参数 --staging-table 后面跟中间表名,Sqoop 会先将数据导入到中间表中,导入完成后,再通过一个事务将中间表的数据导入到最终的目标表中,这样就实现了即使任务失败也不会在目标表中有残留数据,中间表需要我们事先创建好,并且中间表的结构必须与目标表的结构一致,同时要确保任务运行前,中间表中不能有数据,或者通过增加 --clear-staging-table 参数并设为 true ,Sqoop 将在 export 任务执行前清空中间表。注意:使用 --update-key 模式不能使用中间表这种导入方式。
默认情况下,export 会将导出目录下的每条数据通过一条 INSERT 语句追加到表中,要注意如果表有主键或者 unique key ,要确保不能重复,否则会出错,这种模式一般是用来将数据导入到一张空的表中。如果设定了参数 --update-key , export 会更新表中的数据,每条导入的数据会通过一条 UPDATE 语句来更新到表中,例如我们指定 --update-key id ,那么 Sqoop 将会生成 类似 UPDATE table_1 SET .... where id = 1 的 SQL 语句,这种情况,只会更新表中的数据,如果表中不存在指定字段的记录,那么 Sqoop 并不会插入数据,如果需要在数据不存在时就插入的模式,需要指定参数 --update-mode 后跟 allowinsert , 如果不指定该参数,默认时 updateonly 也就是只更新不新增。
注意:updateonly 和 allowinsert 的另外一点不同在于,allowinsert 生成的 SQL 语句其实是 INSERT INTO ON DUPLICATE KEY UPDATE 的类型,这条语句会根据主键或联合主键去判断数据库中数据是否重复,--update-key 里面的参数好像没用啊,不管指定什么字段,Sqoop 还是会按照主键或联合主键去更新所有的值,但这个参数还不能为空,否则会报错,建议还是写联合主键或主键的值,如果不想更新所有的值,可以通过 --columns 来选取需要更新的字段,注意这个时候其他字段要有默认值或者可以为null,否则可能会出现问题。而 updateonly 由于是生成 UPDATE 语句所以 columns 可以任意指定。updateonly 中的 --update-key 参数指定了需要更新的字段,如果设置为 id,name ,那么数据库中只要 id ,name 和 Sqoop 导出目录相同的就会被更新,可能会有多条记录满足条件,整条记录的所有字段都会被更新,这里注意可能会出现主键冲突的错误。