https://zhuanlan.zhihu.com/p/110171621
一、什么是时序点过程
现实世界中有这么个问题:有这么一系列历史事件,每个事件都有其对应的发生时间,也有其所属的事件类型,基于这一系列历史事件,预测下一个要发生的是什么类型的事件,以及其发生的时间。
比如下一次地震发生在何时,何地是事件类型,比如一种股票的下一次买卖将发生在何时,买入或卖出是事件类型,比如用户将在何时去下一个目的地,目的地是哪里是事件类型。
点过程可以对这一系列历史事件建模,来解决这个预测问题。
时序点过程的核心是强度函数 。
是截止
时刻之前事件类型
发生的总次数。
代表在时间窗口
内,事件类型
发生的概率。
其中 代表基于历史行为,事件类型
在
时刻发生的条件概率密度函数;
代表基于历史行为,至少有一个事件类型在
发生的条件概率。强度函数
为:
因此,只要能根据历史事件模拟出强度函数 ,则可以根据
预测下一个事件。对
的模拟将点过程分为传统点过程和深度点过程。
二、传统点过程
1.homogeneous poisson process假设 独立于历史事件,且随着
的变化恒定,即
。inhomogeneous poisson process假设
独立于历史事件,且随着
的变化而变化,即
2.hawkes process 认为历史事件有激励作用: ,
,
,
3. self-correcting process 认为强度函数的趋势是一直在增大,但是当一个事件发生后,会先减小。 ,
,
三、深度点过程
传统点过程缺点:
(1)传统点过程对强度函数有着上述设定,很有可能不符合实际情况,比如历史事件对强度函数的影响并不一定是累加的;
(2)如果有多种事件类型的话,还需作出各个事件类型是互相独立的假设,并且对每个事件类型求强度函数;
(3)传统点过程对数据的缺失处理不是很好,有时我们只能观测到一部分事件。
深度点过程就无需这么麻烦,用神经网络这样的非线性函数模拟强度函数,这样一个黑盒子无需设定任何先验知识。
1. Recurrent Markd Temporal Point Processes:Embedding Event History to Vector(kdd2016)
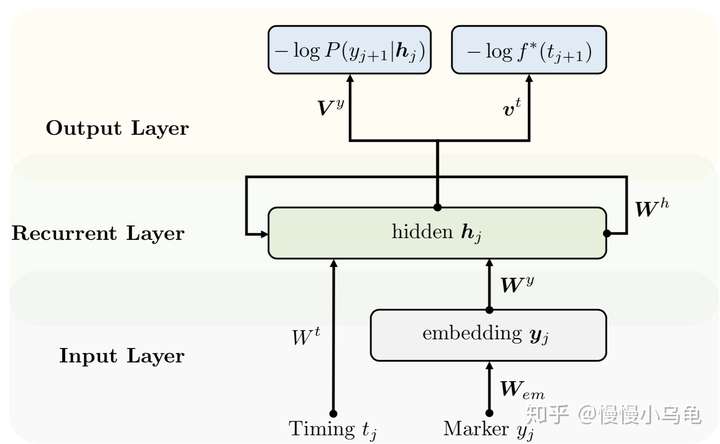
输入层:事件类型和发生时间为输入。事件类型用词向量,时间用时间的特征(比如是否周末,是否深夜等)
事件类型生成:普通的softmax
强度函数为:
时间生成:用下面这种求平均值的算法比较复杂,没有数值解,有一种简单的解法,我还没弄明白是啥...
loss:
实验使用的四个数据集:
New York City Taxi Dataset:共173 million记录,299个事件类型,670753 个序列
Financial Transaction Dataset:共0.7 million记录,2个事件类型,693499 个序列
Electrical Medical Records:204个事件类型,650个病人的序列
Stack OverFlow Dataset :共480k记录,81个事件类型,6k用户的序列
代码地址: https://github.com/dunan/NeuralPointProcess
2. The Neural Hawkes Process: A Neurally Self-Modulating Multivariate Point Process(nips 2017)
上一篇论文中,lstm的不同时步的hidden state是离散的,换句话说:当一个新事件发生后,断崖式变化。本文提出一个连续的hidden state变化方式。
事件 到事件
之间的
时刻,强度函数由
决定,
由
决定。注意
在上篇论文是没有的哦,因为上一篇论文只有事件
到事件
,没有他们之间的
时刻
这里的 和
都不和上一篇论文中一样,而是
和
在
时刻的值。
可见 事件
到事件
之间从
向
变化的,至于
怎么来的,大概是训练的参数吧(还没太明白)。
loss是根据强度函数算的:
本文的测试数据集:
Retweets Dataset:3个事件类型,1739547 个序列,序列长度109
MemeTrack Dataset:5000个事件类型,93267 个序列,序列长度3
3. CTRec: A Long-Short Demands Evolution Model for Continuous-Time Recommendation(SIGIR 2019)
这篇文章主要是将深度点过程用在商品推荐上,之前的商品推荐只考虑推荐对的商品,没有考虑在对的时间推荐对的商品,比如用户刚买了个厕所读物,不代表它喜欢厕所读物,不能一直给他推荐厕所读物,而应该考虑商品周期,等他看完了上一本,再给他推荐新的(长期需求)。再比如用户买了个画板,就得立马推荐颜料了(短期需求)。总之,就是考虑用户画像、短期需求和长期需求。
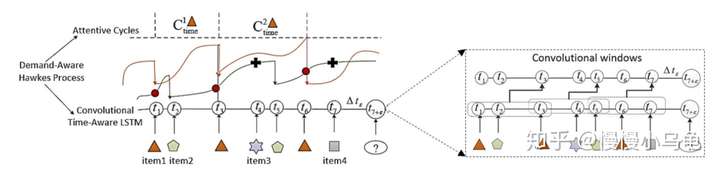
论文有三个创新点:使用的连续lstm,就是上一篇论文中的;使用cnn捕捉短期需求;使用attention捕捉长期需求。
强度函数融合了用户画像、短期需求和长期需求。
cnn使用k个核做多层卷积,最后average pooling。
attention: