一、网络更深、更宽带来的问题
- 参数太多,若训练数据集有限,容易过拟合;
- 网络越大计算复杂度越大,难以应用;(内存和计算资源)
- 网络越深,梯度越往后穿越容易消失,难以优化模型。
解决:
- 如何减少参数(且保证性能):使用更小的核,比如5x5 换成 2个3*3;使用Asymmetric方式,比如3x3 换成 1x3和3x1两种;
- 如何减少computational cost:Inception结构,将全连接甚至一般的卷积都转化为稀疏连接;
- 如何解决“梯度消失”:BN层
所以,Inception系列的网络是“很窄很深”的结构。
二、设计原则
- 2.1避免特征表示瓶颈,尤其是在网络的前面。要避免严重压缩导致的瓶颈。特征表示尺寸应该温和的减少,从输入端到输出端。特征表示的维度只是一个粗浅的信息量表示,它丢掉了一些重要的因素如相关性结构。
- 2.2高纬信息更适合在网络的局部处理。在卷积网络中逐步增加非线性激活响应可以解耦合更多的特征,那么网络就会训练的更快。
- 2.3空间聚合可以通过低纬嵌入,不会导致网络表示能力的降低。例如在进行大尺寸的卷积(如3*3)之前,我们可以在空间聚合前先对输入信息进行降维处理,如果这些信号是容易压缩的,那么降维甚至可以加快学习速度。
- 2.4平衡好网络的深度和宽度。通过平衡网络每层滤波器的个数和网络的层数可以是网络达到最佳性能。增加网络的宽度和深度都会提升网络的性能,但是两者并行增加获得的性能提升是最大的。
模型结构
Inception-v2把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍。
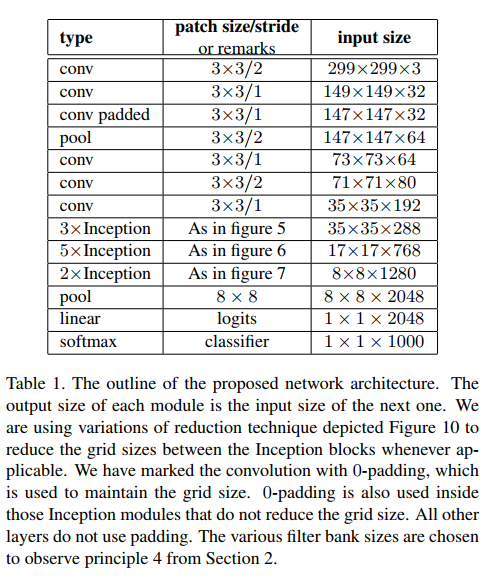
功能
设计功能:最后两层之前模型完成 299x299x3 到 1x1x2048的特征映射,把input映射成2048维的特征向量,完成自动特征提取的工作;
其中,前面的conv和pool完成提取特征,中间Inception结构可以自动学习出滤波器的类型:
- 第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;
- 第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;
- 第三部分增多了filter,使用了卷积池化并行结构。;
最后两层是一个全连接层,起到使用特征向量进行分类的功能。
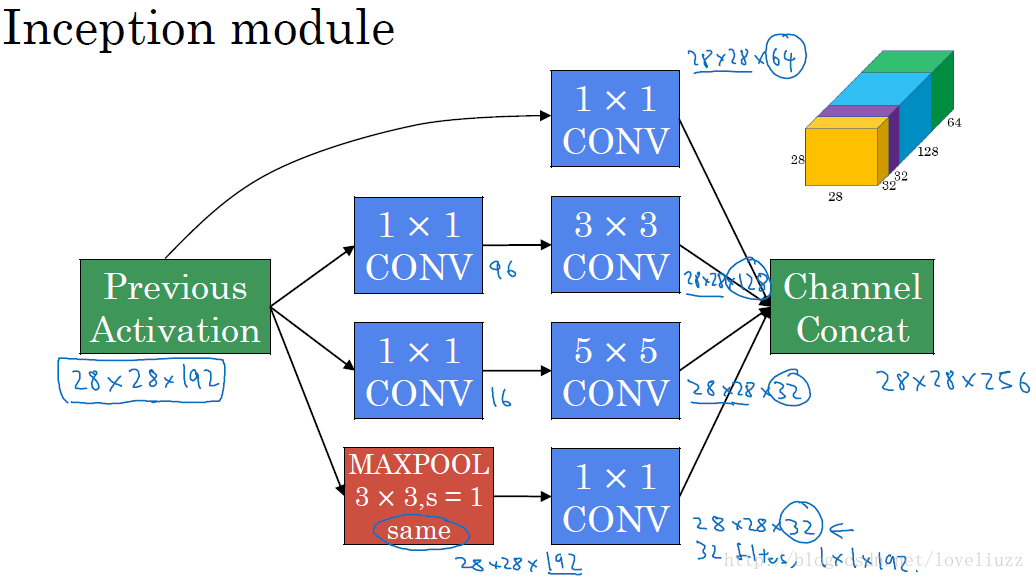
三、Inception Module
Inception的作用:代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为决定使用哪个过滤器,是否需要池化层等,
由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数。
原理
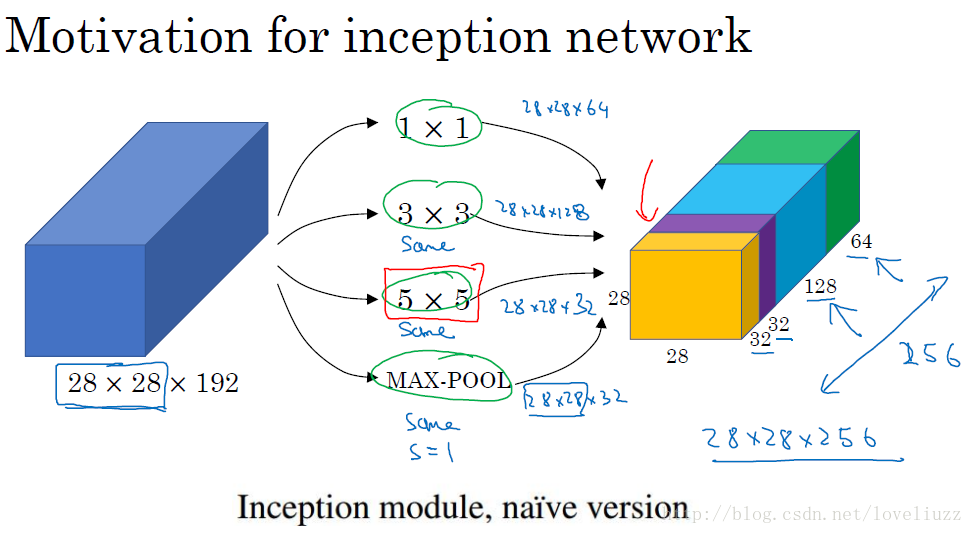
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结。
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1x1、3x3和5x5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding = 0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
4 . 网络越到后面特征越抽象,且每个特征涉及的感受野也更大,随着层数的增加,3x3和5x5卷积的比例也要增加。
最终版inception,加入了1x1 conv来降低feature map厚度:
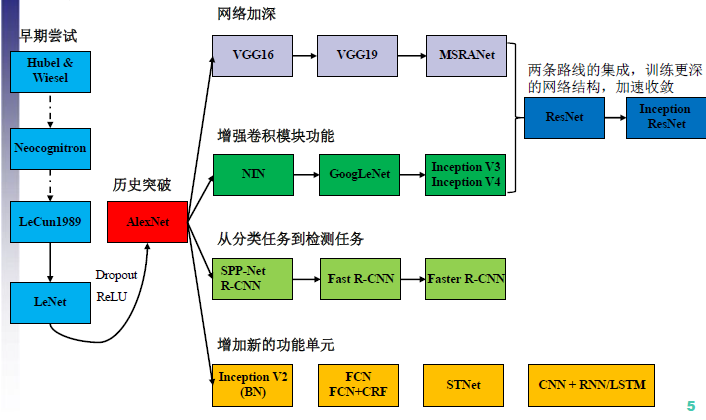
四、CNN结构演进
参考
1简介: https://www.cnblogs.com/vincentqliu/p/7467298.html
2 inception-v3模块详解:https://blog.csdn.net/loveliuzz/article/details/79135583
3 版本演化、各版论文:https://blog.csdn.net/u010402786/article/details/52433324