注:为了能系统性学习pandas,我这篇文章将会根据官网的文档结构结合工作中需求场景进行梳理。目的有三,一是尽量介绍全面,二是核心是能解决工作的需求,三是在特定需求下也能快速找到官网中的解决办法。
注:一般很少用series,以下一般只看dataframe。
官网:https://pandas.pydata.org/pandas-docs/stable/index.html
一、准备开始
——这部分主要介绍pandas的作用、数据结构和注意点等,可以大概看一眼有个印象即可。
1.1 Pandas包概述
pandas是一个Python包,提供快速、灵活和富有表现力的数据结构,旨在使处理“关系”或“标记”数据既简单又直观。它的目标是成为用Python进行实际的、真实的数据分析的基本高层构建块。此外,它还有一个更广泛的目标,即成为任何语言中可用的最强大、最灵活的开源数据分析/操作工具。它已经在朝着这个目标迈进。
pandas非常适合许多不同类型的数据:
具有不同类型列的表格数据,如在SQL表或Excel电子表格中
有序和无序(不一定是固定频率)时间序列数据。
具有行和列标签的任意矩阵数据(均匀类型或异构类型)
任何其他形式的观察/统计数据集。这些数据实际上根本不需要标记就可以放入panda数据结构中
pandas的两个主要数据结构Series(一维)和DataFrame(二维),能处理金融、统计、社会科学和许多工程领域的绝大多数典型用例。对于R用户,DataFrame提供了R的data.frame提供的所有内容,甚至更多。panda构建在NumPy之上,旨在与许多其他第三方库很好地集成在科学计算环境中。
以下是pandas擅长的几件事:
-易于处理浮点数据和非浮点数据中丢失的数据(用NaN表示)
-大小可变性:可以从DataFrame和高维对象中插入和删除列
-自动和显式数据对齐:对象可以显式对齐到一组标签上,或者用户可以简单地忽略标签,让Series、DataFrame等在计算中为您自动对齐数据
-功能强大、灵活的group by功能,可以对数据集执行拆分-应用-组合操作,用于聚合和转换数据
-简化将其他Python和NumPy数据结构中不规则的、不同索引的数据转换为数据aframe对象的过程
-基于智能标签的切片、花式索引和大型数据集的子集
-直观的合并和连接数据集
-数据集的灵活重设和旋转
-轴的分层标记(每块可能有多个标记)
-健壮的IO工具,用于从平面文件(CSV和分隔符)、Excel文件、数据库中加载数据,以及从超快HDF5格式中保存/加载数据
-时间序列特有的功能:日期范围生成和频率转换、移动窗口统计、移动窗口线性回归、日期移位和滞后等。
这里的许多原则都是为了解决使用其他语言/科学研究环境时经常遇到的缺点。对于数据科学家来说,处理数据通常分为多个阶段: 数据转换和清理,数据分析/建模,然后将分析结果组织成适合绘图或表格显示的形式。pandas是所有这些任务的理想工具。
其他一些笔记:
-pandas很快。Cython代码中对许多底层算法位进行了广泛的调整。然而,与其他任何泛化方法一样,泛化通常会牺牲性能。因此,如果您专注于应用程序的一个特性,您可能能够创建一个更快的专用工具。
-pandas是statsmodels库的依赖项,这使得它成为Python统计计算生态系统的重要组成部分。
-pandas已被广泛用于生产和金融应用。
1.2 数据结构
|
维数 |
名称 |
描述 |
|
1 |
Series |
一维相同类型的标签数组 |
|
2 |
DataFrame |
一般是二维标签,有大小可变的表格结构与潜在的不同类型列 |
为什么要有超过1种数据结构?
理解pandas数据结构的最佳方法是将其作为低维度数据的灵活容器。例如,DataFrame是Series的容器,Series是标量的容器。我们希望能够以类似词典的方式从这些容器中插入和删除对象。
此外,我们希望考虑时间序列和横断面数据集的典型方向的公共API函数的合理默认行为。当使用ndarrays存储2维和3维数据时,用户在编写函数时需要考虑数据集的方向;轴被认为或多或少是等价的(除非C或fortran关系到性能)。在pandas中,坐标轴的作用是赋予数据更多的语义;即,对于特定的数据集,可能有一种“正确”的方法来确定数据的方向。因此,目标是减少在下游函数中编码数据转换所需的脑力劳动。
例如,对于表格数据(DataFrame),考虑索引(行)和列比考虑轴0和轴1在语义上更有帮助。因此,遍历DataFrame的列会得到可读性更好的代码:
for col in df.columns:
series = df[col]
# do something with series
——意思是如果只有多维数组这种结构,我们遍历时得考虑数据维度的方向,而这种一维数组和维度平铺的二维数组的结构,在遍历维度(列)时就很好理解了。
数据的可变性和复制性
所有pandas数据结构都是值可变的(它们包含的值可以更改),但并不总是大小可变的。序列的长度不能更改,但是,例如,可以将列插入到DataFrame中。然而,绝大多数方法都会生成新的对象,并且不改变输入数据。一般来说,我们喜欢在合理的地方保持不变。
——意思是值都是可以更改的,但序列长度不能更改(?暂时不太清楚什么意思)。而且调用更改方法绝大多数不会改变原来的对象,而是得赋值给新的对象或赋值给原对象才能看到更新后的数据。
1.3 获得帮助
pandas问题和想法的第一站是ithub Issue Tracker。如果你有一个一般性的问题,熊猫社区的专家可以通过Stack Overflow来回答。
二、10分钟入门pandas
——这部分对pandas的各项功能做了简单介绍和示例,刚入门可以稍微看一下。但我需要按自己的需求思路梳理文档,所以这部分暂时不更。
按照惯例,我们这么引入:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
三、用户导引
——这部分是介绍pandas用法的主要章节,以下会按照我的需求梳理成文,适当调整结构并跳过一些暂不需要的内容。
3.0 应用背景
在进入这个章节前,我们首先思考以下几点,避免一味深入学pandas结果陷入不重要的细枝末节而浪费时间。
1.为什么学pandas?通过前面的介绍和你过往经验,你知道pandas大概能帮你做什么?
学pandas有两个原因,
一是初级分析师一般都是用Excel,当然好一点有类tableau工具,但Excel只能处理100w条记录并且在特征非常多时可能20w条不到就已经卡疯了,当需要灵活处理大量明细数据时,用pandas会比较方便(而不是用n多条SQL跑出一堆聚合数据,而且有时一条SQL的n多维度的聚合数据也能有几十万条记录);
二是在进行机器学习时,pandas在预处理上也更方便。
我大概了解到pandas可以做 数据IO、数据筛选转换、缺失值处理、group by、透视表、绘图等。
2.工作中的使用路径是怎样的?只要主要(覆盖80%使用场景)功能时,大概是这样的学习路径?
数据生成和写入(包括创建简单辅助表,读取csv文件)-
查看数据大概啥样、每列缺失值、简单描述统计(离散值每个值的分布,连续值直方图分布)、数据类型(看需不需要转换,特别是时间类型)-
缺失值或特殊条件赋值处理(缺失值处理好理解,特殊条件比如某个某些条件下的值错了或字符串改别名好理解)-
不同程度的筛选切片(比如某列、某行、某些行某些列、某行某列、某些条件)-
维度计算(比如连续数据分桶、多个维度根据某个判断逻辑生成一个新的维度、日期计算、字符串计算)-
度量计算(除了常见的聚合可能还有一些特定公式计算,参考SQL 的group by和Excel的透视表甚至tableau的度量计算逻辑)-
单特征或多特征绘图-
保存文件(写入csv文件,保存分析图表等)
3.在你学完这章节之后,review一下你pandas的使用路径,并介绍一下没深入的功能点和链接(学完后回答)?
以下是官网的目录,留个印象:
数据IO
索引和筛选
多重索引/高级索引
合并数据
重塑和透视表
文本数据处理
缺失数据处理
分类数据处理
可为空整数类型
可视化
计算工具
group by:分类-应用-结合
时间序列/日期功能
时间增减
风格
选项和设置
增强性能
稀疏数据结构
FAQ
cookbook
以下根据应用需求重塑章节框架和内容。
3.1 数据IO
1)创建数据
参考:https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html#object-creation
通过传入字典创建:


In [9]: df2 = pd.DataFrame({'A': 1.,
...: 'B': pd.Timestamp('20130102'),
...: 'C': pd.Series(1, index=list(range(4)), dtype='float32'),
...: 'D': np.array([3] * 4, dtype='int32'),
...: 'E': pd.Categorical(["test", "train", "test", "train"]),
...: 'F': 'foo'})
...:
In [10]: df2
Out[10]:
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
通过传入NumPy的多维数组创建:
In [5]: dates = pd.date_range('20130101', periods=6) In [6]: dates Out[6]: DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D') In [7]: df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD')) In [8]: df Out[8]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 2013-01-06 -0.673690 0.113648 -1.478427 0.524988
2)数据写入
参考:https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
pandas支持很多格式的IO,都是使用read和to的函数,如下:
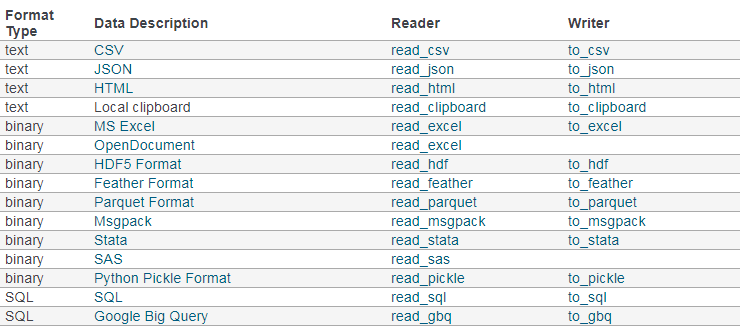
但为了快速掌握,这里先只介绍CSV的IO,其他有需要时再补充。
read_csv()
快捷代码:
函数参数众多,以下从不同使用场景考虑提供快捷代码。
#0.文件是正常CSV文件,且存在python本地,有表头
#————因为是默认以逗号分隔,表头自动推断。
df0= pd.read_csv('foo.cav')
#1.文件是正常的CSV文件(或以以逗号分隔的),有表头,存在在某个文件路径下
df1= pd.read_csv('E://data/foo.cav')
#2.文件是以以/t分隔的,有表头
df2= pd.read_csv('E://data/foo.txt',sep='s+')
df2= pd.read_csv('E://data/foo.txt',delim_whitespace=True)#这个比较管用
#3.文件没有表头,需要设置表头
#—————参数说明告诉我们设置names时要指定header=None,但不设置header也是可以的
df3=pd.read_csv('E://data/foo.csv',sep='s+',header=None,names=['id','姓名'])
#4.文件需要忽略源文件的第一行表头,重新设置表头
#————需要跳过skiprows第一行数据,并设置names
df4=pd.read_csv('E://data/foo.csv',sep='s+',header=None,skiprows=1,names=['id','姓名'])
常用参数:
3)数据输出
快捷代码:
#1.输出到某个路径文件
df.to_csv('E://data/foo.csv')
3.2 数据查看和格式转换
参考:https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html#viewing-data
1.查看前后几行(默认5行):
目的:一般是查看表结构,看导入结果是否正常。
In [13]: df.head() Out[13]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 In [14]: df.tail(3) Out[14]: A B C D 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 2013-01-06 -0.673690 0.113648 -1.478427 0.524988
2.缺失值处理和数据类型转换
1)查看空值数和数据类型:
目的:一般是看数据源每列空值是否存在异常,先考虑怎么处理;再看每列的数据格式是否是需要的,比如带千分位的数字、日期格式等会自动识别成字符类型(object),需要进行转换。
df.info() #结果 <class 'pandas.core.frame.DataFrame'> Index: 6 entries, a to f Data columns (total 4 columns): A 6 non-null float64 B 6 non-null float64 C 6 non-null float64 D 6 non-null float64 dtypes: float64(4) memory usage: 240.0+ bytes df.dtype #也可以查看每列数据类型
2)缺失值处理
缺失值处理有几种方式:
(1) 删除含缺失值的列;
df.dropna(axis=0)#删除确实值的行 dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)#inplace=False表示直接在df源数据上改而不是创建副本
(2)填充某个固定值;
df.fillna(0)#填充0 df.fillna(0['列名1':‘列名3’)#只对列名1:列名3的列处理 df['列名'].fillna(0) fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)#inplace=False表示直接在df源数据上改而不是创建副本
(3)填充该列均值、中位数;
df['列名'].fillna(df['列名'].mean())
(4)填充前一或后一值(适用于时间序列);
df['列名'].fillna(method='pad',limit=1)#填充前一行值,多个连续空值只填1个 df['列名'].fillna(method='bfill',limit=1)#填充后一行值,多个连续空值只填1个
(5)填充其他列对应值
df.loc[df['列名A'].isnull(),'列名A']=df[df['列名A'].isnull()][‘列名B’]
3)数据类型转换
pandas数据类型与Python/numpy数据类型对应表如下:

转换数据类型有几种方式:
(1).在pd.read_cav读取是通过设置dtype={'列名':‘’数据类型}或converters={'列名':‘’数据类型可调用函数}这俩参数进行设置;
(2).通过astype强制转化数据类型,格式为:df['列名'] =df['列名'].astype(‘数据类型’);
(3).通过创建自定义的函数或lamba列表推导式进行数据转化,再应用df['列名'].apply(可调用函数),这个方法可用于去除货币符号、逗号等转换成数值类型的操作;
(4).pandas提供的to_numeric()、to_datetime()等。
#将Jan Units列的coerce替换成0 df["Jan Units"]=pd.to_numeric(df["Jan Units"],errors='coerce').fillna(0) #将年月日三列合并成日期创建新列YMD df["YMD"]=pd.to_datetime(df[['Month', 'Day', 'Year']])
参考:https://www.cnblogs.com/onemorepoint/p/9404753.html
3.查看描述性统计
1)查看描述统计:
In [19]: df.describe()
Out[19]:
A B C D
count 6.000000 6.000000 6.000000 6.000000
mean 0.073711 -0.431125 -0.687758 -0.233103
std 0.843157 0.922818 0.779887 0.973118
min -0.861849 -2.104569 -1.509059 -1.135632
25% -0.611510 -0.600794 -1.368714 -1.076610
50% 0.022070 -0.228039 -0.767252 -0.386188
75% 0.658444 0.041933 -0.034326 0.461706
max 1.212112 0.567020 0.276232 1.071804
2)查看描述性绘图:
import matplotlib.pyplot as plt #3.查看描述性统计 #Xy.describe() #离散变量需要分组聚合,连续变量直接查看直方图 fig, axs = plt.subplots(5, 2, figsize=(20, 20)) Xy.groupby('a')['y'].count().plot.bar(title='a',ax = axs[0,0],color='K') Xy.groupby('b')['y'].count().plot.bar(title='b',ax = axs[0,1],color='K') Xy.groupby('c')['y'].count().plot.bar(title='c',ax = axs[1,0],color='K') Xy.groupby('d')['y'].count().plot.bar(title='d',ax = axs[1,1],color='K') Xy.groupby('e')['y'].count().plot.bar(title='e',ax = axs[2,0],color='K') Xy.groupby('f')['y'].count().plot.bar(title='f',ax = axs[2,1],color='K') Xy['g'].plot.hist(title='g',ax = axs[3,0],color='K') Xy['h'].plot.hist(title='h',ax = axs[3,1],color='K') Xy['i'].plot.hist(title='i',ax = axs[4,0],color='K') plt.show()
4.其他
查看索引和列名:
Xy.index
Xy.columns
df行列转置:
In [20]: df.T Out[20]: 2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06 A 0.469112 1.212112 -0.861849 0.721555 -0.424972 -0.673690 B -0.282863 -0.173215 -2.104569 -0.706771 0.567020 0.113648 C -1.509059 0.119209 -0.494929 -1.039575 0.276232 -1.478427 D -1.135632 -1.044236 1.071804 0.271860 -1.087401 0.524988
df格式转换:
#dataframe转成numpy的多维数组 In [18]: df2.to_numpy() Out[18]: array([[1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'test', 'foo'], [1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo'], [1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'test', 'foo'], [1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo']], dtype=object)
df复制:
dfa = df.copy()
3.3 数据筛选切片
1)【查】排序
一般我们习惯看原始数据以及聚合后的最大最小值,方便大概看异常值情况。
其中,聚合后即group by/pivot方法里也有排序参数,但其结果本身也是多重索引的dataframe,也可以通过赋值副本利用下面的方法重新排序。
| DF排序 | |||
| 功能 | 函数/方法 | 语法 | 常用参数 |
| 按轴(索引名或列名)排序 | DataFrame.sort_index |
DataFrame.sort_index(self[, axis, level, …]) |
axis: (0 or ‘index’, 1 or ‘columns’)对行还是对列排序。0即对索引进行排序,1即对列名排序,默认0; ascending:默认True升序; level:(int or level name or list of ints or list of level names)多重索引时,可指定排序的索引。 |
| 按某列或某些列排序 | DataFrame.sort_values | DataFrame.sort_values(self, by[, axis, …]) |
axis: (0 or ‘index’, 1 or ‘columns’)对行还是对列排序。0即对索引进行排序,1即对列名排序,默认0; by : (str or list of str)要排序的名称或名称列表。 如果axis是0或' index ',那么by可能包含索引级别和/或列标签 如果axis是1或' columns ',那么by可能包含列级别和/或索引标签 ascending:(bool or list of bool, default True)升序排序和降序排序。为多个排序顺序指定列表。如果这是一个布尔列表,则必须匹配by的长度。 inplace : (bool, default False)如果true,则修改原始数据,而不是建立副本。 na_position: {' first ', ' last ' default ' last '},NaN的位置,first 把NaNs放在开头;last 把NaNs放在最后。 |
#最常用的是对索引排序
df.sort_index()
#对列排序,很少有这样的
In [21]: df.sort_index(axis=1, ascending=False) Out[21]: D C B A 2013-01-01 -1.135632 -1.509059 -0.282863 0.469112 2013-01-02 -1.044236 0.119209 -0.173215 1.212112 2013-01-03 1.071804 -0.494929 -2.104569 -0.861849 2013-01-04 0.271860 -1.039575 -0.706771 0.721555 2013-01-05 -1.087401 0.276232 0.567020 -0.424972 2013-01-06 0.524988 -1.478427 0.113648 -0.673690
#按某列值排序
In [22]: df.sort_values(by='B')
Out[22]:
A B C D
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
#按某两列值排序
df.sort_values(by=['col1', 'col2'])
col1 col2 col3
1 A 1 1
0 A 2 0
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4
2)【查】简单筛选
简单的筛选包括选取某列、某些列、某行、某些行、某行某列、某些行(连续或不连续)某些列(连续或不连续)。
这里先介绍pandas的几种索引方式,再通过实例比较说明。
| DF几种索引方式 | |||||||||||||
| 功能 | 函数/方法 | 语法 | 描述 | 常用参数 | |||||||||
| 选择某列某些列 | df[] |
|
使用[]建立索引的主要功能是选择低维切片,相当于类里面的getitem__方法。 1)其中,由于dataframe是有多个series列构成,所以也可以通过df[][]访问某个具体的值,但不推荐这样链式访问,有时候会出问题。 |
1.一个列名,df['A']; |
|||||||||
| 选择某列 | df.列名 | df.列名 |
dataframe的每列也是属性,可以使用属性访问的方式访问某列。 1)注意,不要通过属性访问方式创建新列,这样只会创建一个新的属性,并不会创建新列,例如df.E=5并不能创建E列。 |
无 |
|||||||||
| 按标签(名称)任意索引切片 | df.loc[] |
|
主要是基于标签的,但也可以与布尔数组一起使用。 1)一般格式为df.loc[:,:],逗号前是行索引,逗号后是列索引,逗号不可省,行索引不可为无(可以是空片:); 2)要求的每个标签必须在索引中,否则将引发密钥错误。在进行切片时,如果索引中有开始边界和停止边界,则开始边界和停止边界都包括在内; 3)整数是有效的标签,但是它们引用的是标签而不是位置。 |
indexer/row_indexer/column_indexer可以是: |
|||||||||
| 按索引位置任意索引切片 | df.iloc[] |
|
主要是基于整数位置的(从0开始)的,但也可以与布尔数组一起使用。 1)格式同上,但切片时不含上界,即1:4返回的是第2到第3。 |
indexer/row_indexer/column_indexer可以是: |
|||||||||
| 按标签(名称)索引某行某列 | df.at[] |
df.at[ScalarAccessIndexer] |
基于标签,索引某一行某一列。 1)取某一行某一列的值,速度比df.loc[]快一点。 |
df.at[2,'B'] | |||||||||
| 按索引位置索引某行某列 | df.iat[] |
df.iat[ScalarAccessIndexer] |
基于整数位置,索引某一行某一列。 1)取某一行某一列的值,速度比df.loc[]快一点。 |
df.at[2,2] | |||||||||
#下面实例用到的DataFrame In [44]: df1 = pd.DataFrame(np.random.randn(6, 4), ....: index=list('abcdef'), ....: columns=list('ABCD')) ....: In [45]: df1 Out[45]: A B C D a 0.132003 -0.827317 -0.076467 -1.187678 b 1.130127 -1.436737 -1.413681 1.607920 c 1.024180 0.569605 0.875906 -2.211372 d 0.974466 -2.006747 -0.410001 -0.078638 e 0.545952 -1.219217 -1.226825 0.769804 f -1.281247 -0.727707 -0.121306 -0.097883
| 实例 | df[] | df.A | df.loc[] | df.iloc[] | df.at[] | df.iat[] |
| 选择某1列 | df['B'] | df.B | df.loc[:,'B'] | df.iloc[:,1] | - | - |
| 选择某些连续列 | 列名需要枚举,用法同选择某些不连续列 | - | df.loc[:,'B':'D'] | df.iloc[:,1:4] | - | - |
| 选择某些不连续列 | df[['B','D']] | - | df.loc[:,['B','D']] | df.iloc[:,[1,3]] | - | - |
| 选择某1行 | - | - | df.loc['b'] | df.iloc[1] | - | - |
| 选择某些连续行 | - | - | df.loc['b':'d'] | df.iloc[1:4] | - | - |
| 选择某些不连续行 | - | - | df.loc[['b','d']] | df.iloc[[1,3]] | - | - |
| 选择某些连续行某些连续列 | - | - | df.loc['b':'d','B':'D'] | df.iloc[1:4,1:4] | - | - |
| 选择某些不连续行某些不连续列 | - | - | df.loc[['b','d'],['B','D']] | df.iloc[[1,3],[1,3]] | - | - |
| 选择某1行某1列 |
df['B']['b'] |
df.B.b | df.loc['b','B'] | df.iloc[1,1] | df.at['b','B'] | df.iat[1,1] |
#你也可以将一个dict赋值给一个DataFrame的行 In [24]: x = pd.DataFrame({'x': [1, 2, 3], 'y': [3, 4, 5]}) In [25]: x.iloc[1] = {'x': 9, 'y': 99} s[::2]#这是一种不知道的方式,看起来是以2step索引 df[::-1]#显然这是一个倒序输出
#布尔数组长度要匹配相应的行或列长度
In [49]: df1.loc['a'] > 0
Out[49]:
A True
B False
C False
D False
Name: a, dtype: bool
In [50]: df1.loc[:, df1.loc['a'] > 0]
Out[50]:
A
a 0.132003
b 1.130127
c 1.024180
d 0.974466
e 0.545952
f -1.281247
3)【查】复杂筛选
简单筛选的实例都是比较简单的场景,但事实上在实际应用中,直接索引切片的情况很少,顶多是选择某些列(某列有意义的特征)。更多时候我们需要筛选某些列条件得到子集进行其他动作,或者进行维度计算。所以这里要继续介绍前面没太提及的布尔数组参数、可调用函数参数,以及query()方法、where()方法、isin、get()方法、lookup()方法、随机选择等。
3.4 维度计算(计算列)
注:光看官网文档很难按我的需求总结,所以大多先搜索需要的案例,后续再扩展梳理。ps.用bing英文搜索非常有效,很多我需要的都在stackoverflow有类似案例,尤其国外的回答者还喜欢列出不同的解决方案及每种方案的耗时,非常方便。
1)【增】无条件增加辅助列
2)【增】按条件增加列
增加一列,判断某列为空时赋值为0,不为空时赋值为1:
(1.用于将不必细分的特征改成二分类特征)
3)【删】删除行列
删除列:
del Xy['列名']
4)【改】无条件改值
4)【改】按条件改值
5)字符串处理
6)日期计算
获取datetime64类型列的年月:
(1.用于看年月分布,因为年月日粒度太细了)
计算两列日期的差值或与某一固定日期的差值:
(1.用于重构时间特征,很多场景下,日期并不是有效特征,日期差值才是。例如最后活跃日期需要改成最后一次活跃日期距今天数。)
#以下,a1列和a2列都是datetime类型 #计算a1-a2日期差 df['a']=(df['a1'] - df['a2'])/pd.offsets.Day(1) df['a']=(df['a1'] - df['a2']).dt.days #计算2019-03-31与a1列日期差 df['a']=(pd.to_datetime('31-03-2019')-df['a1'])/pd.offsets.Day(1)
另,计算日期差的月值参考:
https://stackoverflow.com/questions/37078370/pandas-function-equivalent-to-sqls-datediff#
3.5 度量计算(计算度量)
1)groupby
df = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'], 'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': np.random.randn(8), 'D': np.random.randn(8)})
df.groupby('A').count()#按A列分组,对其他列进行count计算
df.groupby('A')['A'].count()#按A列分组,对A列进行count计算
df.groupby('A')['C'].sum()#按A列分组,对C列进行sum计算
df.groupby('A')['C'].agg(['count', 'sum'])#按A列分组,对C列进行count和sum计算
df.groupby(['A','B'])['C'].agg(['count', 'sum'])#按AB列分组,对C列进行count和sum计算
df.groupby(['A','B'])['C','D'].agg(['count', 'sum'])#按AB列分组,对CD列进行count和sum计算
df.groupby(['A','B'])['C','D'].agg(['count', 'sum']).reset_index()#按AB列分组,对CD列进行count和sum计算,并将索引平铺
常用的聚合函数:
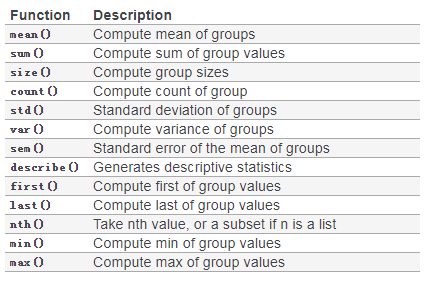
In [91]: bb = pd.read_csv('data/baseball.csv', index_col='id')
In [92]: (bb.groupby(['year', 'team']).sum()
....: .loc[lambda df: df.r > 100])
....:
Out[92]:
stint g ab r h X2b X3b hr rbi sb cs bb so ibb hbp sh sf gidp
year team
2007 CIN 6 379 745 101 203 35 2 36 125.0 10.0 1.0 105 127.0 14.0 1.0 1.0 15.0 18.0
DET 5 301 1062 162 283 54 4 37 144.0 24.0 7.0 97 176.0 3.0 10.0 4.0 8.0 28.0
HOU 4 311 926 109 218 47 6 14 77.0 10.0 4.0 60 212.0 3.0 9.0 16.0 6.0 17.0
LAN 11 413 1021 153 293 61 3 36 154.0 7.0 5.0 114 141.0 8.0 9.0 3.0 8.0 29.0
NYN 13 622 1854 240 509 101 3 61 243.0 22.0 4.0 174 310.0 24.0 23.0 18.0 15.0 48.0
SFN 5 482 1305 198 337 67 6 40 171.0 26.0 7.0 235 188.0 51.0 8.0 16.0 6.0 41.0
TEX 2 198 729 115 200 40 4 28 115.0 21.0 4.0 73 140.0 4.0 5.0 2.0 8.0 16.0
TOR 4 459 1408 187 378 96 2 58 223.0 4.0 2.0 190 265.0 16.0 12.0 4.0 16.0 38.0
2)pivot
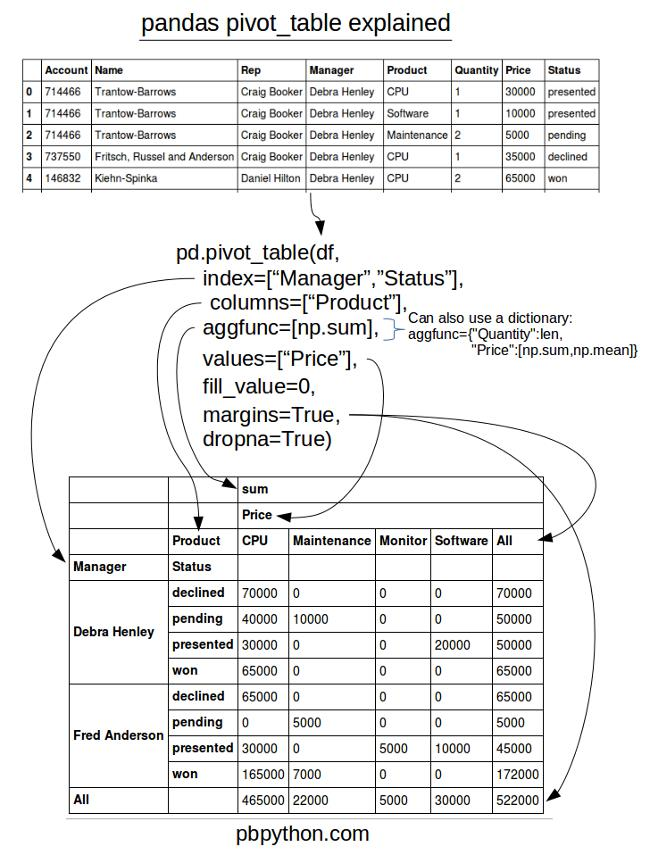
3.6 可视化
1.基础绘图:
dateframe的plot()方法是对plt.plot()的简单封装。
| 功能 | 语法 | 描述 | 常用参数 |
| 折线图 |
df.plot() |
默认索引列是横轴,值是纵轴,列是图例(多列则是多条线) 1)可以对一列调用,此时索引是横轴,值是纵轴,列只有一个即1条折线,例如 df['列名'].plot() |
df.plot(x='A', y='B')#可以指定横轴和纵轴,此时未指定的列不参与绘图 |
| 条形图 |
df.plot.bar() df.plot(kind='bar') |
默认索引列是横轴,值是纵轴,列是图例(多列则是多条条形) 1)也可以对一行数据调用,此时列是横轴,值是纵轴,无图例,例如 df.iloc[5].plot.bar() |
stacked=True#即堆积条形图,多个图例堆积成1条 |
| 横向条形图 |
df.plot.barh() df.plot(kind='barh') |
同条形图,只是方向是横向。 | |
| 直方图 |
df4.plot.hist() df.plot(kind='hist') |
默认值的值域是横轴,值的频数是纵轴,列是图例(多列则是个重叠直方图) 1)可以对一列调用,此时索引是横轴,值是纵轴,列只有一个即1条折线,例如 df['列名'].plot.hist() |
by=#不知道是啥 alpha=0.5 stacked=True#即堆积直方图,多个图例堆在一个直方图上 bins=20#分组数量,默认是10 orientation='horizontal'#横向直方图 cumulative=True#累积直方图 |
import matplotlib.pyplot as plt fig, axs = plt.subplots(5, 2, figsize=(20, 20)) axs[0, 0].bar(Xy.groupby('subject')['teacher_id'].count()) axs[0, 0].set_title('subject') plt.show() import matplotlib.pyplot as plt #3.查看描述性统计 #Xy.describe() #离散变量需要分组聚合,连续变量直接查看直方图 fig, axs = plt.subplots(5, 2, figsize=(20, 20)) Xy.groupby('a')['y'].count().plot.bar(title='a',ax = axs[0,0],color='K') Xy.groupby('b')['y'].count().plot.bar(title='b',ax = axs[0,1],color='K') Xy.groupby('c')['y'].count().plot.bar(title='c',ax = axs[1,0],color='K') Xy.groupby('d')['y'].count().plot.bar(title='d',ax = axs[1,1],color='K') Xy.groupby('e')['y'].count().plot.bar(title='e',ax = axs[2,0],color='K') Xy.groupby('f')['y'].count().plot.bar(title='f',ax = axs[2,1],color='K') Xy['g'].plot.hist(title='g',ax = axs[3,0],color='K') Xy['h'].plot.hist(title='h',ax = axs[3,1],color='K') Xy['i'].plot.hist(title='i',ax = axs[4,0],color='K') plt.show()
四、pandas生态圈
——这部分介绍pandas相关的库,及相互间如何合作以达成什么目的。
五、API目录
——这部分是pandas库的每个方法、类、函数等的用法,不会太怎么介绍,看情况。
六、发展
——这部分暂时不知道,先不管。
七、版本更新
——这部分是版本更新内容,初期不需要看,等涉及版本问题查一下即可。