关键字:人工智能,神经网络,感知器模型
Production system
Abstract: Putting forward along with the computing intelligence, artificial neural network has been developing. At present the industry considering the neural network (NN) classified as artificial intelligence (AI) may not appropriate, and classified as computational intelligence (CI) more telling. Evolutionary computation, artificial life, and some issues of the fuzzy logic system, are classified as computational intelligence. Despite the limits of computational intelligence and artificial intelligence is not obvious, however, discuss the difference and relationship is beneficial, logical thinking refers to the process according to the rules of logic reasoning; It will first information into the concept and symbol, and then, according to the symbolic operation logic reasoning according to the serial mode; This process can be written as a serial of instruction, let the computer to perform. However, visual thinking is the distributed storage of information together, the result is suddenly an idea or a solution to the problem. And this paper is devoted to general thoughts about neural network processing, as well as computer science and technology under the junior professional class "artificial intelligence" of the fourth algorithm experiment.
Keywords: Artificial intelligence, neural network, the perceptron model
1,神经网络的发展
1.1 连接主义观点核心
智能的本质是连接机制,神经网络是一个由大量简单的处理单元组成的高度复杂的大规模非线性自适应系统。
1.2 模拟人脑的智能行为的四个层面
•物理结构
•计算模拟
•存储与操作
•训练
1.3人工神经网络
神经网络是一个并行和分布式的信息处理网络。它是以处理单元为节点,用加权有向弧相互连接而成的有向图。处理单元是对生理神经元的模拟,而有向弧是对轴突-突触-树突对的模拟。有向弧的权重表示两处理单元间相互作用的强弱。它一般由大量神经元组成
•每个神经元只有一个输出,可以连接到很多其他的神经元
•每个神经元输入有多个连接通道,每个连接通道对应于一个连接权系数
2.模型的建立
2.1 人工神经网络模型
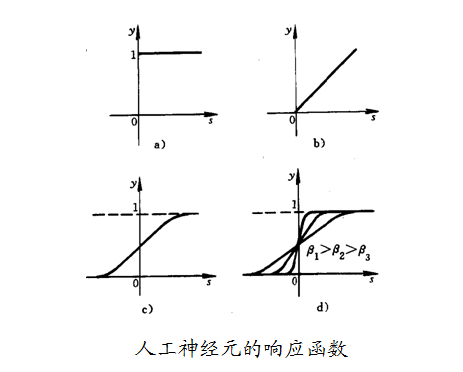
2.2 响应函数的基本作用
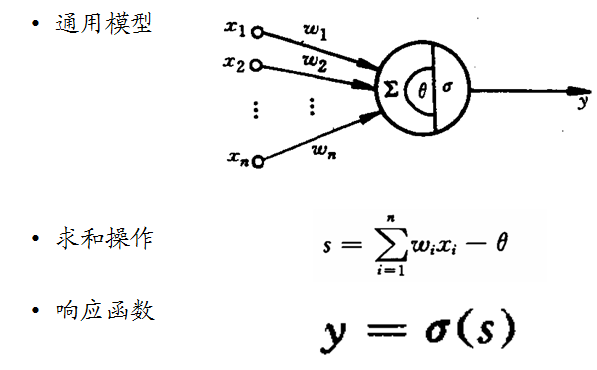
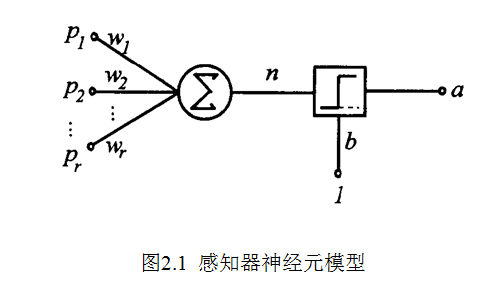
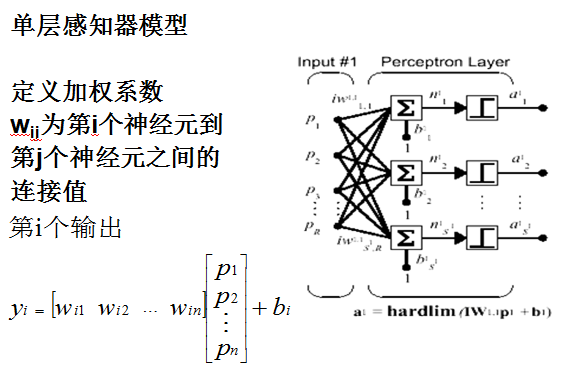
2.3 感知器模型

感知器是由美国计算机科学家罗森布拉特(F.Roseblatt)于1957年提出的。单层感知器神经元模型图:
2.4数学模型
3.感知器算法
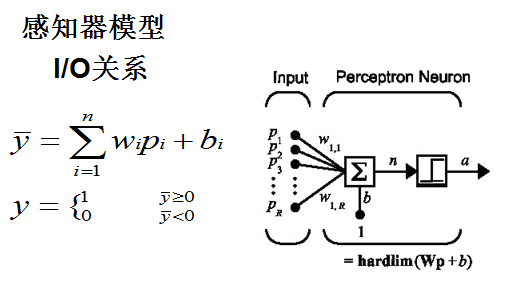
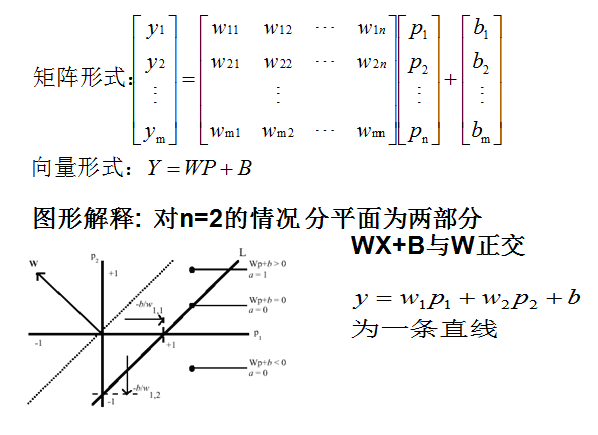
3.1训练步骤
1)对于所要解决的问题,确定输入向量 X,目标向量T,由此确定维数及网络结构参数,n,m;
2) 参数初始化;
3)设定最大循环次数;
4)计算网络输出;
5)检查输出矢量Y与目标矢量T是否相同,如果相同,或以达最大循环次数,训练结束,否则转入6;
6)学习,并返回4。
3.2网络训练
自适应线性元件的网络训练过程可以归纳为以下三个步骤:
1)表达:计算模型的输出矢量A=W*P十B,以及与期望输出之间的误差E=T—A;
2)检查:将网络输出误差的平方和与期望误差相比较,如果其值小于期望误差,或训练已达到事先设定的最大训练次数,则停止训练;
3)学习:采用W—H学习规则计算新的权值和偏差,并返回到1)。
4,问题引入
4.1问题描述
现在来考虑一个较大的多神经元网络的模式联想的设计问题。输入矢量和目标矢量分别为:
P=
{
{1,-1,2},
{1.5,2,1},
{1.2,3,-1.6},
{-0.3,-0.5,0.9}
};
T=
{
{0.5,1.1,3,-1},
{3,-1.2,0.2,0.1},
{-2.2,1.7,-1.8,-1.0},
{1.4,-0.4,-0.4,0.6}
};
4.2解题思路
由输入矢量和目标输出矢量可得:输入向量个数 r=3,输出向量个数 s=4,样本数 q=4。
这个问题的求解同样可以采用线性方程组求出,即对每一个输出节点写出输入和输出之间的关系等式。
实际上要求出这16个方程的解是需要花费一定的时间的,甚至是不太容易的。
对于一些实际问题,常常并不需要求出其完美的零误差时的解。也就是说允许存在一定的误差。
在这种情况下,采用自适应线性网络求解就显示出它的优越性:因为它可以很快地训练出满足一定要求的网络权值。
5,程序设计
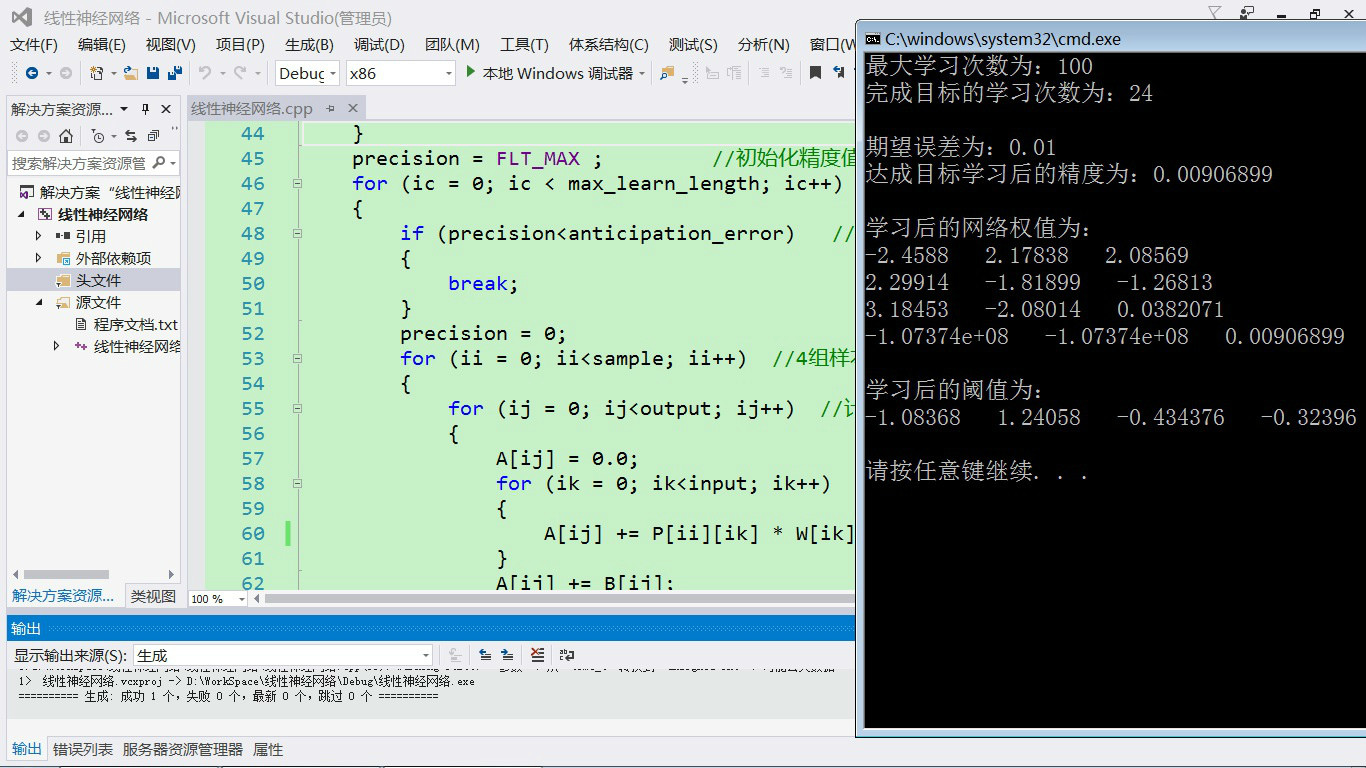
1 #include<iostream> 2 #include<ctime> 3 #include<cmath> 4 using namespace std; 5 6 const int max_learn_length = 100; //最大学习次数 7 const float study_rate = 0.2; //学习率 8 const float anticipation_error = 0.01; //期望误差 9 const int input = 3; //三项输入 10 const int output = 4; //四项输出 11 const int sample = 4; //4组样本 12 13 float P[sample][input] = //4组3项的输入矢量 14 { 15 {1,-1,2}, 16 {1.5,2,1}, 17 {1.2,3,-1.6}, 18 {-0.3,-0.5,0.9} 19 }; 20 float T[sample][output] = //4组4项的期望输出矢量 21 { 22 {0.5,1.1,3,-1}, 23 {3,-1.2,0.2,0.1}, 24 {-2.2,1.7,-1.8,-1.0}, 25 {1.4,-0.4,-0.4,0.6} 26 }; 27 28 int main(int argc, char **argv) 29 { 30 float precision; //误差精度变量 31 float W[input][sample]; //3项4组输入对应的网络权值变量 32 float B[sample]; //4组阈值变量 33 float A[sample]; //每组实际输出值 34 int ii, ij, ik, ic; 35 36 srand(time(0)); //初始化随机函数 37 for (ii = 0; ii<sample; ii++) 38 { 39 B[ii] = 2 * (float)rand() / RAND_MAX - 1; //阈值变量赋随机值(-1,1) 40 for (ij = 0; ij<input; ij++) //网络权值变量赋随机值 41 { 42 W[ij][ii] = 2 * (float)rand() / RAND_MAX - 1; 43 } 44 } 45 precision = FLT_MAX ; //初始化精度值 46 for (ic = 0; ic < max_learn_length; ic++) //最大学习次数内循环 47 { 48 if (precision<anticipation_error) //循环剪枝函数 49 { 50 break; 51 } 52 precision = 0; 53 for (ii = 0; ii<sample; ii++) //4组样本循环叠加误差精度 54 { 55 for (ij = 0; ij<output; ij++) //计算一组中4项实际的输出 56 { 57 A[ij] = 0.0; 58 for (ik = 0; ik<input; ik++) 59 { 60 A[ij] += P[ii][ik] * W[ik][ij]; 61 } 62 A[ij] += B[ij]; 63 } 64 for (ij = 0; ij<output; ij++) //通过学习率调整网络权值和阈值 65 { 66 for (ik = 0; ik<input; ik++) 67 { 68 W[ik][ij] += study_rate*(T[ii][ij] - A[ij])*P[ii][ik]; 69 } 70 B[ij] += study_rate*(T[ii][ij] - A[ij]); 71 } 72 for (ij = 0; ij<output; ij++) //计算误差精度 73 { 74 precision += pow((T[ii][ij] - A[ij]),2); 75 } 76 } 77 } 78 cout << "最大学习次数为:" << max_learn_length << endl; 79 cout << "完成目标的学习次数为:" << ic << endl; 80 cout << endl << "期望误差为:" << anticipation_error << endl; 81 cout << "达成目标学习后的精度为:" << precision <<endl<< endl; 82 cout << "学习后的网络权值为:" << endl; 83 for (ii = 0; ii<sample; ii++) //输出学习后的网络权值 84 { 85 for (ij = 0; ij<input; ij++) //4组样本每组3个输入 86 { 87 cout << W[ii][ij] << " "; 88 } 89 cout << endl; 90 } 91 cout <<endl<< "学习后的阈值为:" << endl; 92 for (ii = 0; ii<output; ii++) //输出学习后的阈值:四个样本输出 93 { 94 cout << B[ii] << " "; 95 } 96 cout << endl<<endl; 97 system("pause"); 98 return 0; 99 }