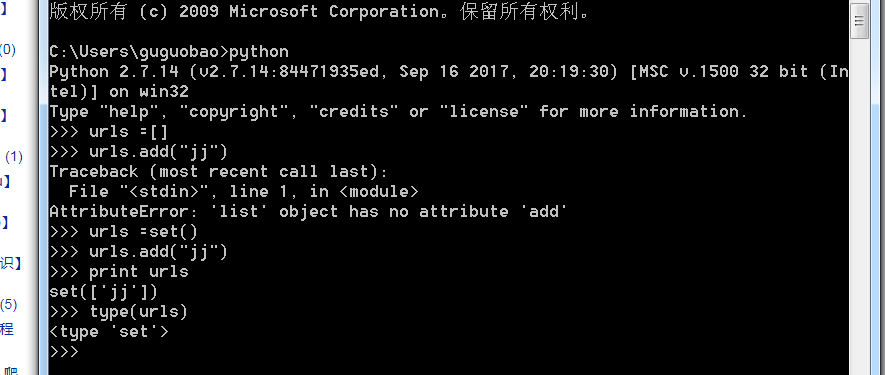
当使用爬虫URL保存时,一般会选择set来保存urls,set是集合,集合中的元素不能重复,其次还有交集,并集等集合的功能,
爬虫每次获取的网页中提取网页中的urls,并保存,这就需要利用urls = set()
#coding:utf-8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def parser(self,page_url,html_cont):
'''
用于解析网页内容抽取URL和数据
:param page_url: 下载页面的URL
:param html_cont: 下载的网页内容
:return:返回URL和数据
'''
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data
def _get_new_urls(self,page_url,soup):
'''
抽取新的URL集合
:param page_url: 下载页面的URL
:param soup:soup
:return: 返回新的URL集合
'''
new_urls = set()
#抽取符合要求的a标签
#原书代码
# links = soup.find_all('a',href=re.compile(r'/view/d+.htm'))
#2017-07-03 更新,原因百度词条的链接形式发生改变
links = soup.find_all('a', href=re.compile(r'/item/.*'))
for link in links:
#提取href属性
new_url = link['href']
#拼接成完整网址
new_full_url = urlparse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
'''
抽取有效数据
:param page_url:下载页面的URL
:param soup:
:return:返回有效数据
'''
data={}
data['url']=page_url
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title']=title.get_text()
summary = soup.find('div',class_='lemma-summary')
#获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
data['summary']=summary.get_text()
return data
- 其次需要注意的是set可以add,而list不可以