解压过后:
[hadoop@master CDH5.3.6]$ ls -rlt
total 8
drwxr-xr-x. 17 hadoop hadoop 4096 Jun 2 16:07 hadoop-2.5.0-cdh5.3.6
drwxr-xr-x. 11 hadoop hadoop 4096 Jun 2 16:28 hive-0.13.1-cdh5.3.6
1.配置hive-env.sh
export JAVA_HOME=/usr/local/jdk1.8 export HADOOP_HOME=/home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6 export HIVE_HOME=/home/hadoop/CDH5.3.6/hive-0.13.1-cdh5.3.6 export HIVE_CONF_DIR=/home/hadoop/CDH5.3.6/hive-0.13.1-cdh5.3.6/conf
2.配置hive-log4j.properties
hive.log.dir=/home/hadoop/CDH5.3.6/hive-0.13.1-cdh5.3.6/log
3.配置hive-site.xml
这个寻找Apache-hadoop下的就可以,直接考过来就可以,在conf 目录下
4.配置环境变量
vi .bash_profile
export HADOOP_HOME=/home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HIVE_HOME=/home/hadoop/CDH5.3.6/hive-0.13.1-cdh5.3.6 export HADOOP_INSTALL=$HADOOP_HOME export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$MAVEN_HOME/bin:$HIVE_HOME/bin
5.拷贝MySQL包
cp /home/hadoop/hive/lib/mysql-connector-java-5.1.46.jar ./
6.hive命令报错:
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
解决方法:
格式化MySQL:
schematool -dbType mysql -initSchema
7.进入hive
hive (default)> > CREATE TABLE dept( > deptno int, > dname string, > loc string) > ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile; OK Time taken: 0.57 seconds
8.准备数据:
vi detp.txt 10,ACCOUNTING,NEW YORK 20,RESEARCH,DALLAS 30,SALES,CHICAGO 40,OPERATIONS,BOSTON
9.装数据:
load data local inpath '/home/hadoop/tmp/detp.txt' overwrite into table dept;
10.查询:
hive (default)> select count(1) from dept; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1559517371869_0001, Tracking URL = http://master:8088/proxy/application_1559517371869_0001/ Kill Command = /home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/bin/hadoop job -kill job_1559517371869_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-06-02 17:13:27,541 Stage-1 map = 0%, reduce = 0% 2019-06-02 17:13:33,988 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.79 sec 2019-06-02 17:13:40,268 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.7 sec MapReduce Total cumulative CPU time: 1 seconds 700 msec Ended Job = job_1559517371869_0001 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 1.7 sec HDFS Read: 292 HDFS Write: 101 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 700 msec OK _c0 4 Time taken: 22.14 seconds, Fetched: 1 row(s)
页面验证:
http://192.168.1.30:8088/cluster
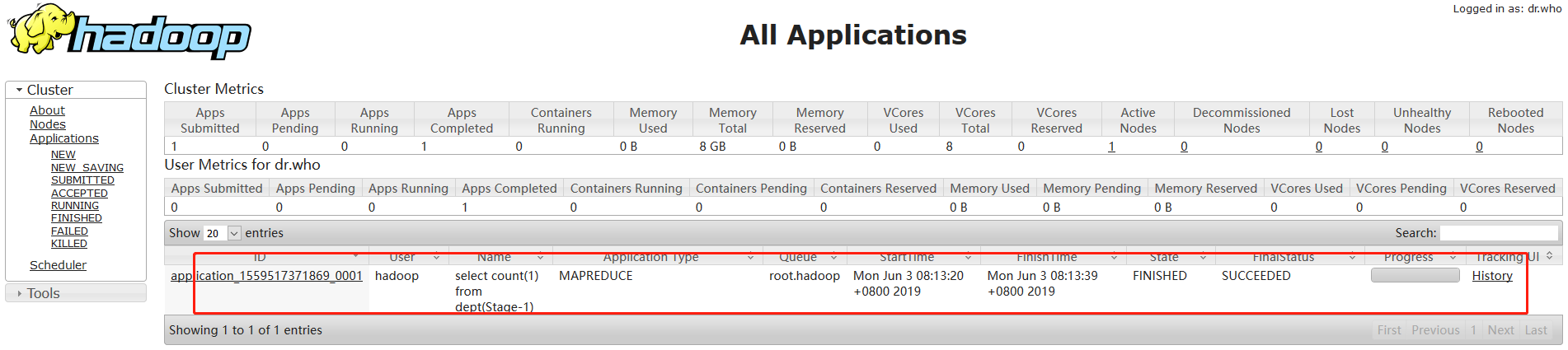
http://192.168.1.30:50070/dfshealth.html#tab-overview