一、本单元两次作业架构设计
(1)第一次作业
1.设计思路
这是UML的第一次作业,核心是理清UML的class、attribute这些元素之间的关系。这次作业的难度其实不是很大,但是代码量很多。
结构上:
main和MyUmlInteraction这两个必要的类。
接着是一个grops类,这个类是对elements里面的元素进行分类存放、通过id查找和通过关联进行组合的地方,是整个project的核心,同样单独出来而没有放到MyUmlInteraction类中,一个是进行脱耦,减少后续重构、修改的麻烦,另一个是防止一个类的行数太多太过臃肿。在这里面分类存放元素的时候,因为元素之间是是通过id进行关联和查找的,所以使用了很多的hashmap存放id和不同元素的对应关系,id和name的对应关系。由于使用的是name查找对应的class,而且有重名的可能,所以通过hashmap存放name和class、name和出现次数的对应关系。
接着是一些数据类,由于Umlinterface和UmlClass都有attribute、operation、association这些类,所以我建立了一个抽象类MyElement,将添加attribute、operation、association这些通用操作放进去,由于umlClass和UmlInterface的继承是不一样的,class只能单继承,interface可以有多继承,所以继承、实现这些class和interface像区别的操作,我建立了MyUmlClass和MyInterface这两个继承MyElement的类写这些对应数据结构和相关的函数。而且与继承和实现相关的整理方法,也是在各自的子类中实现。具体到存放的数据结构中,涉及查找的attrbute和operation,跟grops类中一样,使用hashmap存放name和对应元素、name和出现次数的对应关系。
由于作业提供的Association、AssociationEnd类相互独立,所以我新建了一个MyAsso类将两者结合起来,MyAsso类存放association和对应的两个associationEnd。
MyOperation类,同样由于operation和parameter类是分离的,我需要新建一个MyOperation类对operation和相关的parameter组合存放,同时根据存放的parameter确定operation的类型。
具体实现的方法上:
由于我不想建立一个空的类来暂时指代还没有读入的元素,防止出现空指针异常,我是先遍历一遍elements进行分类再将相关联的元素组合起来的操作。MyUmlInteracition类中的创建函数就就是通过element的getElenmentType函数将不同的元素区分开,然后调用grops类里面对应的添加函数添加到grops中。将elements分类添加之后,调用grops里面对应的函数,通过id将AssociationEnd和对应的Association组合起来、parameter和对应的operation组合起来,将attribute、operation和association添加到对应的class和interface中,通过generation将子类和父类组合起来,最后在通过UmlInterfaceRealization将类和接口的实现关系建立起来。
到具体的方法实现上面,首先是重名和不存在异常方面,由于添加的时候就记录了class、attribute这些需要查询的元素的name和次数的关系,先查询是否存在对应的name,如果存在查询是否对应的次数为一。由于实现关系会让class实现对应接口所继承的所有接口,继承关系会让子类继承所有父类的attribute、operation、association和实现的接口,所以设计了一个整理函数和一个标记位,通过标记位记忆是否整理,在查询的时候整理。这样可以节省一些时间复杂度。具体的对于类来说,则是一路找到对应的顶层父类或者已经整理过的父类,将父类的attribute、operation等逐级添加下来;对于接口,则是要遍历父类,逐级逐个将父类的id添加到结构为hashset的id池中。
2.代码结构
具体的类之间的关系如下图所示
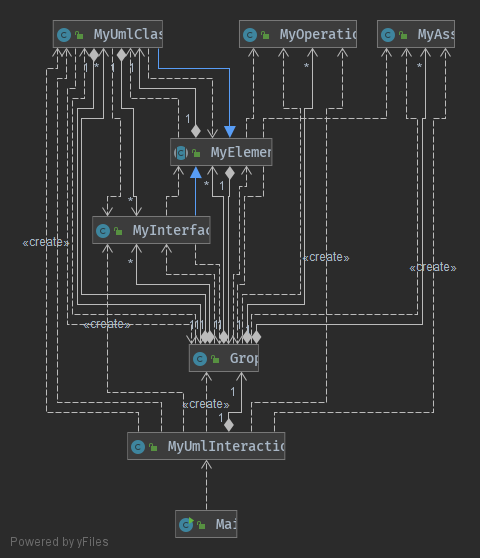
因为所要存储的信息比较多,所以相对复杂。虽然已经相对有层次了而且也有一定的脱耦了,但是还是有些可以改进的地方,可以看到,新建MyAsso和MyOperation类是在MyUmlInteracition中进行的,应该把它放到grops类里面,MyUmlInteracition类只负责识别和调用就行了。此外,在grops、MyUmlClass里面放一些返回值是boolean的函数用来查询重名和不存在这些情况,统一在MyUmlInteracition中抛出异常会更好。更具体如下图所示
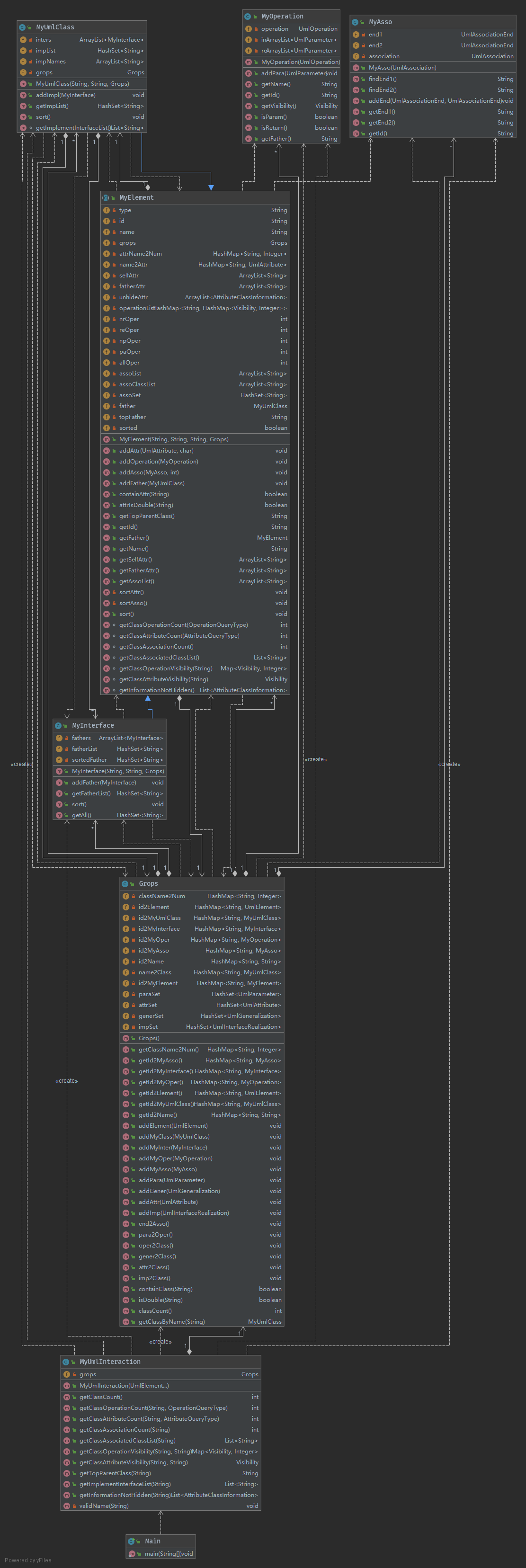
3.结构分析
方法分析如下图所示,由于方法比较多,而且大部分是非常简单的数据修改和访问方法,所以只截取一部分
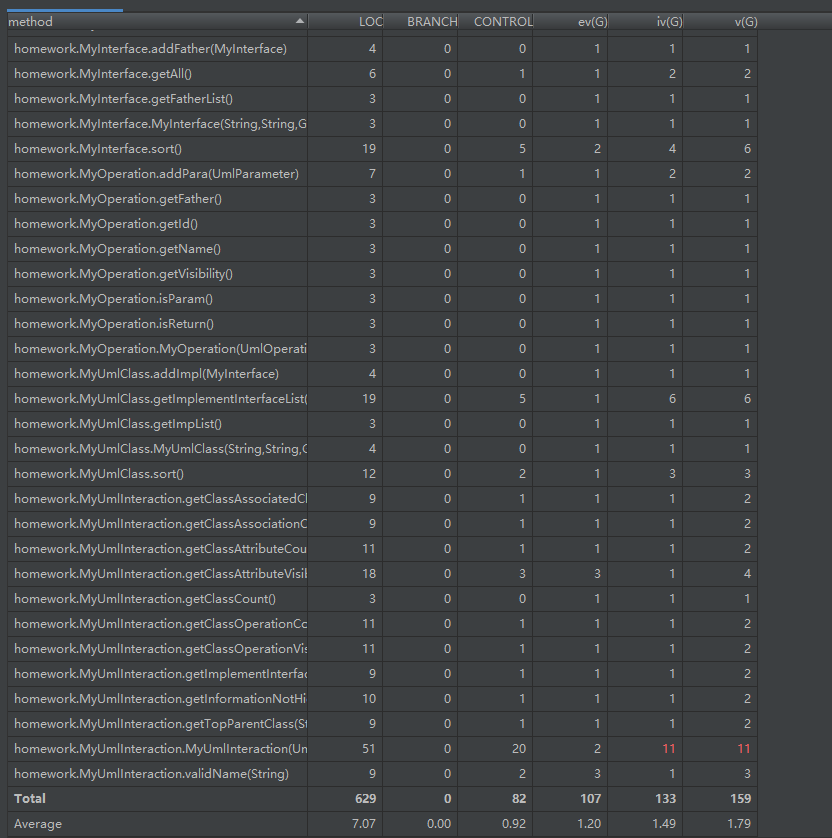
可以看出分布非常不均,大部分是比较简单,行数比较少的方法,有部分添加方法会比较复杂一点,主要是通过name进行查询的一些元素要对name进行处理;方法最复杂的还是MyUmlInteracition类中的创建方法,主要还是因为element的类型比较多。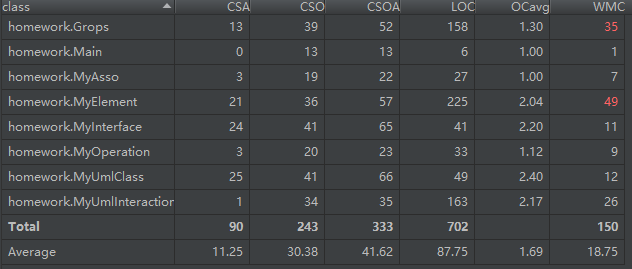
从类的统计可以看出,除了3个特别主要的类,其他数据类都比较小,属性、方法和代码行数都不是很多。总体上看跟前几个单元的作业来比,由于设计到的信息很多,所以方法和属性数多上不少。
(2)第二次作业
1.设计思路
这次的作业是在第一次作业的基础上进行拓展,基本继承第一次作业的代码,所以主要就是后续添加的一些功能。
结构上: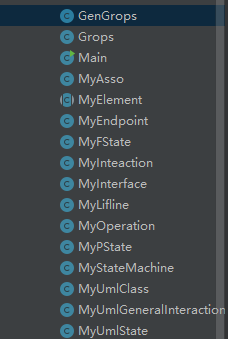
如图所示,继承了第一次作业的全部类,由于官方jar包里面一些类的改变,对于新加的一些元素,直接在MyUmlInteracition类的基础上进行修改,没有使用MyUmlGeneralInteraction继承MyUmlInteracition的操作。但是使用了GenGrops继承Grops类来处理新的元素和元素之间的关系。
GenGrops跟第一次作业一样,分类整理,通过id查找和关联。由于statemachine和对应state、transition之间隔了一层region类,还要记录一个region的id到对应的statemachine的映射。还有就是第一次作业总结的不足中的,MyState这些类的创建在GenGrops中,而且GenGrops也不抛出异常 ,是通过返回值为boolean的函数进行name存在和重名的查询,在MyUmlGeneralInteraction中统一抛出异常,不过由于直接继承了上次作业的代码,没有改上次作业的这方面的带码。
数据类,MyInteaction、MyStateMachine类管理和查询相关联state、endpoint、lifeline、message等元素。
新建了一个MyUmlState类,对应UmlState,主要是为了管理可达关系,存放对应的transition和transition对应的MyUmlState。虽然UmlPseudostate和UmlFinalState与state不同,也不会被查询到,但是由于这些也会与state通过transition连接到一起,为了查询后继方便,以及通过transition进行关联方便,我新建了一个继承MyUmlState的MyPstate对应UmlPseudostate;同样继承MyState的MyFState对应UmlFinalState。
同样新建了一个对应UmlLifeline的MyLifline类,主要用来统计incoming的message,EndPoint也是同理,新建了一个继承MyLifline的MyEndpoint类,方面message的管理。
当然官方包里还有UmlEvent这些类,但是由于作业没有用到,所以就没有管。
具体实现的方法上:
GenGrops和MyUmlGeneralInteraction跟第一次作业一样,MyUmlGeneralInteraction对读入的element进行分类,调用GenGrops中对应函数添加元素。遍历完elements之后,调用GenGrops中对应函数进行将元素关联起来。
这次作业的主要难点,就在3个规则和后继状态查询方面。
UmlRule002:检查重名元素。同样实现在GenGrops中,GenGrops会返回一个hashset,如果hashset的size大于0, 说明不符合规则,抛出exception。而检查函数具体的实现主要就是在MyElement中,添加attribute、operation、association的时候,将对应的name与存放所以已经添加了的attribute、operation、associationEnd的名字进行比较,如果有重名,添加到另一个记录重名的hashset类型的doublename中,由于只考虑自身的这些元素是否重名,不考虑继承来的,所以查询的时候不需要先进行整理。GenGrops查询UmlRule002的时候,会遍历MyElement(class和interface),将他们的doublename中的name和各自的name组成AttributeClassInformation,放到一个hashset中返回给MyUmlGeneralInteraction。
UmlRule008:检查循环继承。MyUmlGeneralInteraction中的操作与检查UmlRule002一样。GenGrops就遍历MyElenment集,调用对应函数检查是否是循环中的一环,将存在循环继承的类或接口放入hashset返回给MyUmlGeneralInteraction。由于class和interface的继承的规则不一样(class为单继承,interface支持多继承),我在MyElements类中定义了一个抽象函数HashSet<String> findloop(ArrayList<String> list),在MyUmlClass类和MyInterface类中一不同的方式实现。具体的流程就是同样有一个Boolean类型的标记位记录是否检查过,一个Boolean类型的标记位记录是否是循环继承的环上的一部分。进行检查的时候,先检查是否有父类,如果没有则说明是顶级父类,不可能存在循环继承,返回一个空的hashset;如果有,先检测自己的id是否在list中,如果不在,则将自己的id放到list中,调用父类的findloop函数,将list传递给父类;如果在,则说明梳理继承关系的时候两次到访过同一个类,存在循环继承,先在list中查找到自己id出现的位置index,这个id之后的list中的id就是在循环继承的环上的id,新建一个hashset,将index及之后的id都添加到hashset中,返回hashset。收到父类的返回的set之后,检查自己的id是否在这个hashset中,记录自己是否是循环继承中的一环。对于interface就复杂一点,需要对每个父类进行class的检测操作,而且每次调用父类的findloop函数,传递list进去的时候,要新建一个newlist,防止;两条继承链上的焦点干扰循环继承的判断,将重复继承判断为循环继承。
UmlRule009:检测重复继承。MyUmlGeneralInteraction中的操作与检查UmlRule002一样。GenGrops的操作跟UmlRule008一样,遍历MyElenment集,调用对应函数检查是否存在重复继承,将存在循环继承的类或接口放入hashset返回给MyUmlGeneralInteraction。同样在MyElement中定义了一个抽象函数,在MyUmlclass和MyInterface中各自实现,同样,一个Boolean类型的属性记录是否查询过,一个Boolean类型的属性记录是否违反规则。具体的实现方如下:(1)在class添加实现的操作中,加一步,检测添加的interface的id是否已经在当前的class保存的实现的interface的id池中,如果在,查询标记位和违反标记位都设为真。(2)在interface添加继承关系的操作中,同样加一步,查询是否在父类的id池中,如果在,查询标记位和违反标记位都设为真。(3)由于重复继承的会通过继承关系和实现关系进行传递,所以单独查询的时候,如果查询标记位不为真,需要先对class和interface进行整理,如果实现的接口或者父类有重复继承,这个类也是重复继承。
查询后继状态:state如果没有查询过,新建一个hashset,遍历直接后继state的list,将hashset传递下去;而后继state(包括Pseudostate和FinalState)先检测自己的id是否在hashset中,如果在,说明来过,返回,如果不在,将自己id添加到hashset中,然后检测是否查询过,如果查询过,将保存所有后继state(保存了所有直接和间接可达的state)的id的hashset添加到传进来的hashset中,返回;如果没有查询过,则同一开始,遍历后继的list,将这个hashset传递给后继状态。当函数返回的时候,将返回来的hashset添加到自己的保存所有后继state的id的hashset中。查询的时候返回对应的size就行。
2.代码结构
具体的类之间的关系如下图所示
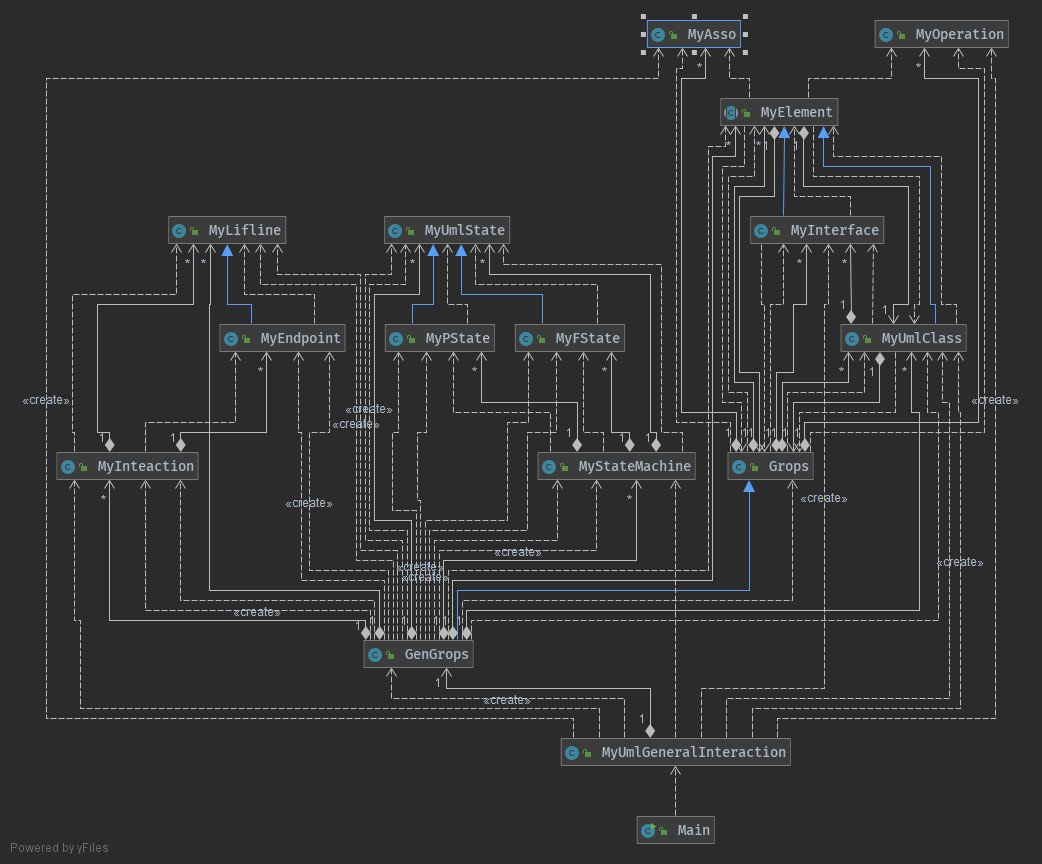
跟上文说的一样,改掉了第一次作业的一点点问题,但几乎没有动第一次作业的代码,没有改第一次作业中没有完全脱耦的问题。
3.结构分析
方法统计如下图所示,同样只截取了一部分
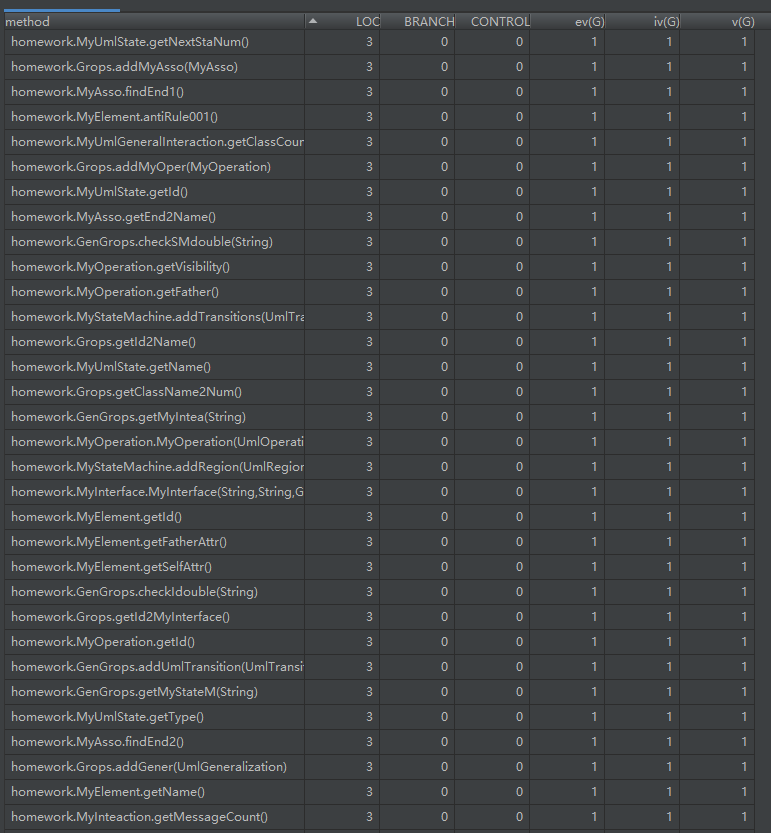

同样,代码行数很多,方法很多,但是绝大部分方法的行数的复杂度都很低,比较简单,平均行数很少,不到8行;较为复杂的方法行数也不超过35行,只有MyUmlGeneralInteraction的创建函数由于element的种类比较多,所以复杂度和行数都非常高。

跟第一次作业差不多,除了继承下来的类,新的GenGrops比继承的Grops的代码多了很多,主要是几个rule查询函数还有检测name不存在和重名的函数导致的,新的数据类中就MyStateMachine类由于相关的元素比较多,行数、属性和方法数,以及复杂度都比较高,但还是相对简单,还是赶不上第一次作业的MyElement、MyUmlClass和MyInterface类。
总体来看,这两次作业都是代码量非常大的工程。
二、四个单元的架构设计及OO方法理解的演进
第一单元,多项式识别处理
第一次作业:非常简单,了解java基本语法、函数调用、正则表达式这类java非常基础的方面,初步掌握如何使用java。而架构方面,也是非常简单的将几个步骤分开处理,在main函数中逐步调用其他类的方法处理数据,比如对多项式进行有效识别、多项式求导、合并同类项这几步分开而已。对OO方法、面向对象的概念还是没有什么理解,当成一种类似C的面向过程的语言进行处理。
第二次作业:变得复杂了,对对象有了初步的理解,将数据和数据的修改调用方法封装在一起,新建了Xiang这个类,对输入的数据进行检查、拆分、封装成对象,但对各个对象求导的过程还是通过外部方法实现,对象只是一个数据集合,还有很多处理的函数还是像C一样,一些类只是方法的库而已,用来调用其中保存的方法进行处理,对java里面的继承、多态、接口之类的概念没有多少了解。
第三次作业: 复杂度进一步提高,对对象有了更深的了解。除了将输入的字符串进行处理那步用到的方法还是封装到一个类进行调用,但是对继承和多态这些概念有了一定的理解,通过继承关系将项指数项、组合项、三角函数这些对象梳理起来,不同的项通过顶层的一个统一的求导函数、toString函数的接口,但各自有不同的实现,求导和输出的过程通过调用各个对象各自的方法实现。但是大部分代码还是面向过程的思想,而且对抽象类、接口之类的概念了解甚少。
第二单元,多线程电梯
第一次作业,FCFS的傻瓜式电梯。比较简单,就是电梯类、main类两个线程,requestlist和control类管理数据和调度方法。比较简单,主要就是了解多线程的基本操作。mian和电梯类两个线程简单的同步操作,通过对管理数据的control类加锁来保证数据线程安全。
第二次作业,可捎带电梯,look算法。相对复杂了一点,但由于设计的相对简单,没有涉及到很多的同步问题,进程同步方式跟第一次作业一样。效率相对较低。虽然对进程间的同步通过理论课有了更深理解,但是没有在作业中应用。对面向对象有了更多的理解,但是还是没法很好的区分某个对象要实现他的功能应该具体实现哪些方法,哪些方法有应该放在那里实现,就比如电梯中实现了一些本应该在control类里面实现的函数。
第三次作业,3个可捎带电梯。架构跟第二次作业基本一致,只是多了两部电梯,电梯之间虽然有继承关系,同样没有抽象类和接口,不同子类之间只是一些属性不太一样。因为要考虑换乘的问题,所以request增加了一个缓存集暂存下半部分路程,等第一部分的指令完成之后再加入指令列表。而且在control里保存三个电梯的状态,进行三个电梯的数据综合统筹。同样,同步的方式跟第二次一样,对管理数据的control类进行加锁,保证安全但是效率还是低。虽然通过理论课对线程同步有了更好的理解,但是由于时间安排等原因,没有改变设计,没有将理论的所学在作业中有很好的实现。而面向对象方面,能更好的区分电梯对象和control各自应该实现的功能和与之匹配的方法。
第三单元,JML
第一次作业,路径和路径容器。相对比较简单,也不涉及多线问题。main类作为和官方包的接口,MyPath类存储path的信息,MyPathContainer容器,对path进行管理。整个单元的主题是JML,根据官方包里面的jml就能很好的确定各类需要的功能。但是具体的实现方式还是需要自己管理,因此我还是没有管理好复杂度出现了问题。我也官方包jml中学习了类需要保存的数据和实现的方法的这方面设计。
第二次作业,无权无向图。变得更加复杂了。path直接使用上次作业的,MyGraph也是复制了大部分上次作业的代码,对于path的查询、增删之类的操作还是在MyGraph中实现,但是图相关的边、点之间的可达和最短路径的数据管理和查找在另一个类UdGraph里面实现。同样,根据jml确定功能,契约式编程。同时,jml给予的方法规定,更好的帮助我进行测试的设计。
第三次作业,有权无向图。其实相比起来没有多少复杂的提升。基本架构跟上次作业差不多,没有复制代码,使用继承的方式,MyRailwaySystem继承了第二次作业的MyGraph类。我对于继承这个方式有了更好的理解,有了更复杂也更实际的应用。第二次作业的功能还是使用第二次作业对应的类实现,新增的最小换乘、最小不满意度、最小票价这些功能通过新的UdrGraph实现。由于新的功能的算法需要,在path类里面添加了新的方法。这次,jml在对功能的确定上的作用已经不是很大,更多的是需要我们自己发现合适的算法。jml 的作用更多的是在于对于方法测试方面的设计有更多的指导作用。
第四单元,UML
第一次作业,类图。具体的代码结构已经在上文解释了。经过三个单元的练习,对继承和接口有了更深的理解,使用了抽象类的结构,而且子类的运用方式也不是只是简单属性的区别,有一些特有的方法。
第二次作业,顺序图和状态图。具体的结构也是在上面。基本跟第一次作业一样,只是增加了一些新的数据类型,修改了一些第一次作业没有做的太好的脱耦。
三、测试的理解和实践
第一单元。
测试的理解更多的就是一个数据集,包括合法和不合法的输入,想测试的时候实际上就是在考虑可能有什么类型的输入。还是从比较表面的考虑,没有从测试方法功能之类的情况考虑。
具体的实践也不是很多,一个比较简单的测试数据集,写代码之前想了一部分,在写代码的过程中想了一部分。后面测试的时候还是用的同学的产生随机数据的对拍机。
第二单元
由于是多线程设计,测试起来比较麻烦。设计的数据没有很多,由于我的设计牺牲了性能但是线程的安全性还是比较好的,所以所做的测试不是很多,更多还是比较简单的测试是否能够正常运行。但是因此没有测试边界数据导致爆了一次中测。
设计的比较多的数据是用来调节算法,寻找更好的调配方式,提高性能分。
第三单元
第三单元是uml,这种契约式的编程可以很方便的设计方法的功能,同时也学到了junit来进行白盒的方法和功能测试,可以很模块化的一个模块一个模块、一个方法一个方法进行测试。但是junit只是提供一个测试工具,测试数据还是需要自己想,所以还是不是很方便,但是不需要全部完成之后再进行测试,可以写一个模块测试一个模块。而且使用的OpenJML也不支持/exist和/forall这类较为复杂的JML语法,所以根据jml自动生成测试还是没有用。
第四单元
第四单元是UML,测试方面需要通过StarUML先建立UML数据,通过官方的jar翻译成输出再进行测试。由于输入涉及到了很多的官方提供的类和数据,用junit测试起来比较麻烦,还是回归前两单元的测试方式,完成了之后再统一通过输入输出测试,发现了一些设计上的遗漏以及由于两次作业的限制不同导致的直接复用代码导致的问题。
四、课程收获总结
首先是学会了JAVA这种面相对象的语言,学到了很多面相对象的思想。我在上大学之前是没有编程基础的,只有大一学到的面相过程的C语言的。这门课程让我学到了java和更广泛使用的面相对象的这种编程思想,极大地拓展了我的视野,提高了我的编程能力。从之前三五百行代码就有点控制不住,到现在能够完成上千行的代码的工程。而且还学会了多线程的设计,线程之间的同步互斥的方法和思想。
此外测试方面还引入了JUnit这类模块测试软件和模块测试的思想。现在我不仅是最基础的设计数据,完成项目后从输入进行测试,我还学会了通过JUnit这类测试工具在编程过程中,完成部分功能模块之后就能进行测试,修复bug和更改算法的代价变得比较低。
还有与JUnit对应的JML这类接口规范语言和工程化、契约式的编程方法,对现在行业内的工业化的方法有所了解。
第四单元的UML的学习,可以让我通过UML这种可视化的工具,在我进行项目设计和交流的时候有了更好的工具。而且通过UML的一些规则的学习,我对类、接口、实现和继承之间关系和在完成作业的过程中通过具体应用有了更深的理解。
总而言之,我学习到了JAVA这一广泛使用的面向对象的语言,还学习到了面向对象和多线的编程思想和编程方法,同时我还学到了JML这种模块语言还学到了模块化的测试方式,还有UML这种设计方式。不仅如此,我还了解了模块化的方式,窥见行业的一角。学习了面向对象的编程语言、思想、工具,还了解了行业方法,通过面香对象这门课程我收获良多,非常感谢各位老师和助教们一个学期依赖的辛勤努力。
五、三个具体改进的建议
1、课程设计方面,这个学期的理论课和上机挨得非常近,上午理论课上完还没有消化,或者还有问题没有搞清楚,下午就要立刻上机。希望以后能够提前提供一些课程方面的东西,如果课程挨得非常紧调不开也能够提前进行准备。
2、JML部分,由于是第一次使用JML这种接口规范语言,在工具和设计方面都有一些准备不足的地方,像OpenJML不支持exist和forall这类比较高级的语法,导致自动化测试根本没用。希望以后能够换一种配套工具更齐全的接口规范语言。
3、就一些工具方面,无论是JUnit还是StarUML,都只是简单的提到,但是又会很快的用到,也没有提供一些使用指南方面的东西。而且与第一条配套,上午讲完,下午上机就要用到,讨论区里只有安装教程没有使用教程,使用还得自己上网查、自己摸索,而上机时间也不是很充裕。以后这种上机要用到的工具提供更多更详细的使用教程。
建议主要就这三个方面,希望能对课程改进提供一些帮助。