1. Storm集群架构
strom jar all-your-code.jar backtype.storm.MyWordCounterTopology arg1 arg2
这个命令会运行主类: backtype.strom.MyTopology, 参数是arg1, arg2。这个类的main函数定义这个topology并且把它提交给Nimbus。
storm jar负责连接到nimbus并且上传jar文件。因为topology的定义其实就是一个Thrift结构并且nimbus就是一个Thrift服务。
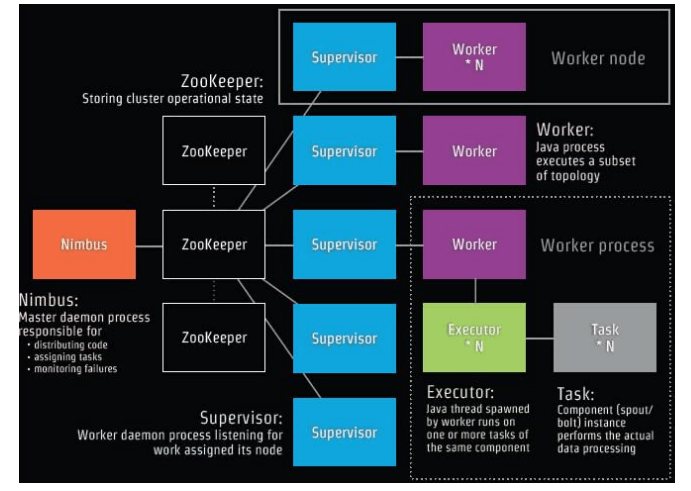
Storm集群采用主从架构方式,主节点是Nimbus,从节点是Supervisor,有关调度相关的信息存储到ZooKeeper集群中.
Storm适用的场景:
1、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
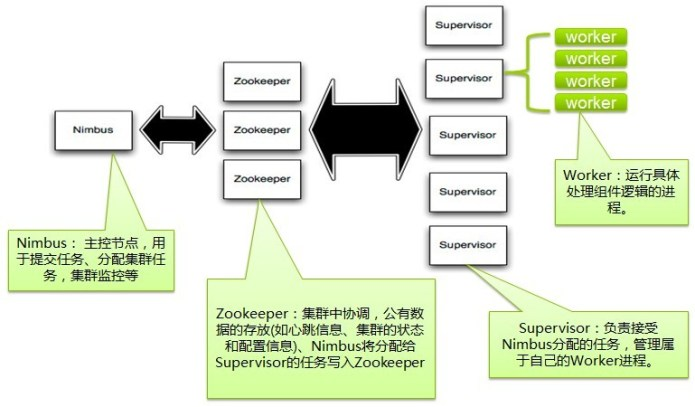
Nimbus: Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor: Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。 通过Storm的配置文件中的supervisor.slots.ports配置项,可以指定在一 个Supervisor上最大允许多少个Slot,每个Slot通过端口号来唯一标识,一个端口号对应一个Worker进程(如果该Worker进程被启动)。
Worker: 运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task: worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
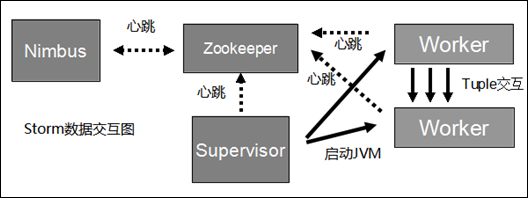
ZooKeeper:用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其它可用的Supervisor上运行.
2. Storm编程模型
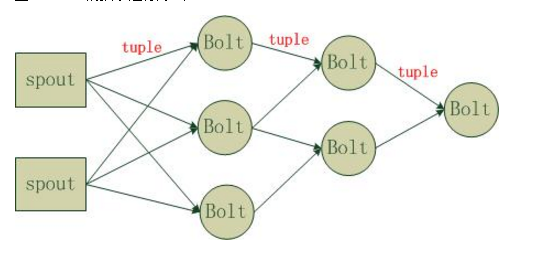
Strom在运行中可分为spout与bolt两个组件,其中,数据源从spout开始,数据以tuple的方式发送到bolt,多个bolt可以串连起来,一个bolt也可以接入多个spot/bolt.
Topology:Storm中运行的一个实时应用程序的名称。将 Spout、 Bolt整合起来的拓扑图。定义了 Spout和 Bolt的结合关系、并发数量、配置等等。
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
Stream:Tuple的集合。表示数据的流向。
2.1 Stream是storm里面的关键抽象。一个stream是一个没有边界的tuple序列。storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream.
2.2 storm提供的最基本的处理stream的原语是spout和bolt。你可以实现Spout和Bolt对应的接口以处理你的应用的逻辑。
2.3 通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,之后发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,
Storm框架会不停的调用该函数。
2.4 bolt可以接收任意多个输入stream, 作一些处理, 有些bolt可能还会发射一些新的stream。
2.5 一些复杂的流转换, 比如从一些tweet里面计算出热门话题, 需要多个步骤, 从而也就需要多个bolt。
2.6 Bolt可以做任何事情: 运行函数, 过滤tuple, 做一些聚合, 做一些合并以及访问数据库等等。
2.7 Bolt处理输入的Stream,并产生新的输出Stream。Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作。
2.8 Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑.
2.9 spout和bolt所组成一个网络会被打包成topology, topology是storm里面最高一级的抽象(类似 Job),
2.10 你可以把topology提交给storm的集群来运行。topology的结构在Topology那一段已经说过了.


3. Topology运行
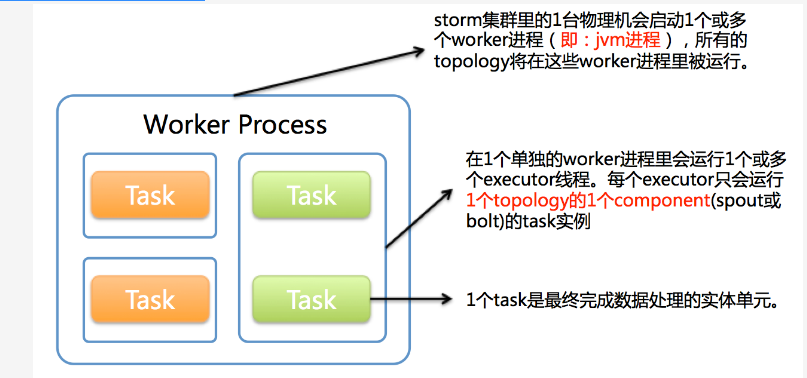
(1). Worker(jvm进程)
(2). Executor(Worker 里的线程)
(3). Task(具体的 spout 或者 bolt)
- 1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。
- 1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。
- 1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
- executor是1个被worker进程启动的单独线程。
- 每个executor只会运行1个topology的1个component(spout或bolt)的task。
- 注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
- task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。
- topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(
- 例如:1个executor线程可以执行该component的1个或多个task实例)。
- 这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。
- 默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task.
4. 概念
1.拓扑(Topology):打包好的实时应用计算任务,同Hadoop的MapReduce任务相似。
TopologyBuilder builder =newTopologyBuilder(); builder.setSpout(1,newRandomSentenceSpout(),5); builder.setBolt(2,newSplitSentence(),8).shuffleGrouping(1); builder.setBolt(3,newWordCount(),12).fieldsGrouping(2,newFields("word"));
2.元组(Tuple):是Storm提供的一个轻量级的数据格式,可以用来包装你需要实际处理的数据。Tuple本来应该是一个Key-Value的Map,
由于各个组件间传递的tuple的字段名称 已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List。一个没有边界的、源源不断的、连续的Tuple序列 就组成了Stream


3.流(Streams):数据流(Stream)是Storm中对数据进行的抽象,它是时间上无界的tuple元组序列(无限的元组序列)。
4.Spout(喷嘴):Storm中流的来源。Spout从外部数据源,如消息队列中读取元组数据并吐到拓扑里。
public class RandomInputSpout extends BaseRichSpout { SpoutOutputCollector spoutOutputCollector; Random random;
@Override @SuppressWarnings("rawtypes")public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { spoutOutputCollector = collector; random = new Random(); } @Override public void nextTuple() { Utils.sleep(2000); String[] sentences = new String[]{ "I want sth", "Let me go", "Oh my god", "View sth", "ET want god do sth"}; String sentence = sentences[random.nextInt(sentences.length)]; spoutOutputCollector.emit(new Values(sentence.trim().toLowerCase())); } @Override public void ack(Object id) { } @Override public void fail(Object id) { } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("value")); } }
5.Bolts:在拓扑中所有的计算逻辑都是在Bolt中实现的。
public static ExclamationBolt implements IRichBolt { OutputCollector _collector; publicvoidprepare(Map conf, TopologyContext context, OutputCollector collector) { _collector = collector; } publicvoidexecute(Tuple tuple) { _collector.emit(tuple,newValues(tuple.getString(0) +"!!!")); _collector.ack(tuple); } publicvoidcleanup() { } publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(newFields("word")); } }
6.任务(Tasks):每个Spout和Bolt会以多个任务(Task)的形式在集群上运行。
7.组件(Component):是对Bolt和Spout的统称。
8.流分组(Stream groupings):流分组定义了一个流在一个消费它的Bolt内的多个任务(task)之间如何分组。
8.3 AllGrouping:广播发送,将每一个Tuple发送到所有的Task。
8.4 GlobalGrouping:所有的Tuple会被发送到某个Bolt中的id最小的那个Task。
8.5 NoneGrouping:不关心Tuple发送给哪个Task来处理,等价于ShuffleGrouping。
8.6 DirectGrouping:直接将Tuple发送到指定的Task来处理。
9.可靠性(Reliability):Storm保证了拓扑中Spout产生的每个元组都会被处理。
10.Workers(工作进程):拓扑以一个或多个Worker进程的方式运行。每个Worker进程是一个物理的Java虚拟机,执行拓扑的一部分任务。
11.Executor(线程):是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component。
12.Nimbus:Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
13.Supervisor:Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。
from: https://blog.csdn.net/weiyongle1996/article/details/77142245?utm_source=gold_browser_extension