之前的博客,有对业内比较出名的几家互联网大厂的全链路压测方案进行过整理和总结,传送门:聊聊全链路压测。
时隔一年多,由于性能测试及相关知识的学习实践,对其有了新的认识,这里,再次聊聊我对全链路测试的理解。。。
目前的现状
以我现在所在的银行业务系统来说,目前的现状大概有这些:业务逻辑太复杂、系统庞大、子系统较多、系统间解耦程度较低、调用链路较长、核心系统环环相扣。
在这种情况下,常规的性能测试工作内容,大概如下:
①、只能进行独立系统的压测工作,导致压测任务量较大;
②、强依赖系统较多,第三方调用面临种种限制,只能通过mock方式解决;
③、没有较为独立的性能测试环境,UAT和PAT测试数据差异较大,无法给予上线一个较为准确的容量评估;
④、项目排期没有预留足够的性能测试时间,导致需要经常加班甚至通宵;
⑤、工程师文件建立较为薄弱,对系统性能的认知和重视度不足,往往让人觉得沮丧;
上面的几种情况,据我了解,在大多数公司都存在类似的情况,这些因素导致面临着越来越高的数据冲击和越来越复杂的业务场景,急需一种手段来保障和提高系统的高性能高可用。
面临的挑战
除了上面所说的技术层面的问题,要开展全链路压测,还面临如下的几点挑战:
①、由于全链路压测涉及的系统及场景较多,因此需要跨团队沟通、跨系统协调改造,公司体量越大,这一点难度就越大;
②、全链路压测涉及的系统较多,且不同的系统架构也有所不同,因此需要考虑:机房管理、基础网络、DB管理、持久存储、中间件、应用部署、流量接入、监控与运维保障等多方面;
③、全链路压测的目的是找到系统调用链路薄弱环节并优化,这就要求对整个调用链路涉及的系统进行进行准确的容量规划,因此环境和配置,是必须重视的一点;
当然,可能还存在其他问题,比如性能测试团队成员的技术水平是否满足要求、管理层的支持力度等方面,毕竟,这是一项很庞大复杂的软件工程项目!!!
不过全链路压测的优点也很明显,比如:优化联络薄弱环节可以提高系统的可用性,容量规划可以节省成本,提高效率。
开展前的准备工作
在开展全链路压测之前,我们需要做哪些准备工作?
①、业务梳理:覆盖全部的业务场景,是难度很大且不理智的选择,一般来说只需要筛选出高频使用的功能、核心功能以及基础功能即可;
②、场景梳理:场景梳理也是很重要的一项工作,因为只有确定了被测场景,我们才能设计合理的测试方案和策略,场景覆盖正常操作、异常操作即可;
③、流量模型:“我们往往对高并发一无所知!”因此需要通过监控分析等手段,得到日常流量场景、峰值流量场景下各系统的流量以及配比,进行一定的放大,来作为全链路压测的流量参考模型;
④、数据处理:全链路压测通常在生产环境进行,所以防止数据污染是必须考虑的问题,一般来说都是通过对入口流量进行标记区分、数据隔离、影子库等方式来避免,当然,还需要做好灾备工作;
⑤、实时监控:无论是压测开始前还是测试进行中,都需要及时且可视化的获取到系统的状态变化,方便及时排查定位问题,也避免压测对正常的服务造成干扰;
监控的重点,主要是对应服务的TPS、不同百分比的RT、成功率、资源耗用、服务状态、告警等信息;
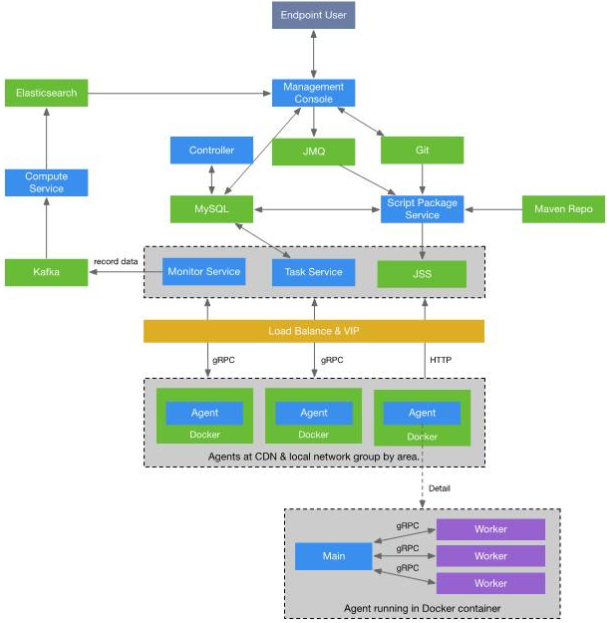
全链路压测平台架构设计
要开展全链路压测,那么一个合理高效可用的压测管理平台,是很有必要的,参考了很多全链路压测的设计思路,我个人的想法中全链路压测平台的架构设计,主要由以下几部分组成:
①、Controller:主要任务为压测任务分配、Agent管理;
②、Agent:负责心跳检测、压测任务拉取、执行压测(多进程多线程方式);
③、Task Service:负责压测任务下发、Agent的横向扩展,以确保压测发起端不成为瓶颈(可以利用RPC框架来实现);
④、Monitor Service:接收Agent回传的监控和测试数据日志,并转发给消息队列,让Compute Service进行汇总计算展现;
⑤、Compute Service:对压测结果进行计算,并结合Grafana等可视化工具进行界面展示;
⑥、Log Service:日志服务,即无论压测机还是服务应用在测试过程中产生的日志,都统一收集,方便进行问题排查定位;
⑦、Elasticsearch/Influxdb:对压测产生的数据存储;
⑧、Git:压测脚本的版本管理;
⑨、Gitlab:作为数据仓库进行版本管理,Agent主动拉取脚本执行;
⑩、Redis:主要用于配置信息管理;
PS:当然,我个人的构思存在不完善或者有待仔细斟酌的地方,这里只是给一个参考。具体的架构设计图,可参考京东的全链路军演系统ForceBot的架构设计,如下图:
完成了上面的工作,接下来就可以开展全链路压测的工作了。当然,有一点需要说明:全链路压测并不适用于中小型公司,一方面因为成本,另一方面,不适合而已。
最后,在开展性能测试之前,请认真思考,当我们讨论性能测试时,我们在说什么?