本文旨在总结一次从头开始训练CNN进行图像分类的完整过程(猫狗大战为例,使用Keras框架),免得经常遗忘。流程包括:
- 从Kaggle下载猫狗数据集;
- 利用python的os、shutil库,制作训练集和测试集;
- 快速开发一个小模型作为基准;(只要效果比随机猜略好即可,通常需要有一点过拟合)
- 根据基准表现进行改进,比如针对过拟合的图像增强、正则化等。
1 从Kaggle下载猫狗数据集
2 制作数据集
从Kaggle下载的猫狗数据集大概八百多兆,其中训练集包含25000张猫狗图,两类数量各占一半。为了快速上手项目,可以从原始训练集中抽取一部分数据,来制作本次项目的数据集D,其中包含三个子集:两个类别各1000个样本的训练集(构造一个平衡的二分类问题),两个类别各500个样本的验证集,两个类别各500个样本的测试集。代码如下:
"""
代码功能:在目标文件夹下建立三个子文件夹(train、validation、test),在每个子文件夹下再分别建立两个子文件夹(cats、dogs),以存放从原始训练集中抽取的图像
"""
import os, shutil
original_dataset_dir = r'D:KaggleDatasetscompetitionsdogs-vs-cats rain' #在我磁盘上解压的文件夹
base_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-small' #在我磁盘上的目标文件夹
##############以下是创建文件夹并复制图像#######################
#创建训练集文件夹
train_cats_dir = os.path.join(base_dir, 'traincats')
train_dogs_dir = os.path.join(base_dir, 'traindogs')
os.makedirs(train_cats_dir)
os.makedirs(train_dogs_dir) #与os.mkdir的区别是会自动创建中间路径;若文件夹已存在,则都会报错
#创建验证集文件夹
validation_cats_dir = os.path.join(base_dir, 'validationcats')
validation_dogs_dir = os.path.join(base_dir, 'validationdogs')
os.makedirs(validation_cats_dir)
os.makedirs(validation_dogs_dir)
#创建测试集文件夹
test_cats_dir = os.path.join(base_dir, 'testcats')
test_dogs_dir = os.path.join(base_dir, 'testdogs')
os.makedirs(test_cats_dir)
os.makedirs(test_dogs_dir)
#将原始训练集中前1000张猫图复制到train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)] #前1000张猫图名称列表
for fname in fnames:
scr = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(scr, dst)
#将之后的500张猫图复制到validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
scr = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(scr, dst)
#将再之后的500张猫图复制到test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
scr = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(scr, dst)
#同理,对狗狗图做同样处理
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
scr = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(scr, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
scr = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(scr, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
scr = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(scr, dst)
3 快速开发基准模型
面对一个任务,通常需要快速验证想法,并不断迭代。因此开发基准模型通常需要快速,模型能跑起来,效果比随机猜测好一些就行,不用太在意细节。至于正则化、图像增强、参数选取等操作,后续会根据需要来进行。
####################模型搭建与编译#################################
from keras.models import Model
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
def build_model():
input = Input(shape=(150, 150, 3))
X = Conv2D(32, (3,3), activation='relu')(input)
X = MaxPooling2D((2,2))(X)
X = Conv2D(64, (3,3), activation='relu')(X)
X = MaxPooling2D((2,2))(X)
X = Conv2D(128, (3,3), activation='relu')(X)
X = MaxPooling2D((2,2))(X)
X = Conv2D(128, (3,3), activation='relu')(X)
X = MaxPooling2D((2,2))(X)
X = Flatten()(X)
X = Dense(512, activation='relu')(X)
X = Dense(1, activation='sigmoid')(X)
model = Model(inputs=input, outputs=X)
return model
model = build_model()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
#model.summary()
#########使用图像生成器读取文件中数据(内存一次无法加载全部图像)###########
#ImageDataGenerator就像一个把文件中图像转换成所需格式的转接头,通常先定制一个转接头train_datagen,它可以根据需要对图像进行各种变换,然后再把它怼到文件中(flow方法是怼到array中),约定好出来数据的格式(比如图像的大小、每次出来多少样本、样本标签的格式等等)。这里出来的train_generator是个(X,y)元组,X的shape为(20,150,150,3),y的shape为(20,)
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255) #之后可能会在这里进行图像增强
test_datagen = ImageDataGenerator(rescale=1./255) #注意验证集不可用图像增强
batch_size = 20
train_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-small rain'
validation_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-smallvalidation'
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(150,150),
batch_size=batch_size,class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150,150), batch_size=batch_size, class_mode='binary')
#######################开始训练####################################
epochs = 100
steps_per_epoch = 2000 / batch_size
validation_steps = 1000 / batch_size
H = model.fit_generator(train_generator,
epochs=epochs,
steps_per_epoch=steps_per_epoch,
validation_data=validation_generator,
validation_steps=validation_steps)
#保存模型
model.save('cats_and_dogs_small_1.h5')
print("The trained model has been saved.")
##模型评估
test_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-small est'
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150,150), batch_size=20, class_mode='binary')
score = model.evaluate_generator(test_generator, steps=50)
print("测试损失为:{:.4f}".format(score[0]))
print("测试准确率为:{:.4f}".format(score[1]))
######################结果可视化#############################
import matplotlib.pyplot as plt
loss = H.history['loss']
acc = H.history['acc']
val_loss = H.history['val_loss']
val_acc = H.history['val_acc']
epoch = range(1, len(loss)+1)
fig, ax = plt.subplots(1, 2, figsize=(10,4))
ax[0].plot(epoch, loss, label='Train loss')
ax[0].plot(epoch, val_loss, label='Validation loss')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss')
ax[0].legend()
ax[1].plot(epoch, acc, label='Train acc')
ax[1].plot(epoch, val_acc, label='Validation acc')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Accuracy')
ax[1].legend()
plt.show()
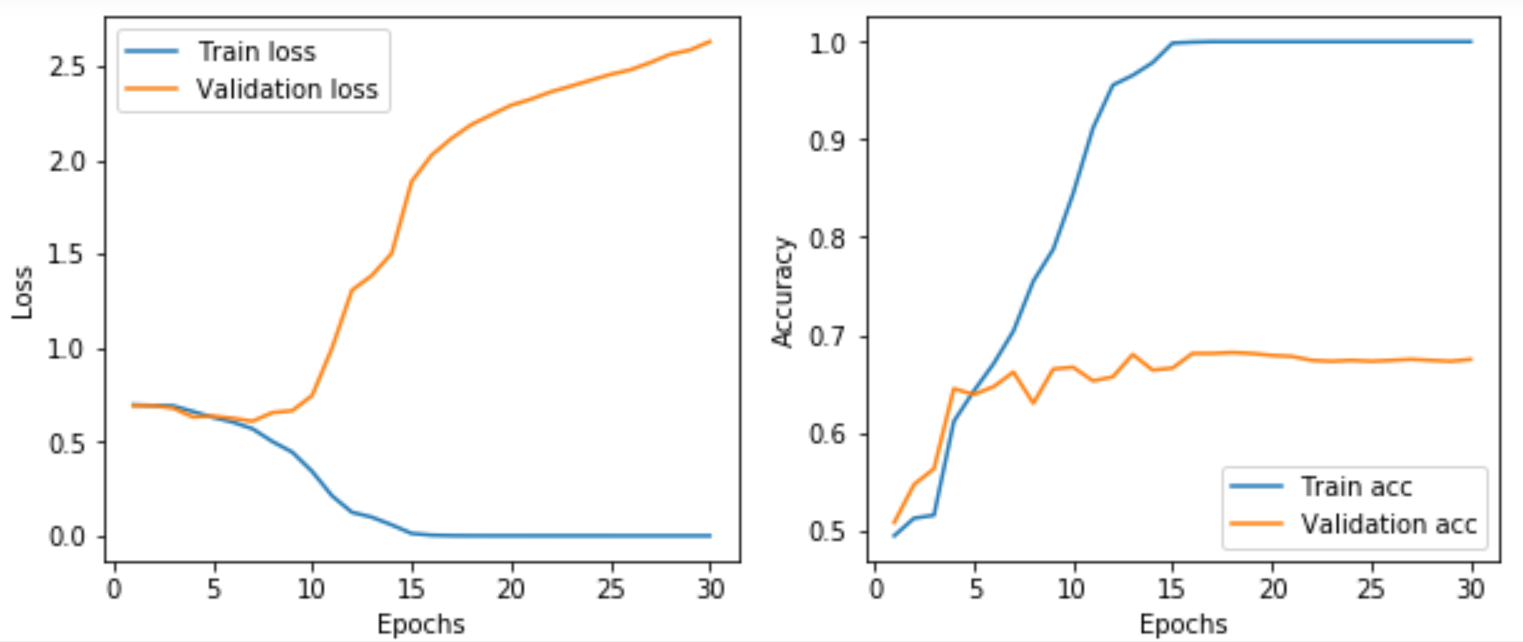
训练结果如下图所示,很明显模型上来就过拟合了,主要原因是数据不够,或者说相对于数据量,模型过复杂(训练损失在第15个epoch就降为0了)。
4 根据基准模型进行调整
为了解决过拟合问题,可以减小模型复杂度,也可以用一系列手段去对冲,比如增加数据(图像增强、人工合成或者多搜集真实数据)、L1/L2正则化、dropout正则化等。这里主要介绍CV中最常用的图像增强。
4.1 图像增强方法
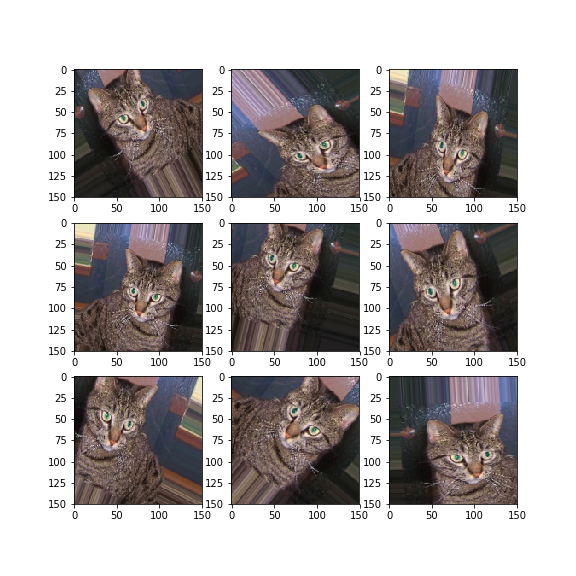
在Keras中,可以利用图像生成器很方便地定义一些常见的图像变换。将变换后的图像送入训练之前,可以按变换方法逐个看看变换的效果。代码如下:
#######################查看数据增强效果#########################
from keras.preprocessing import image
import numpy as np
#定义一个图像生成器
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
#生成所有猫图的路径列表
train_cats_dir = os.path.join(train_dir, 'cats')
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
#选一张图片,包装成(batches, 150, 150, 3)格式
img_path = fnames[1]
img = image.load_img(img_path, target_size=(150,150)) #读入一张图像
x_aug = image.img_to_array(img) #将图像格式转为array格式
x_aug = np.expand_dims(x_aug, axis=0) #(1, 150, 150, 3) array格式
#对选定的图片进行增强,并查看效果
fig = plt.figure(figsize=(8,8))
k = 1
for batch in datagen.flow(x_aug, batch_size=1): #注意生成器的使用方式
ax = fig.add_subplot(3, 3, k)
ax.imshow(image.array_to_img(batch[0])) #当x_aug中样本个数只有一个时,即便batch_size=4,也只能获得一个样本,所以batch[1]会出错
k += 1
if k > 9:
break
效果如下:
4.2 模型调整方法
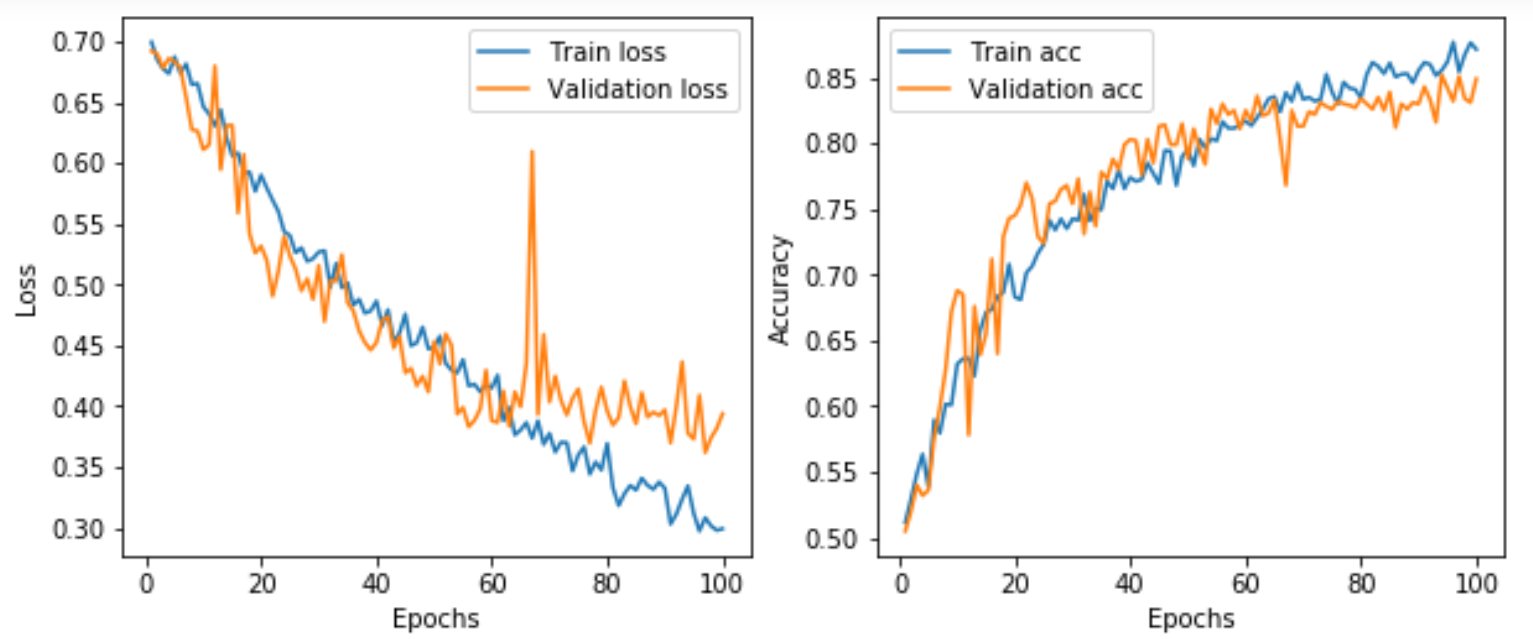
这里暂时先采用两种方法进行改进:一是将这几种选定的图像增强方法添加进训练集的生成器中(train_datagen);二是在模型结构中加入一层Dropout(在Flatten层后加上 Dropout(0.5))。调整并重新训练后发现30个epoch还不够,损失函数还在持续下降,于是改为100个epoch。重新训练后的结果如图所示。可以看出,准确率由基准的67%提高到82%,进一步调整模型还可以提升到86%左右。但是进一步就再难以继续提升了,因为数据太少,且模型比较粗糙,下一节我们会采取其他更有效的措施。
5 知识点小结
- 如何从Kaggle上下载公开数据集;
- 如何根据原始图像制作小型数据集;
- 如何使用图像生成器读取文件中图片,并送入训练;
- 如何进行数据增强,并查看增强的效果;
- 如何将训练结果可视化。
另外,关于CNN模型的架构,通常有一些经验:
- 从前往后,特征图需要适当的下采样。一方面减少参数,另一方面也可以增大后侧特征图像素的感受野。
- 下采样的方法可以采用带步长的卷积、平均池化或最大池化,但最大池化往往比前两种方法好,因为CNN的本质就在于用卷积核中的特征去匹配前一层的图像或特征图,前两种方法可能会错过或淡化特征是否存在的信息。
Reference
Python深度学习