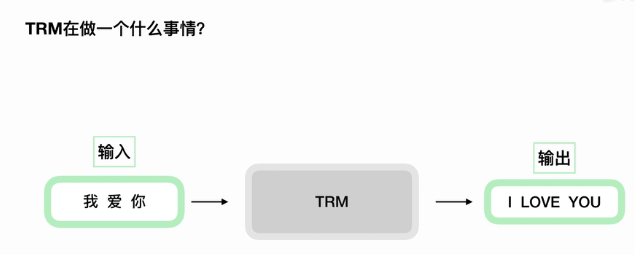
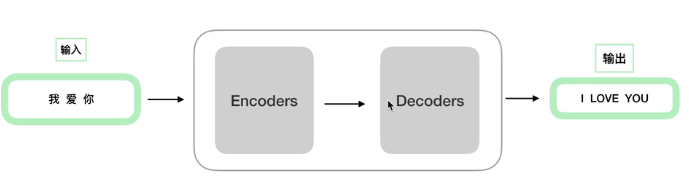
1:transformer结构

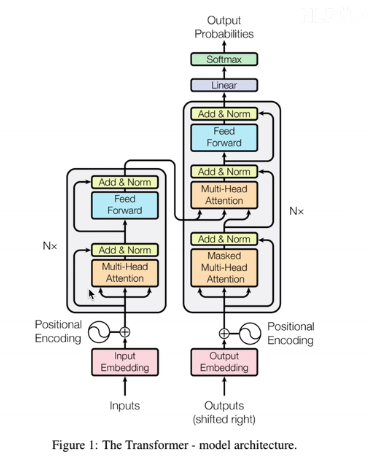
2:单个的encoder
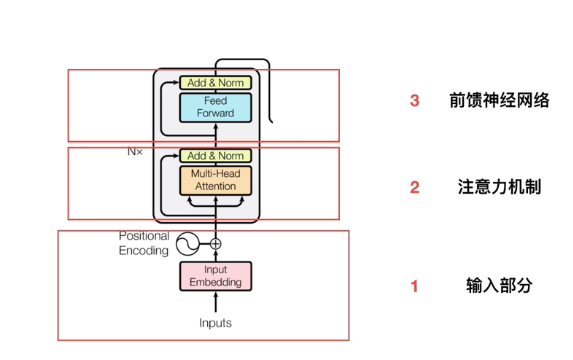
2.1输入部分

2.1.1embedding
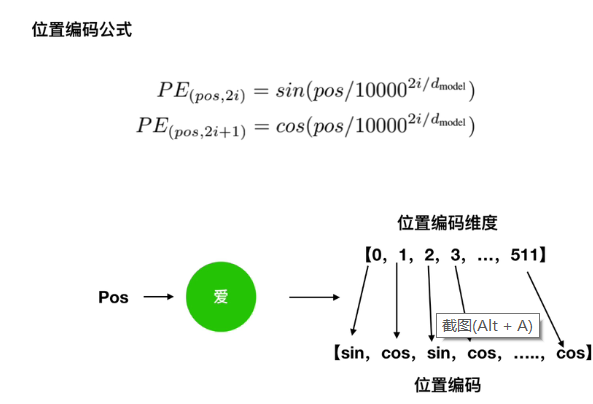
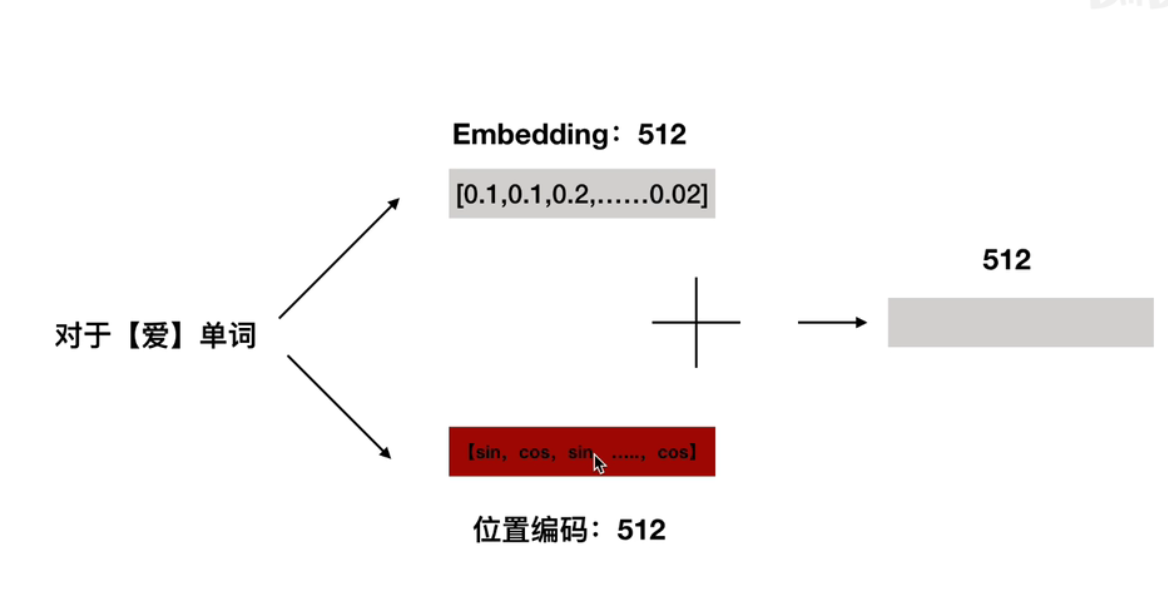
2.1.2位置编码
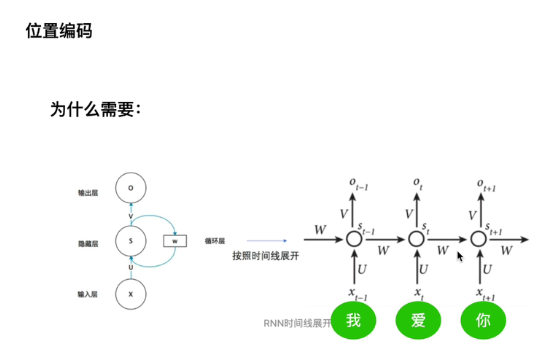
【注】RNN是按照时间线展开,单词的先后顺序没有被忽略。而transformer是并行处理的,故增快了速度,忽略了单词之间的先后顺序。

2.2注意力机制
2.2.1注意力机制
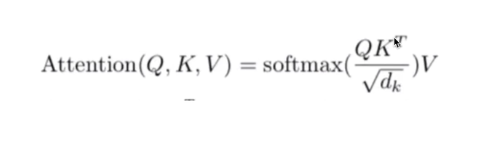
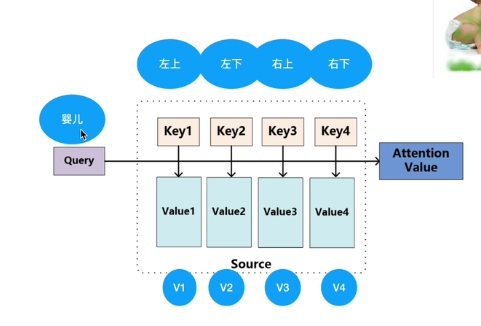
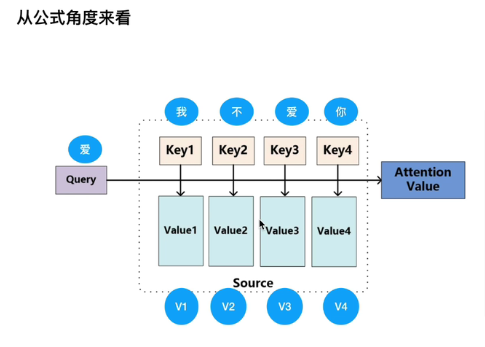
基本的注意力机制:
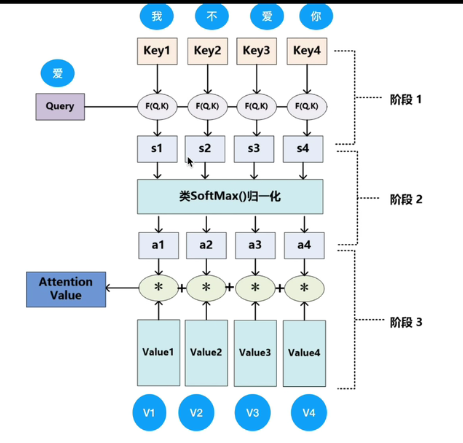
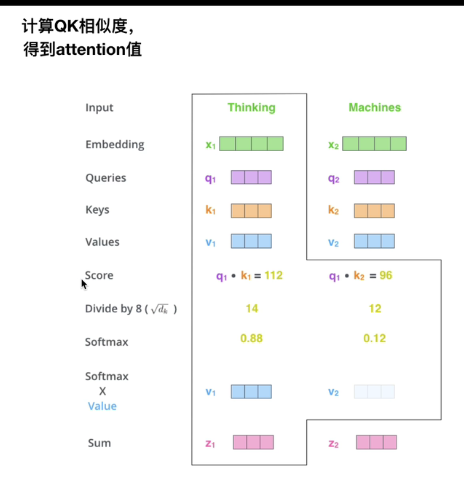
TRM中的中的注意力机制操作:

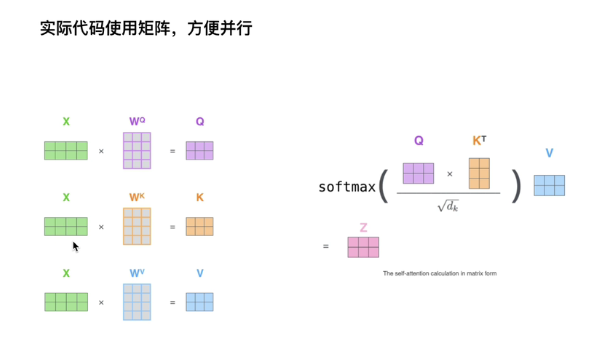
2.3残差和LayNorm
2.3.1残差:
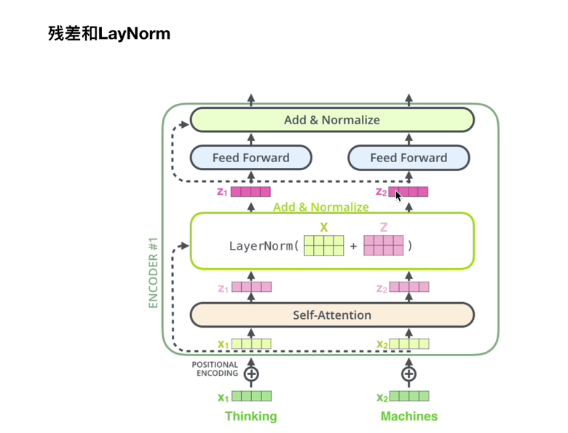
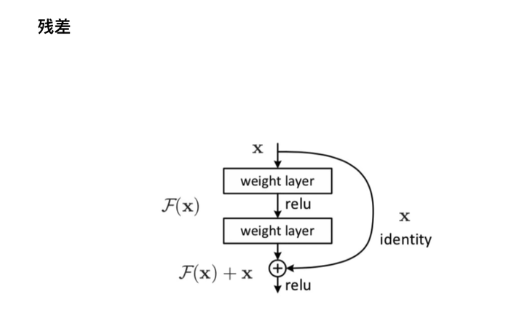
图1
【注】这里的⊕ 为对位相加。
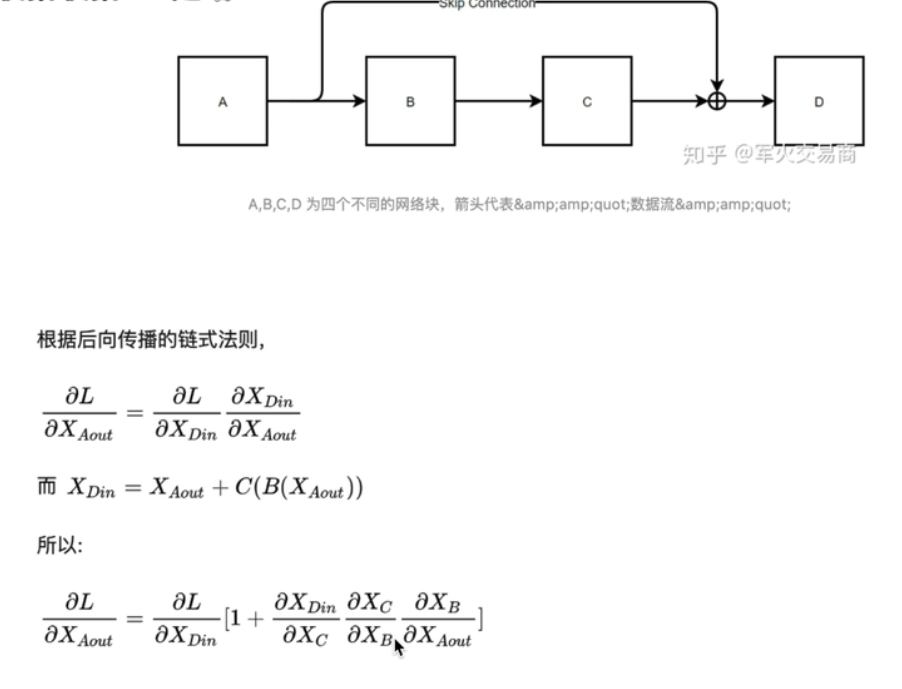
图2
【注】这里的X(Aout)也就是图2中A的输出也即是图1中的X。
【注】一般梯度的消失时由于连乘的出现导致的,然而残差网络由于公式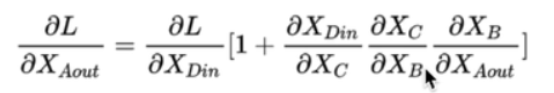
中1的存在缓解了梯度消失的出现。
2.3.2Layer Normalization(Batch Normalization效果差,所以不用):
2.3.2.1BN:
BN优点:

BN的缺点:


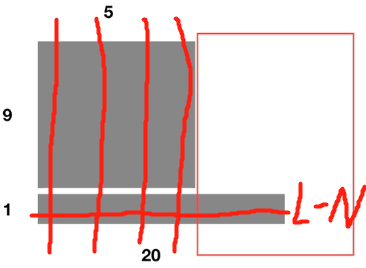
例如Batchsize为10,前9个样本的单词数量为5,最后一个样本的单词数量为20:
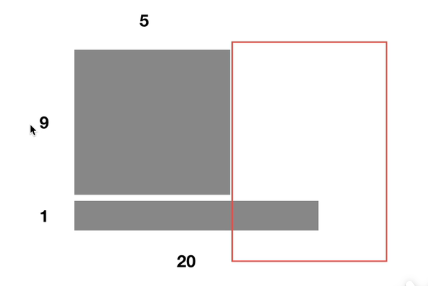
【注1】由于前5个均值和方差可以通过10个样本计算,则第6-第20个单词的只有最后一个样本有,则导致在计算第6-第20个单词的均值和方差时Batchsize较小。
【注2】BN之所以在RNN中不好,是由于RNN的输入时动态的,可能会出现【注1】中的情况。
2.3.2.2Lay-Norm

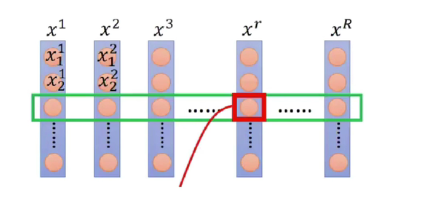
【注】假设一个batch包含X1,X2,X3.......X(R),X(R)表示了R个人,则X1(1),X1(2)........分别为人X1的不同特征。此种类型的数据,用BN作均值和方差计算更为合理。

【注】对于自然语言处理,BN计算均值和方差显然没有LN方式进行计算均值和方差合理。
2.4前馈神经网络
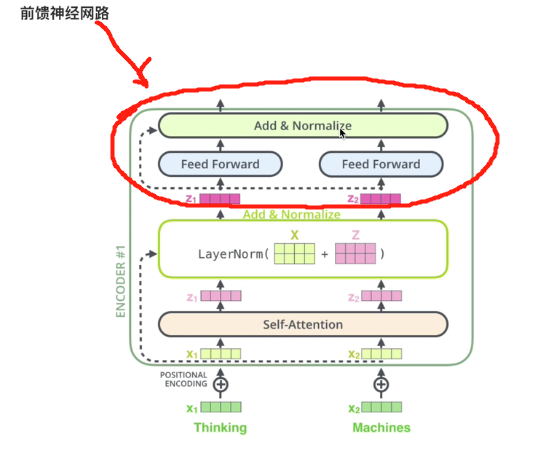
上图中TRM的前馈神经网络是由:两个全连接层和1个残差结构组成
3:decoder详解
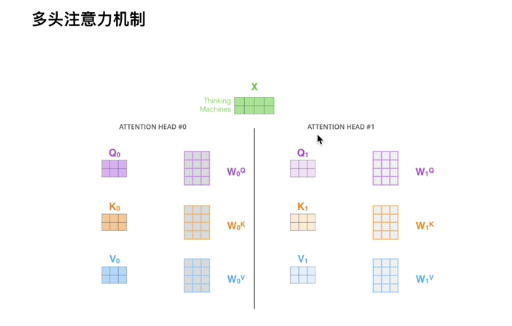
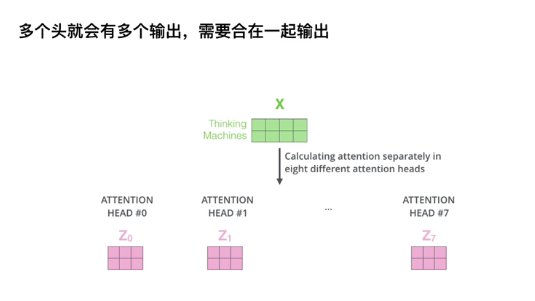
3.1多头注意力机制
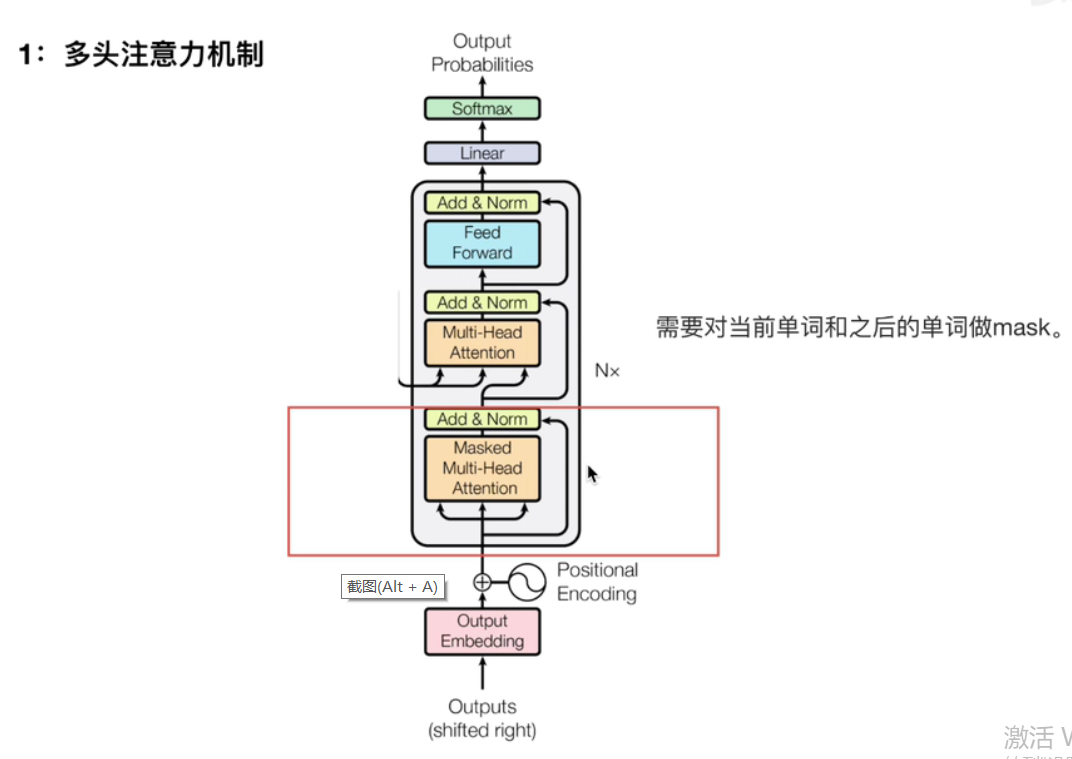
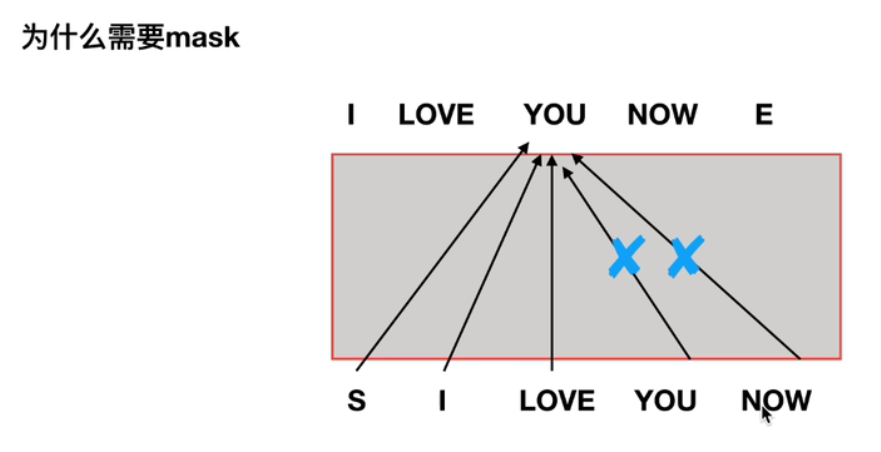
【注】因为进行模型训练时,是能看到当前训练单词之后的单词的。然而在进行预测时,模型是不知道将要预测出的单词之后的单词的。因此会造成不一致,导致模型的效果变差。故可以通过mask在训练时就将正在训练的单词之后的单词掩盖掉。
3.2交互层
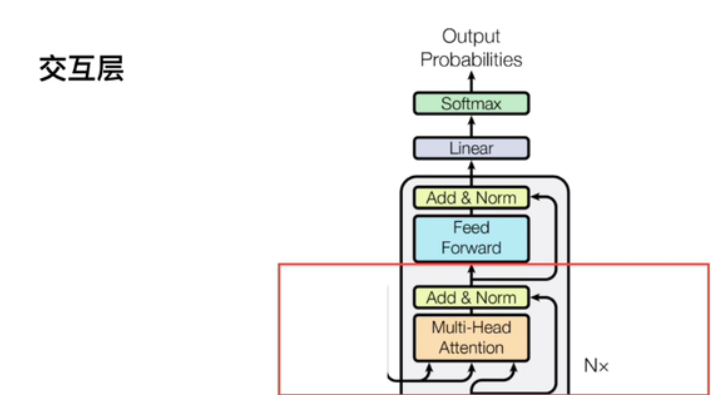
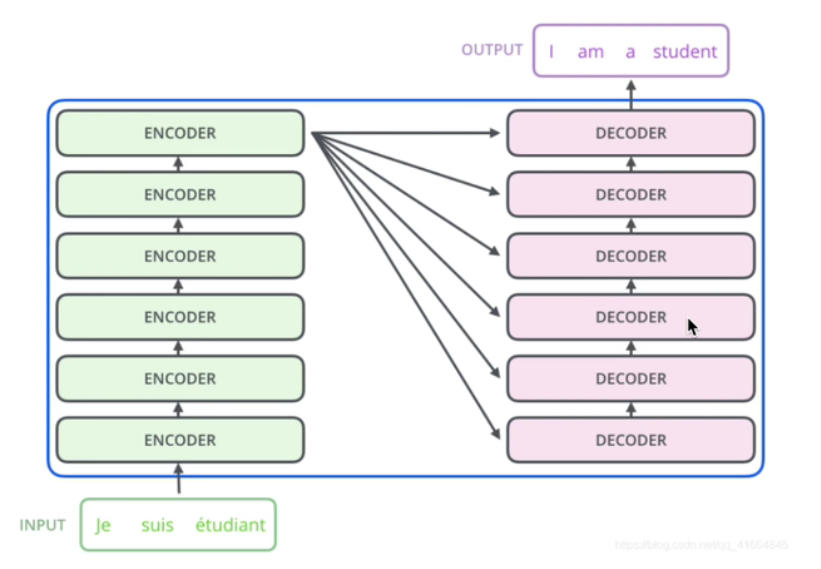
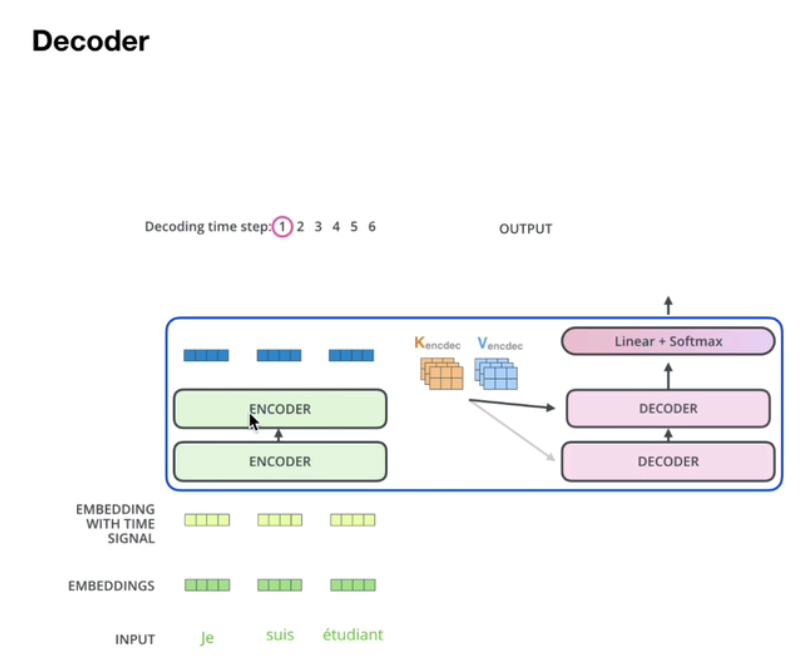
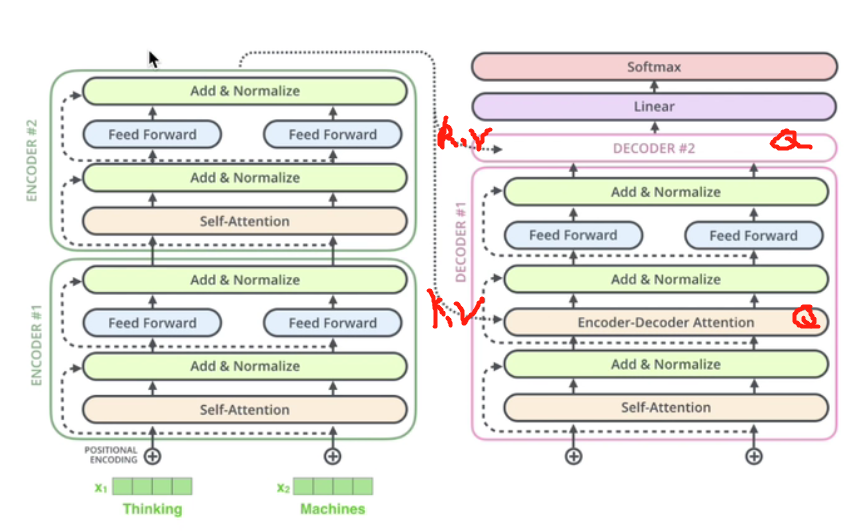
【注】交互层的K,V矩阵是来自encoder,Q矩阵来自decoder。两者交互生成多头注意力机制。