Java的文件IO流处理方式
Java MappedByteBuffer & FileChannel & RandomAccessFile & FileXXXputStream 的读写。
Java的文件IO读取介绍
Java在JDK 1.4引入了ByteBuffer等NIO相关的类,使得 Java 程序员可以抛弃基于 Stream ,从而使用基于 Block 的方式读写文件,java io操作中通常采用BufferedReader,BufferedInputStream等带缓冲的IO类处理大文件,不过java nio中引入了一种基于MappedByteBuffer操作大文件的方式,其读写性能极高,本文会介绍其性能如此高的内部实现原理,分析一下到底是 FileChannel 快还是 MappedByteBuffer 块。
此外,JDK 还引入了 IO 性能优化之王—— 零拷贝 sendFile 和 mmap。但他们的性能究竟怎么样? 和 RandomAccessFile 比起来,快多少? 什么情况下快?
Java的文件IO流技术痛点
如果我们要做超大文件的读写(2G以上)。使用传统的流读写,很有可能内存会直接爆了,几乎不可能完成。
MappedByteBuffer
MappedByteBuffer的一个能力就是它可以让我们读写那些因为太大而不能放进内存中的文件。有了它,我们就可以假定整个文件都放在内存中(实际上,大文件放在内存和虚拟内存中),基本上都可以将它当作一个特别大的数组来访问,这样极大的简化了对于大文件的修改等操作。
MappedByteBuffer的技术原理
MappedByteBuffer底层使用的技术是内存映射。所以讲MappedByteBuffer之前,先讲下计算机的内存管理,先看看计算机内存管理的几个术语:
-
MMU:CPU的内存管理单元。
-
物理内存:即内存条的内存空间。
-
虚拟内存:计算机系统内存管理的一种技术,它可以让程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
-
页面映像文件:虚拟内存一般使用的是页面映像文件,即硬盘中的某个(某些)特殊的文件,操作系统负责页面文件内容的读写,这个过程叫"页面中断/切换"。
-
页文件:操作系统反映构建并使用虚拟内存的硬盘空间大小而创建的文件,在windows下,即pagefile.sys文件,其存在意味着物理内存被占满后,将暂时不用的数据移动到硬盘上。
-
缺页中断:当程序试图访问已映射在虚拟地址空间中但未被加载至物理内存的一个分页时,由MMC发出的中断。如果操作系统判断此次访问是有效的,则尝试将相关的页从虚拟内存文件中载入物理内存。
虚拟内存和物理内存
如果正在运行的一个进程,它所需的内存是有可能大于内存条容量之和的,如内存条是256M,程序却要创建一个2G的数据区,那么所有数据不可能都加载到内存(物理内存),必然有数据要放到其他介质中(比如硬盘),待进程需要访问那部分数据时,再调度进入物理内存。
什么是虚拟内存地址和物理内存地址?
假设你的计算机是32位,那么它的地址总线是32位的,也就是它可以寻址00xFFFFFFFF(4G)的地址空间,但如果你的计算机只有256M的物理内存0x0x0FFFFFFF(256M),同时你的进程产生了一个不在这256M地址空间中的地址,那么计算机该如何处理呢?回答这个问题前,先说明计算机的内存分页机制。
分页和页帧
计算机会对虚拟内存地址空间(32位为4G)进行分页从而产生页(page),对物理内存地址空间(假设256M)进行分页产生页帧(page frame),页和页帧的大小一样,所以虚拟内存页的个数势必要大于物理内存页帧的个数。
页表
在计算机上有一个页表(page table),就是映射虚拟内存页到物理内存页的,更确切的说是页号到页帧号的映射,而且是一对一的映射。
内存页的失效化
虚拟内存页的个数 > 物理内存页帧的个数,岂不是有些虚拟内存页的地址永远没有对应的物理内存地址空间?不是的,操作系统是这样处理的。操作系统有个页面失效(page fault)功能。
操作系统找到一个最少使用的页帧(LFU),使之失效,并把它写入磁盘,随后把需要访问的页放到页帧中,并修改页表中的映射,保证了所有的页都会被调度。
虚拟内存地址和物理内存地址
虚拟内存地址:由页号(与页表中的页号关联)和偏移量(页的小大,即这个页能存多少数据)组成。
虚拟内存转换到物理内存的过程
举个例子,有一个虚拟地址它的页号是4,偏移量是20,那么他的寻址过程是这样的:首先到页表中找到页号4对应的页帧号(比如为8),如果页不在内存中,则用失效机制调入页,接着把页帧号和偏移量传给MMU组成一个物理上真正存在的地址,最后就是访问物理内存的数据了。
总结说明
对大多数操作系统来说,做内存文件映射都是一个昂贵的操作。所以MappedByteBuffer适用于对大文件的读写。对于小文件直接用普通的读写就好了。
使用MappedByteBuffer案例
MappedByteBuffer继承自ByteBuffer,拥有变动position和limit指针啦、包装一个其他种类Buffer的视图啦,你可以把整个文件(不管文件有多大)看成是一个ByteBuffer。
- java.lang.Object
- java.nio.Buffer
- java.nio.ByteBuffer
- java.nio.MappedByteBuffer
简单的读写示例
public class MappedByteBufferTest {
public static void main(String[] args) {
File file = new File("D://data.txt");
long len = file.length();
byte[] ds = new byte[(int) len];
try {
MappedByteBuffer mappedByteBuffer = new RandomAccessFile(file, "r")
.getChannel()
.map(FileChannel.MapMode.READ_ONLY, 0, len);
for (int offset = 0; offset < len; offset++) {
byte b = mappedByteBuffer.get();
ds[offset] = b;
}
Scanner scan = new Scanner(new ByteArrayInputStream(ds)).useDelimiter(" ");
while (scan.hasNext()) {
System.out.print(scan.next() + " ");
}
} catch (IOException e) {}
}
}
MappedByteBuffer存在的问题
使用MappedByteBuffer整个过程非常快,映射的字节缓冲区是通过FileChannel.map 方法创建的,映射的字节缓冲区和它所表示的文件映射关系在该缓冲区本身成为垃圾回收缓冲区之前一直保持有效。
官方解释
The buffer and the mapping that it represents will remain valid until the buffer itself is garbage-collected.A mapping, once established, is not dependent upon the file channel that was used to create it. Closing the channel, in particular, has no effect upon the validity of the mapping.
这就可能一些问题,主要就是内存占用和文件关闭等不确定问题。被MappedByteBuffer打开的文件只有在垃圾收集时才会被关闭,而这个点是不确定的。
比如说,先用MappedByteBuffer map到一个源文件。进行复制操作。结束后想删掉源文件。删除是会失败的,主要原因是变量MappedByteBuffer仍然持有源文件的句柄,文件处于不可删除状态。
官方并没有给出释放句柄的操作,不过可以尝试一下的方式:
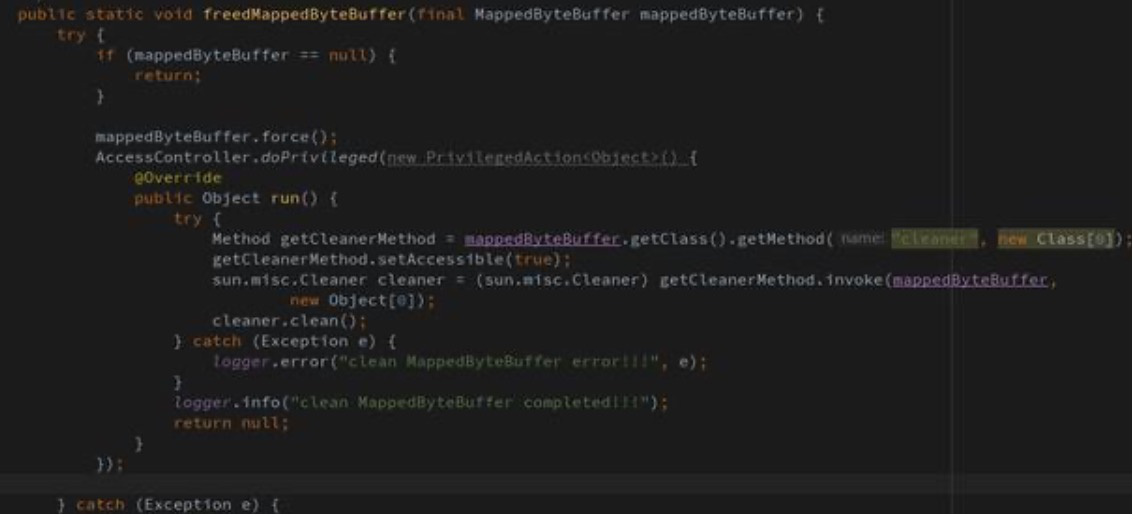
实际需求案例场景
拷贝一个文件,在拷贝完成之后将源文件删除 使用MappedByteBuffer 进行操作
但是MappedByteBuffer和它和他相关联的资源 在垃圾回收之前一直保持有效 但是MappedByteBuffer保存着对源文件的引用 ,因此删除源文件失败。
public static void copyFileAndRemoveResource() {
File source = null;
File dest = null;
MappedByteBuffer buf = null;
try {
source = new File("D:\\eee.txt");
dest = new File("C:\\eee.txt");
} catch (NullPointerException e) {
e.printStackTrace();
}
try (FileChannel in = new FileInputStream(source).getChannel();
FileChannel out = new FileOutputStream(dest).getChannel();) {
long size = in.size();
buf = in.map(FileChannel.MapMode.READ_ONLY, 0, size);
out.write(buf);
buf.force();// 将此缓冲区所做的内容更改强制写入包含映射文件的存储设备中。
System.out.println("文件复制完成!");
// System.gc();
// 同时关闭文件通道和释放MappedByteBuffer才能成功
in.close();//如果在关闭之前抛异常也不怕,因为使用了try-with-resource
// 强制释放MappedByteBuffer资源
clean(buf);
// 文件复制完成后,删除源文件
/*
* source.delete() 删除用此抽象路径名所表示的文件或目录,如果该路径表示的是一个目录 则该目录必须为空文件夹才可以删除
* 注意:使用java.nio.file.Files的delete方法能告诉你为什么会删除失败
* 所以尽量使用Files.delete(Paths.get(pathName));来替代File对象的delete
* System.out.println(source.delete() == true ? "删除成功!" : "删除失败!");
*/
Files.delete(Paths.get("D:\\eee.txt"));
System.out.println("删除成功!");
} catch (Exception e) {
e.printStackTrace();
}
public static void clean(final MappedByteBuffer buffer) throws Exception {
if (buffer == null) {
return;
}
buffer.force();
AccessController.doPrivileged(new PrivilegedAction<Object>() {//Privileged特权
@Override
public Object run() {
try {
// System.out.println(buffer.getClass().getName());
Method getCleanerMethod = buffer.getClass().getMethod("cleaner", new Class[0]);
getCleanerMethod.setAccessible(true);
sun.misc.Cleaner cleaner = (sun.misc.Cleaner) getCleanerMethod.invoke(buffer, new Object[0]);
cleaner.clean();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
});
/*
*
* 在MyEclipse中编写Java代码时,用到了Cleaner,import sun.misc.Cleaner;可是Eclipse提示:
* Access restriction: The type Cleaner is not accessible due to
* restriction on required library *\rt.jar Access restriction : The
* constructor Cleaner() is not accessible due to restriction on
* required library *\rt.jar
*
* 解决方案1(推荐): 只需要在project build path中先移除JRE System Library,再添加库JRE
* System Library,重新编译后就一切正常了。 解决方案2: Windows -> Preferences -> Java ->
* Compiler -> Errors/Warnings -> Deprecated and trstricted API ->
* Forbidden reference (access rules): -> change to warning
*/
}
}
其实讲到这里该问题的解决办法已然清晰明了了——就是在删除索引文件的同时还取消对应的内存映射,删除mapped对象。
不过令人遗憾的是,Java并没有特别好的解决方案——令人有些惊讶的是,Java没有为MappedByteBuffer提供unmap的方法,该方法甚至要等到Java 10才会被引入 ,DirectByteBufferR类是不是一个公有类class DirectByteBufferR extends DirectByteBuffer implements DirectBuffer 使用默认访问修饰符
不过Java倒是提供了内部的“临时”解决方案——DirectByteBufferR.cleaner().clean() 切记这只是临时方法。
- 毕竟该类在Java9中就正式被隐藏了,而且也不是所有JVM厂商都有这个类。
- 还有一个解决办法就是显式调用System.gc(),让gc赶在cache失效前就进行回收。
- 不过坦率地说,这个方法弊端更多:首先显式调用GC是强烈不被推荐使用的,其次很多生产环境甚至禁用了显式GC调用,所以这个办法最终没有被当做这个bug的解决方案。
map过程
FileChannel提供了map方法把文件映射到虚拟内存,通常情况可以映射整个文件,如果文件比较大,可以进行分段映射。
FileChannel中的几个变量
- MapMode mode:内存映像文件访问的方式,共三种:
- MapMode.READ_ONLY:只读,试图修改得到的缓冲区将导致抛出异常。
- MapMode.READ_WRITE:读/写,对得到的缓冲区的更改最终将写入文件;但该更改对映射到同一文件的其他程序不一定是可见的。
- MapMode.PRIVATE:私用,可读可写,但是修改的内容不会写入文件,只是buffer自身的改变,这种能力称之为”copy on write”。
- position:文件映射时的起始位置。
- allocationGranularity:Memory allocation size for mapping buffers,通过native函数initIDs初始化。
利用 IO 零拷贝的 MQ 们
Java 世界有很多 MQ:ActiveMQ,kafka,RocketMQ,去哪儿 MQ,而他们则是 Java 世界使用 NIO 零拷贝的大户。
然而,他们的性能却大相同,抛开其他的因素,例如网络传输方式,数据结构设计,文件存储方式,我们仅仅讨论 Broker 端对文件的读写,看看他们有什么不同。
总结的各个 MQ 使用的文件读写方式。
-
kafka:record 的读写都是基于 FileChannel。index 读写基于 MMAP。
-
RocketMQ:读盘基于 MMAP,写盘默认使用 MMAP,可通过修改配置,配置成 FileChannel,原因是作者想避免 PageCache 的锁竞争,通过两层架构实现读写分离。
-
QMQ: 去哪儿 MQ,读盘使用 MMAP,写盘使用 FileChannel。
-
ActiveMQ 5.15: 读写全部都是基于 RandomAccessFile,这也是我们抛弃 ActiveMQ 的原因。
MMAP 众所周知,基于 OS 的 mmap 的内存映射技术,通过MMU映射文件,使随机读写文件和读写内存相似的速度。