大纲
- 字典的数据结构
- 字典的特性
一、字典的数据结构
字典的实现和java的hashmap很像,dictht就是一个哈希表
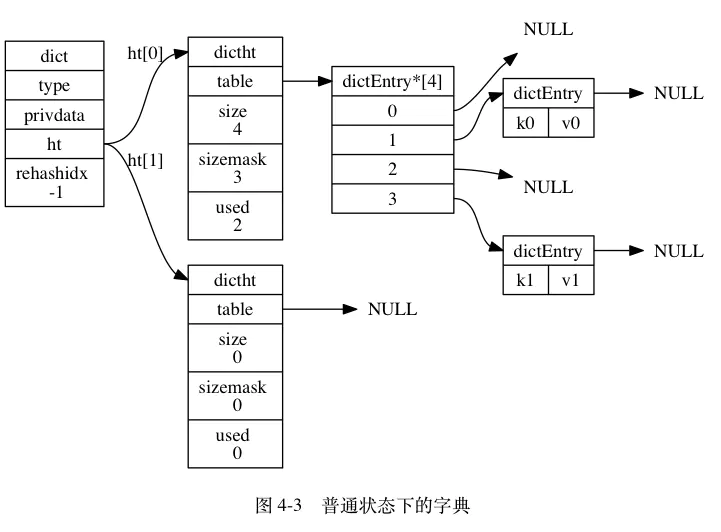
typedef struct dict { // 类型特定函数 dictType *type; // 私有数据保存了传给type的可选参数 void *privdata; // 哈希表,一个用于平时保存,一个用于rehash dictht ht[2]; // rehash 索引,记录当前rehash进行到数组的下标 // 当 rehash 不在进行时,值为 -1 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ } dict;
typedef struct dictht { // 哈希表数组 dictEntry **table; // 哈希表大小,数组大小 unsigned long size; // 哈希表大小掩码,用于计算索引值。hash计算后&掩码,比如掩码为3,&操作后,得到(0,1,2,3)就是数组的下标 // 总是等于 size - 1 unsigned long sizemask; // 该哈希表已有节点的数量 unsigned long used; } dictht;
typedef struct dictEntry { // 键 void *key; // 值,union是三选一 union { void *val; uint64_t u64; int64_t s64; } v; // 指向下个哈希表节点,形成链表 struct dictEntry *next; } dictEntry;
二、字典的特性
- 哈希冲突时,链表头插,时间复杂度O(1)
- 当保存或删除数据后,load factor(used/size)不在合理范围内后将进行rehash,ht[0]rehash后所有值存到ht[1],然后释放ht[0]再将ht[0]=ht[1],最后创建ht[1]为下次rehash做准备
- load factor在没有bgsave和aof操作时为1,再bgsave和aof操作时是5,超过load factor会扩容,当load factor小于0.1时会缩容
- rehash过程为渐进性rehash,并非一次性完成,因为键很多时,会导致服务阻塞。单次完成后会记录rehashidx,rehash期间增加结点操作只在ht[1]完成,而查找操作会先找ht[0]若没有再找ht[1]