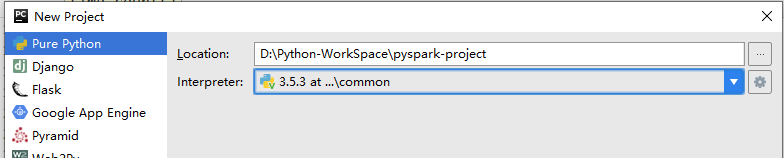
创建新的空项目:
测试一下环境是否ok

同时,也是为了配置一下spark环境
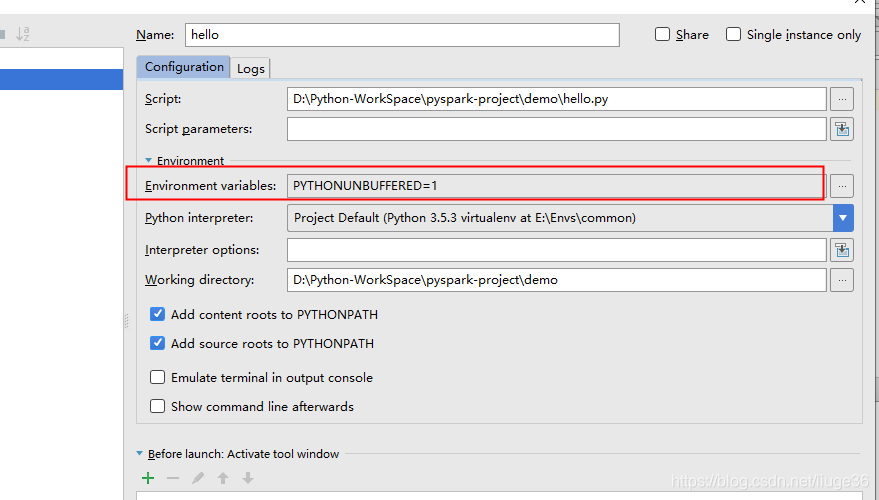
添加如下两个环境变量:
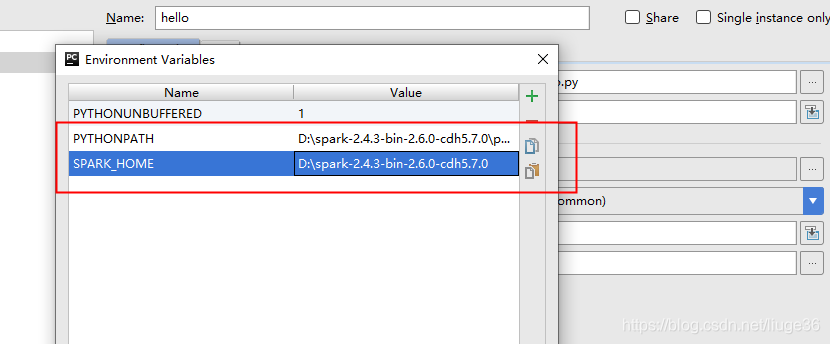
接下来:
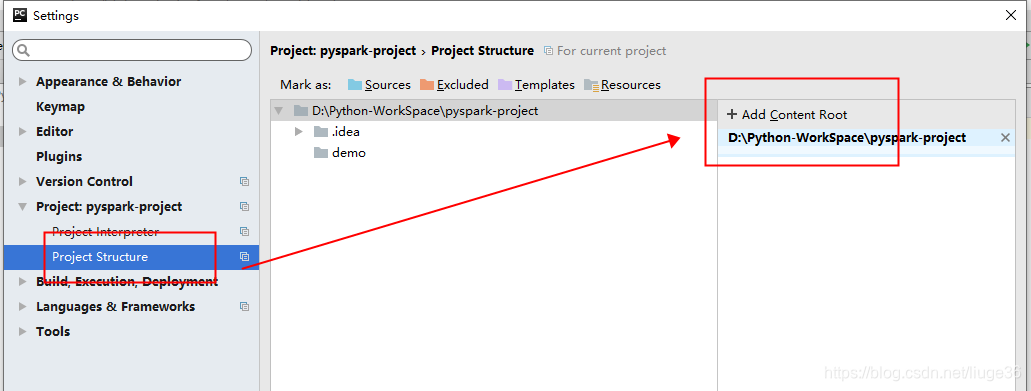
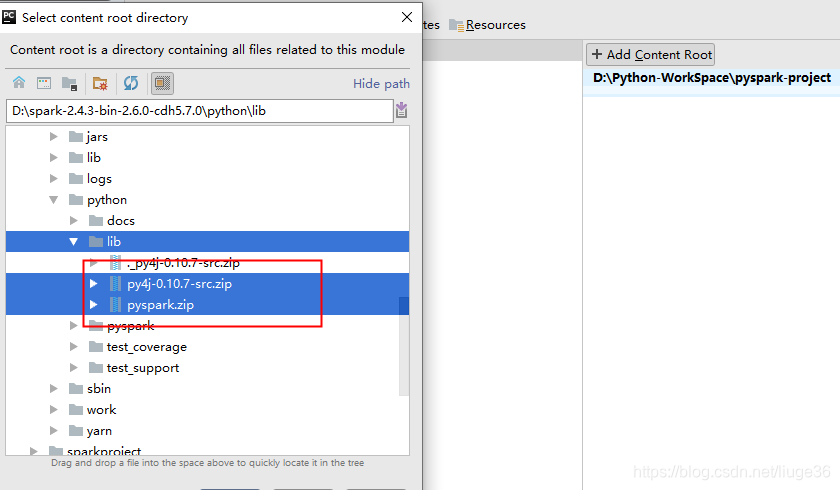
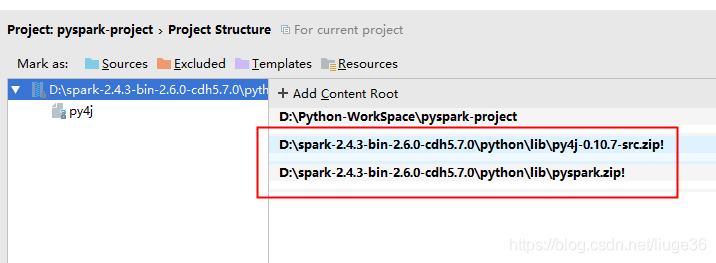
达到这样,就ok
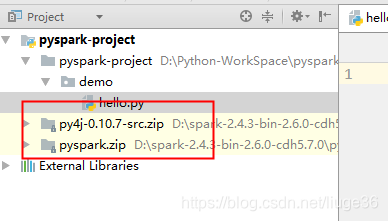
IDE开发环境就配置ok了,开始Coding…
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':
def my_map():
conf = SparkConf().setMaster("local[2]").setAppName("spark-demo0401")
sc = SparkContext(conf=conf)
data = [1, 2, 3, 4, 5]
inputRDD = sc.parallelize(data)
mapRDD = inputRDD.map(lambda x:x*2)
print(mapRDD.collect())
sc.stop()
def my_filter():
conf = SparkConf()
sc = SparkContext(conf=conf)
data = [1,2,3,4,5]
inputRDD = sc.parallelize(data)
output = inputRDD.map(lambda x:x*2).filter(lambda x:x>4)
print(output.collect())
def my_flatMap():
conf= SparkConf()
sc = SparkContext(conf=conf)
data = ["hello,spark","hello,world","hello,pyspark"]
inputRDD = sc.parallelize(data)
output = inputRDD.flatMap(lambda x:x.split(","))
print(output.collect())
def my_groupByKey():
conf = SparkConf()
sc = SparkContext(conf=conf)
data = ["hello,spark", "hello,world", "hello,pyspark"]
inputRDD = sc.parallelize(data)
.flatMap(lambda x:x.split(","))
.map(lambda x:(x,1))
output = inputRDD.groupByKey().collect()
print(output)
def my_reduceByKey():
conf = SparkConf()
sc = SparkContext(conf=conf)
data = ["hello,spark", "hello,world", "hello,spark"]
inputRDD = sc.parallelize(data)
.flatMap(lambda x: x.split(","))
.map(lambda x: (x, 1))
.reduceByKey(lambda x,y:x+y)
output = inputRDD.collect()
print(output)
def my_sortByKey():
conf = SparkConf()
sc= SparkContext(conf=conf)
data = ["hello,spark", "hello,world", "hello,spark"]
inputRDD = sc.parallelize(data).flatMap(lambda x:x.split(","))
.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
.map(lambda x:(x[1],x[0])).sortByKey(ascending=False).map(lambda x:(x[1],x[0]))
print(inputRDD.collect())
my_sortByKey()