在开始本篇主要内容前,我们一起看看下面的几张截图,首先是第一张图,如下图所示:
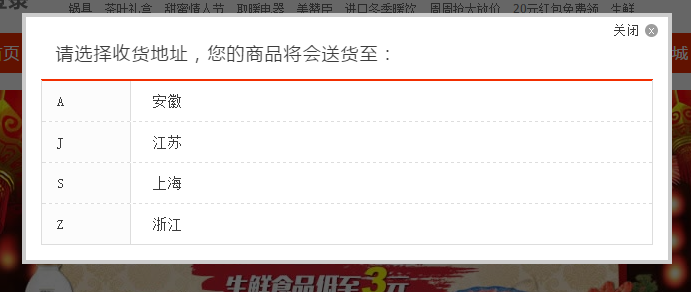
这是一家电商网站的首页,当我们第一次打开这个首页,网站会弹出一个强制性的对话框,让用户选择货物配送的地址,如果是淘宝和京东的话,那么这个选择配货地址的选项是在商品里,如下图是淘宝的选择配送地点:

下图是京东选择配货地点:
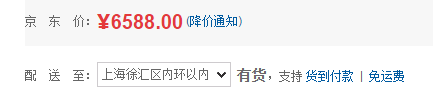
那么图一跟京东和淘宝有什么区别呢?图一的电商强制用户选择地区后,那么我们在查询这个商品时候会因为地区不同,显示的查询结果会不一样,这个就和网站做国际化有点像,不过网站国际化是切语言和语言相关的静态资源,但是电商这个地域的选择是和业务相关的,不同的地域查询结果是不相同的,这个选择地域的弹出框很像一个路由器。相比之下,淘宝和京东把商品的配送和商品相关,那么我们在这些网站里查询商品时候,其实是按照全国查询的,全国不同的地方查询同一个条件所获得到的结果是一致的。从业务角度而言,这说明第一个电商的业务没有全国铺开,就算是铺开了,地域的差异也影响到物流的问题,而淘宝和京东则正是一个全国意义的大型电商网站了。
回到技术的角度,这两种不同的做法有没有可能还和技术问题有关了?今天我就来探讨下这个问题。
不管网站大与小,一个网站肯定可以分为客户端、服务端和存储端,勾连这不同的组成部分是网络,网络是一种通讯设施,距离的远近会直接影响到网络传输的效率问题,如是乎就出现了像CDN这样的技术,很多大型互联网公司还会在不同的城市建立机房,这些手段的目的就是在解决距离对网络传输效率的影响,但是当这种就近解决问题的方案落到存储层的时候,问题就来了。上篇里我说道web服务的水平扩展问题,这种水平扩展是基于一种无状态性的原理设计的,但是到了存储层我们不管怎么拆分它,它都很难消除状态的问题,也就是存储层有状态性是它的天然属性。特别是碰到一个竞争性的存储资源时候,这种状态性会变得非常顽固,例如商品的库存问题,如果我们把库存数据对等的平移到不同地域的数据中心,那么如何保证不同地方的库存信息总是准确的,这就成为了难题。这种问题放在一个小国家不是什么问题,但是放到地大物博的中国那就很成问题了。所以存储是这种就近方案的短板了。
我曾了解到中国一家大型信息企业在设计它们第一代系统时候,就考虑到了这种地域性差异对系统设计的影响,它们的第一代系统在存储层这块就设计成了一个双核系统,什么叫做存储层的双核系统了?它们的做法是在北京和上海分别建立两个数据中心,系统的存储层分别部署在北京的数据中心和上海的数据中心,两个数据中心是等价的,那么中国北部的交易就走北京数据中心,中国南部的交易就走上海的数据中心。但是系统上线后,发现这种双核设计方案成为了整个系统的梦魇了,这个梦魇的最核心的问题就是数据的同步问题,因为该企业是一个全国性业务的企业,因此有大量交易需要南北数据中心同步完数据后才能正常完成,但是想从北京和上海同步数据的效率是异常的低效,我曾经看过一份资料,里面说有机构做了一个测试,当两个数据中心的距离超过了80公里,那么网络的延迟性基本是无法忍受的,当然不差钱的企业可以专门铺设专线来连接两个数据中心,这种专线的成本高的吓人,我曾听人说就在上海,如果铺专线从浦东到浦西,那么这条专线基本是用人民币铺就的,更何况是从北京到上海铺专线,就算企业不差这些钱延迟性也严重影响了企业业务的发展。除了延迟性外,通过网络大规模传输数据,数据的可靠性是很难保证的,也就是网络传输时候经常没有道理的丢包,这就造成了很多重复性传输,使得同步数据的效率更加的低效。
因为存储层这种双核设计缺陷,该企业马上从事了二代系统的设计和开发,而这个二代系统核心业务就是解决这个存储层的双核问题。那到底该怎么解决了?把双核变成单核,既然两个数据中心这么麻烦,那我们就搞一个数据中心算了,既省钱有没那么多麻烦事情,这个肯定不是解决问题的正确思路了,双核设计的出发点是非常有现实意义和价值的,最后该公司使用了一个新的方案替代双核,这个方案称之为主备方案,存储层任然部署到两个数据中心,到了业务运行阶段,一个数据中心为主,一个数据中心为辅,不过这个主备方案绝不是通常意义的数据备份方案,他其实是吸收了单核和双核方案的优点,同时尽量避免单核和双核的缺点,那么这点上这个主备方案是如何做到的呢?
首先我们还是要把系统业务交易分下类,系统有些交易对于实时性啊,数据的正确性啊要求非常高,那么这样的业务场景使用单核存储系统比较合适,一个业务系统不可能全是这样的实时性交易,也有一些交易对实时性要求比较差,当然我们还是得要考察下这种交易对于延时容忍度,具体就是一般延时多久用户是可以接受的,这点非常重要,因为就算是主备方案,那么数据还是会有同步的操作,只不过这个同步的时间粒度上会更粗些,我们可以以系统和业务角度合理设置一个同步时间间隔,如果延时性交易的延时时间超过了这个间隔时间的话,那么这样的业务场景其实是可以就近处理的,没有必要将这些请求都发送到主数据中心,这样可以减轻主数据中心的运行压力。该企业的二代信息系统还有个要求就是过了每天的零点,前一天的数据必须在两个数据中心完成同步,换句话说,两个数据中心数据的差异性最大容忍度是天,为什么要这样做了?有的朋友看到了一定认为这是为了备份数据,的确这是目的之一,但这个做法还有更大的深意,双核设计除了解决距离对网络效率的影响外,还有个重要的目的就是容灾,我记得几年前,有个朋友告诉我他们公司网站挂了6个小时,我当时很奇怪,我就问你们系统难道不是分布式吗?他说他们线上系统没有单点,那为什么网站还会整个挂掉了?答案真的让人不敢相信,因为他们的机房漏雨了,机房的线路短路了,那个朋友告诉我这件事情以后,他们公司又在附近租了个新机房做容灾,防止此类事情再发生了。这种情况真的可以称之为天灾了,不过这样的事情概率很低,可是一旦发生就会非常致命,记得日本爆发九级大地震的时候,我看到一个新网报道,报道里面有好多大型计算机倒掉了,而这个机房的机器的作用几乎关系到亚洲互联网系统的命脉,大家都知道每个网站都有自己的域名,域名是一个网站的入口,而日本那个机房放置的服务器就是全球赫赫有名的13台服务器之一,专门用来解析域名的DNS服务器,如果这些机器挂掉了,可能发生一整个国家都不能正常使用互联网。但是天灾毕竟是局部的,因此全国甚至全球设立不同的数据中心用来容灾是很多大型互联网公司必须走的道路,回到本文的主备方案,为了保证数据中心的容灾性,那么我们再设计主备方案同时还要保证主备数据中心可以迅速切换,当一个数据中心出现问题时候可以马上把辅助的数据中心转化为主数据中心。为了保证这种切换的可靠性,该企业经常在晚上交易量小的时候,把主备来回切换跑跑。
回到开篇提到的那三张截图,那个一开始弹出地域选择框的电商网站,当我们选择不同的地域时候,查询同样的商品最后显示的商品列表是不同,而京东虽然也有地域选择,但是我们切换地域后查询商品后结果基本没有变化,至于淘宝和天猫压根就没有让我们选择地域的选项,配送都是在商品这边进行选择的。可能淘宝和天猫没有自营业务,因此天猫很难控制里面商家的地域区别,京东和前面哪家电商网站因为大部分是直营业务,因此配送地址和他们仓储所在地是有关系的,其实这个做法衍生下的话,地域其实还可以做到数据中心的划分,例如江沪浙用一个数据中心,中部地区用一个数据中心,那么这种方式就可以帮助我们解决存储层的就近问题,从这里我们似乎也可以看出B2C和C2C的业务场景的一些区别。
由此我可以做一个总结,首先存储层做到对等多核的体系基本是不可能的,主备的方案可以解决单核和多核的缺点,同时可以发扬单核和多核的优点,距离的远近也能产生业务的差异性,我们可以通过这种差异性把数据中心变成分散式,这样还可以解决数据访问的就近原则。
美国的互联网公司规模很大,他们从一开始就是全球化的,那么对于美国的大型互联网公司将数据中心分散化和本地化就变的非常重要,所以好的存储层的分布设计方案是完成网站全球布局任务的基础。但是对于很多中小企业,或者是刚刚创业的公司能在不同地域建立数据中心,或者不差钱但是能快速的建立不同地域的数据中心其实是非常难的事情,那么这个时候我们找一家全球性的云平台例如亚马逊的云平台,或者我们的业务就局限在中国,使用个本土优秀的云平台也是一种不错的选择,云计算的推广使得创业者的成本越来越低了。
好了,本系列的文章到此为止,本系列都是在讲数据库的问题,我曾经说过任何程序或软件都是计算和存储的结合体,本系列着重讲到的是存储,时下很多大型互联网公司在存储这块已经发生了很大的变化,在关系数据库这块都已经做到了去商业关系数据库,而使用开源的关系数据库,并将这些开源的关系数据进行了大规模的改造,这个做法应该算是互联网领域关系数据库发展的前沿了,同时将关系数据库很难做到的事情用Nosql数据库来替代也是一种大趋势。
本系列讲述时候设置了一个很大的前提,那就是尽量保持关系数据库存储的本性,因此我将很多计算建议迁移到应用层,这个观点我有很多理由说明它的好处,但是现实中是否是最好的方法,这个就要具体看了,因此我不想去苛求这么做的合理性,但是逻辑上合理的方案总是会有很多借鉴意义的,这就是我想表达的,至于关于存储层的计算我倾向于在数据访问层里做,因此按照我的思路,最终这个关系数据库存储层就会变成一个分布式数据库,数据访问层当然也是使用分布式系统原理来做,讲解分布式系统也是本文章后续想讨论,如果我有时间接着写这个大系列博客我会在分布式系统这块继续讲解数据访问层的设计问题。
原文:http://www.cnblogs.com/sharpxiajun/p/4280337.html