一、前序工作流程
1. 数据处理
数据清洗
不可信的样本丢掉
缺省值极多的字段考虑不用
数据采样
下/上采样
保证样本均衡
2. 特征工程
特征处理:
数值型 类别型 时间类 文本型 统计型 组合特征
特征选择:
过滤型
sklearn.feature_selection.SelectKBest
包裹型
sklearn.feature_selection.RFE
嵌入型
feature_selection.SelectFromModel
Linear model,L1正则化

3. 模型选择
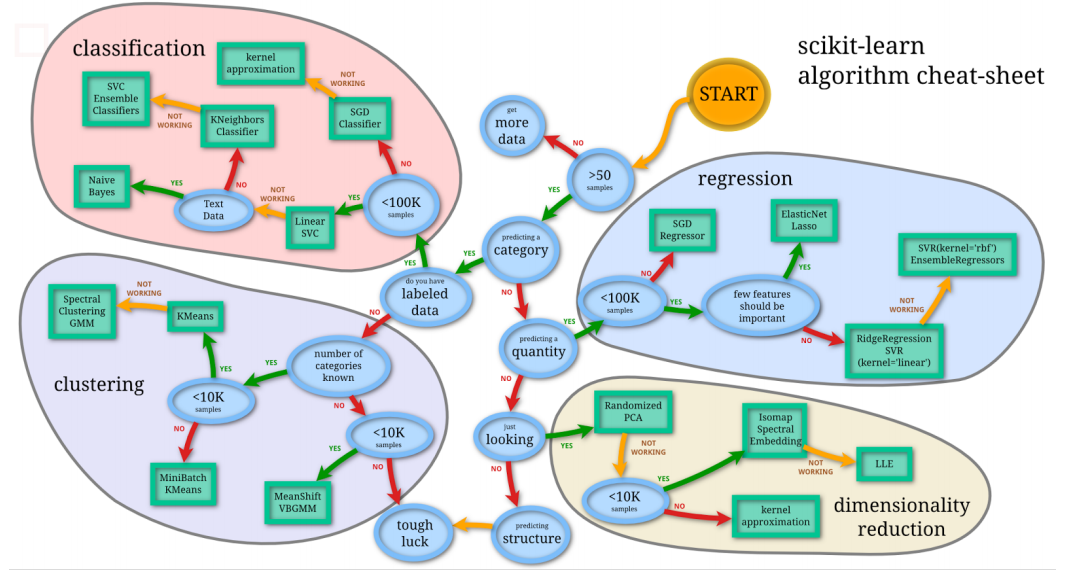
4. 交叉验证(cross validation)
交叉验证集做参数/模型选择
测试集只做模型效果评估
K折交叉验证(K-fold cross validation)

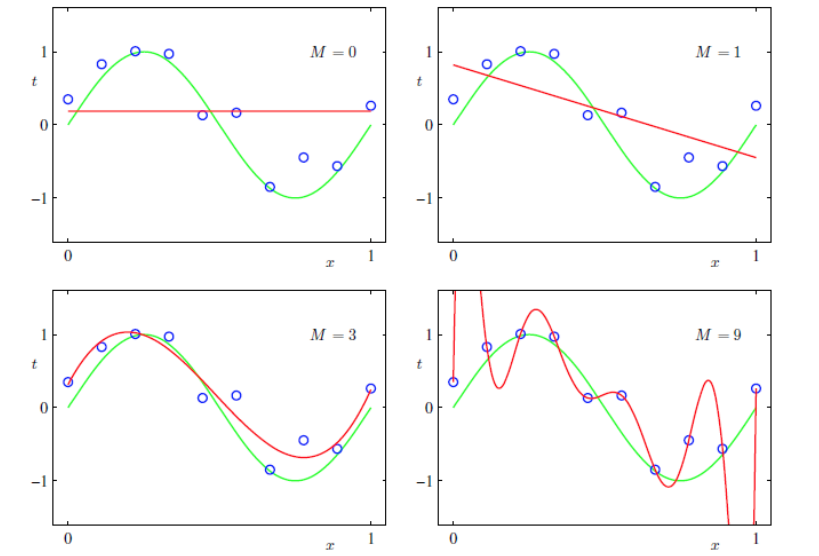
5. 寻找最佳超参数
对模型有何影响:

交叉验证选取:
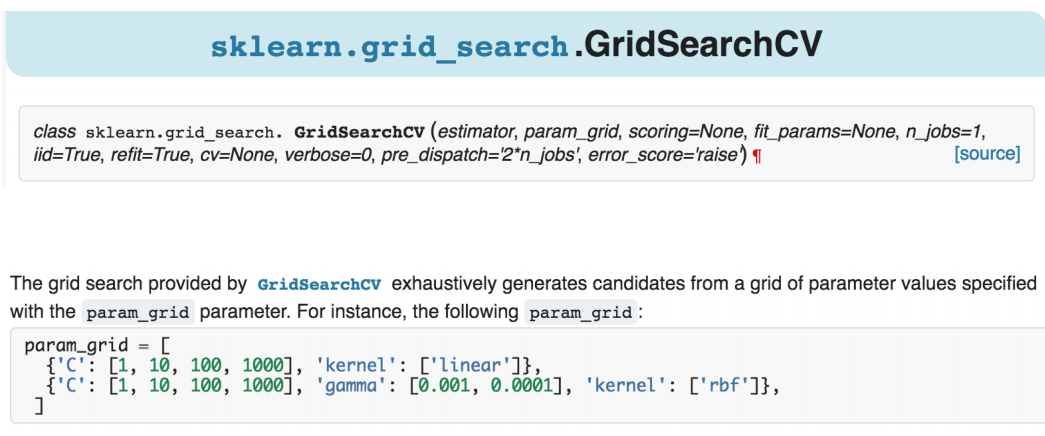
二、模型优化
1. 模型状态
过拟合(overfitting/high variance)
欠拟合(underfitting/high bias)
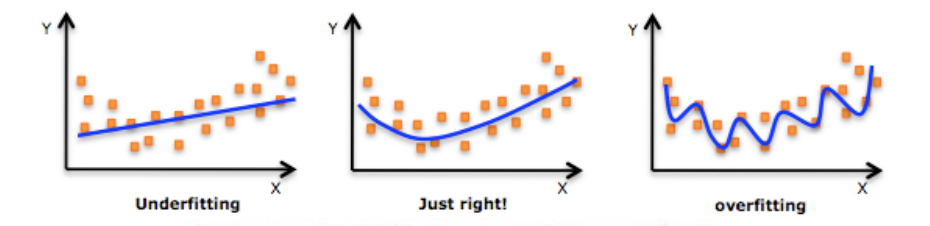
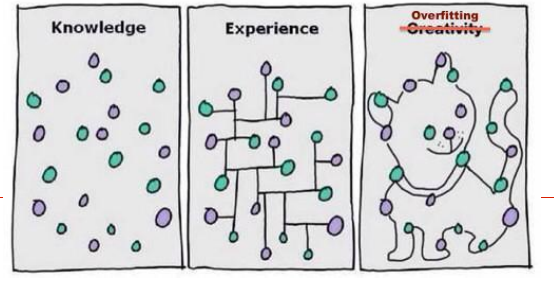
模型状态验证工具:学习曲线
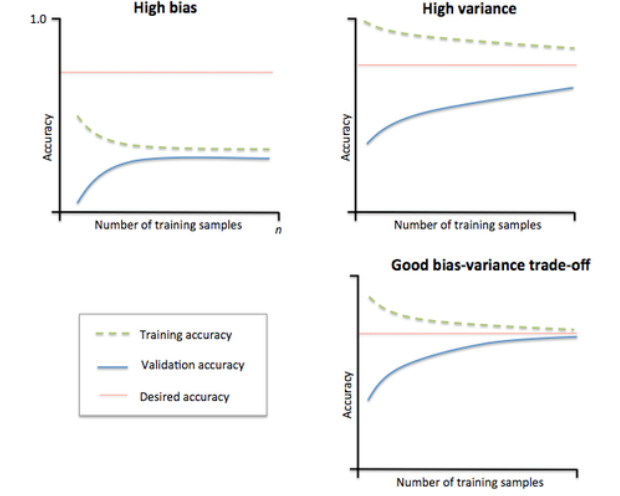
不同模型状态处理
过拟合
找更多的数据来学习
增大正则化系数
减少特征个数(不是太推荐)
注意:不要以为降维可以解决过拟合问题
欠拟合
找更多的特征
减小正则化系数
2. 权重分析
线性模型的权重分析
线性或者线性kernel的model
Linear Regression
Logistic Regression
LinearSVM
…
对权重绝对值高/低的特征
做更细化的工作
特征组合
3. bad-case分析
分类问题
哪些训练样本分错了?
我们哪部分特征使得它做了这个判定?
这些bad cases有没有共性
是否有还没挖掘的特性
…
回归问题
哪些样本预测结果差距大,为什么?
…
4. 模型融合(集成学习)
简单说来,我们信奉2条信条
群众的力量是伟大的,集体智慧是惊人的(并联)
代表算法:Bagging
随机森林/Random forest
一万小时定律(串联、存在依赖)
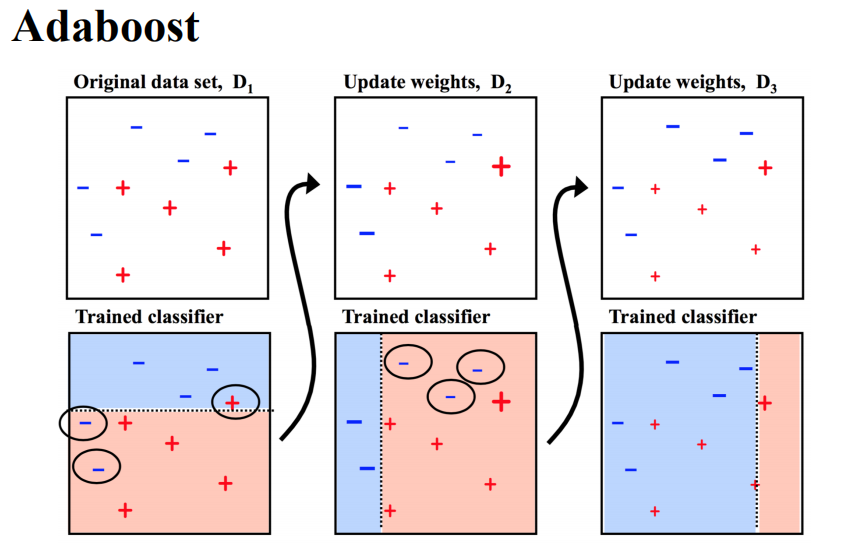
代表算法:Adaboost
逐步增强树/Gradient Boosting Tree
Bagging:
模型很多时候效果不好的原因是什么?
过拟合啦!!!
如何缓解?
少给点题,别让它死记硬背这么多东西
多找几个同学来做题,综合一下他们的答案
用一个算法
不用全部的数据集,每次取一个子集训练一个模型
分类:用这些模型的结果做vote(选举)
回归:对这些模型的结果取平均(均值)
用不同的算法
用这些模型的结果做vote 或 求平均

Adaboost:
考得不好的原因是什么?
还不够努力,练习题要多次学习
重复迭代和训练
时间分配要合理,要多练习之前做错的题
每次分配给分错的样本更高的权重
我不聪明,但是脚踏实地,用最简单的知识不断积累,成为专家
最简单的分类器的叠加
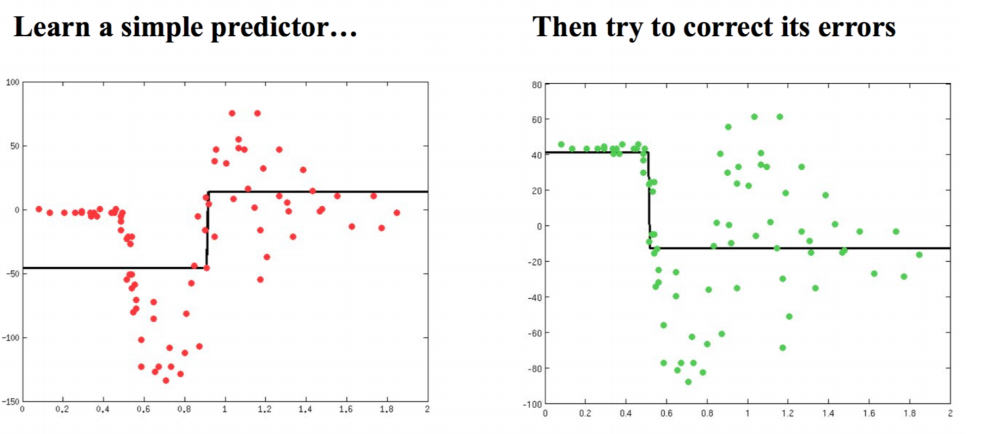
Gradient Boosting Tree:
和Adaboost思路类似,解决回归问题
三、案列讲解
案例1:
经典又兼具备趣味性的Kaggle案例泰坦尼克号问题
大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇的数量有限,无法人人都有,副船长发话了『lady and kid first!』,所以是否获救其实并非随机,而是基于一些背景有rank先后的。
训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。
对,这是一个二分类问题,很多分类算法都可以解决。
看看数据长什么样
还是用pandas加载数据
In [1]:
# 这个ipython notebook主要是我解决Kaggle Titanic问题的思路和过程
import pandas as pd #数据分析
import numpy as np #科学计算
from pandas import Series,DataFrame
data_train = pd.read_csv("Train.csv")
data_train.columns
#data_train[data_train.Cabin.notnull()]['Survived'].value_counts()
Out[1]:
Index([u'PassengerId', u'Survived', u'Pclass', u'Name', u'Sex', u'Age',
u'SibSp', u'Parch', u'Ticket', u'Fare', u'Cabin', u'Embarked'],
dtype='object')
我们看大概有以下这些字段
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
我这么懒的人显然会让pandas自己先告诉我们一些信息
In [3]:
data_train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
上面的数据说啥了?它告诉我们,训练数据中总共有891名乘客,但是很不幸,我们有些属性的数据不全,比如说:
Age(年龄)属性只有714名乘客有记录
Cabin(客舱)更是只有204名乘客是已知的
似乎信息略少啊,想再瞄一眼具体数据数值情况呢?恩,我们用下列的方法,得到数值型数据的一些分布(因为有些属性,比如姓名,是文本型;而另外一些属性,比如登船港口,是类目型。这些我们用下面的函数是看不到的)
In [5]:
data_train.describe()
Out[5]:
PassengerId Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 NaN 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 NaN 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 NaN 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200
mean字段告诉我们,大概0.383838的人最后获救了,2/3等舱的人数比1等舱要多,平均乘客年龄大概是29.7岁(计算这个时候会略掉无记录的)等等…
『对数据的认识太重要了!』
『对数据的认识太重要了!』
『对数据的认识太重要了!』
口号喊完了,上面的简单描述信息并没有什么卵用啊,咱们得再细一点分析下数据啊。
看看每个/多个 属性和最后的Survived之间有着什么样的关系
In [ ]:
import matplotlib.pyplot as plt
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar')# plots a bar graph of those who surived vs those who did not.
plt.title(u"获救情况 (1为获救)") # puts a title on our graph
plt.ylabel(u"人数")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # sets the y axis lable
plt.grid(b=True, which='major', axis='y') # formats the grid line style of our graphs
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde') # plots a kernel desnsity estimate of the subset of the 1st class passanges's age
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()
In [ ]:
于是得到了像下面这样一张图:
bingo,图还是比数字好看多了。所以我们在图上可以看出来:
被救的人300多点,不到半数;
3等舱乘客灰常多;遇难和获救的人年龄似乎跨度都很广;
3个不同的舱年龄总体趋势似乎也一致,2/3等舱乘客20岁多点的人最多,1等舱40岁左右的最多(→_→似乎符合财富和年龄的分配哈,咳咳,别理我,我瞎扯的);
登船港口人数按照S、C、Q递减,而且S远多于另外俩港口。
这个时候我们可能会有一些想法了:
不同舱位/乘客等级可能和财富/地位有关系,最后获救概率可能会不一样
年龄对获救概率也一定是有影响的,毕竟前面说了,副船长还说『小孩和女士先走』呢
和登船港口是不是有关系呢?也许登船港口不同,人的出身地位不同?
口说无凭,空想无益。老老实实再来统计统计,看看这些属性值的统计分布吧。
In [552]:
#看看各乘客等级的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
得到这个图:
啧啧,果然,钱和地位对舱位有影响,进而对获救的可能性也有影响啊←_←
咳咳,跑题了,我想说的是,明显等级为1的乘客,获救的概率高很多。恩,这个一定是影响最后获救结果的一个特征。
In [553]:
#看看各登录港口的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
plt.show()
并没有看出什么...
那个,看看性别好了
In [507]:
#看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()
歪果盆友果然很尊重lady,lady first践行得不错。性别无疑也要作为重要特征加入最后的模型之中。
再来个详细版的好了
In [508]:
#然后我们再来看看各种舱级别情况下各性别的获救情况
fig=plt.figure()
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")
ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc='best')
ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')
ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')
ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')
plt.show()
那堂兄弟和父母呢?
大家族会有优势么?
In [509]:
g = data_train.groupby(['SibSp','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
df
Out[509]:
PassengerId
SibSp Survived
0 0 398
1 210
1 0 97
1 112
2 0 15
1 13
3 0 12
1 4
4 0 15
1 3
5 0 5
8 0 7
In [168]:
g = data_train.groupby(['Parch','Survived'])
df = pd.DataFrame(g.count()['PassengerId'])
df
Out[168]:
PassengerId
Parch Survived
0 0 445
1 233
1 0 53
1 65
2 0 40
1 40
3 0 2
1 3
4 0 4
5 0 4
1 1
6 0 1
好吧,没看出特别特别明显的规律(为自己的智商感到捉急…),先作为备选特征,放一放。
看看船票好了
ticket是船票编号,应该是unique的,和最后的结果没有太大的关系,不纳入考虑的特征范畴
cabin只有204个乘客有值,我们先看看它的一个分布
In [191]:
#ticket是船票编号,应该是unique的,和最后的结果没有太大的关系,不纳入考虑的特征范畴
#cabin只有204个乘客有值,我们先看看它的一个分布
data_train.Cabin.value_counts()
Out[191]:
C23 C25 C27 4
G6 4
B96 B98 4
D 3
C22 C26 3
E101 3
F2 3
F33 3
B57 B59 B63 B66 2
C68 2
B58 B60 2
E121 2
D20 2
E8 2
E44 2
B77 2
C65 2
D26 2
E24 2
E25 2
B20 2
C93 2
D33 2
E67 2
D35 2
D36 2
C52 2
F4 2
C125 2
C124 2
..
F G63 1
A6 1
D45 1
D6 1
D56 1
C101 1
C54 1
D28 1
D37 1
B102 1
D30 1
E17 1
E58 1
F E69 1
D10 D12 1
E50 1
A14 1
C91 1
A16 1
B38 1
B39 1
C95 1
B78 1
B79 1
C99 1
B37 1
A19 1
E12 1
A7 1
D15 1
dtype: int64
这三三两两的…如此不集中…我们猜一下,也许,前面的ABCDE是指的甲板位置、然后编号是房间号?…好吧,我瞎说的,别当真…
关键是Cabin这鬼属性,应该算作类目型的,本来缺失值就多,还如此不集中,注定是个棘手货…第一感觉,这玩意儿如果直接按照类目特征处理的话,太散了,估计每个因子化后的特征都拿不到什么权重。加上有那么多缺失值,要不我们先把Cabin缺失与否作为条件(虽然这部分信息缺失可能并非未登记,maybe只是丢失了而已,所以这样做未必妥当),先在有无Cabin信息这个粗粒度上看看Survived的情况好了。
In [511]:
#cabin的值计数太分散了,绝大多数Cabin值只出现一次。感觉上作为类目,加入特征未必会有效
#那我们一起看看这个值的有无,对于survival的分布状况,影响如何吧
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose()
df.plot(kind='bar', stacked=True)
plt.title(u"按Cabin有无看获救情况")
plt.xlabel(u"Cabin有无")
plt.ylabel(u"人数")
plt.show()
#似乎有cabin记录的乘客survival比例稍高,那先试试把这个值分为两类,有cabin值/无cabin值,一会儿加到类别特征好了
有Cabin记录的似乎获救概率稍高一些,先这么着放一放吧。
先从最突出的数据属性开始吧,对,Cabin和Age,有丢失数据实在是对下一步工作影响太大。
先说Cabin,暂时我们就按照刚才说的,按Cabin有无数据,将这个属性处理成Yes和No两种类型吧。
再说Age:
通常遇到缺值的情况,我们会有几种常见的处理方式
如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
本例中,后两种处理方式应该都是可行的,我们先试试拟合补全吧(虽然说没有特别多的背景可供我们拟合,这不一定是一个多么好的选择)
我们这里用scikit-learn中的RandomForest来拟合一下缺失的年龄数据
In [564]:
from sklearn.ensemble import RandomForestRegressor
### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
data_train
Out[564]:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.000000 1 0 A/5 21171 7.2500 No S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.000000 1 0 PC 17599 71.2833 Yes C
2 3 1 3 Heikkinen, Miss. Laina female 26.000000 0 0 STON/O2. 3101282 7.9250 No S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.000000 1 0 113803 53.1000 Yes S
4 5 0 3 Allen, Mr. William Henry male 35.000000 0 0 373450 8.0500 No S
5 6 0 3 Moran, Mr. James male 23.828953 0 0 330877 8.4583 No Q
6 7 0 1 McCarthy, Mr. Timothy J male 54.000000 0 0 17463 51.8625 Yes S
7 8 0 3 Palsson, Master. Gosta Leonard male 2.000000 3 1 349909 21.0750 No S
8 9 1 3 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) female 27.000000 0 2 347742 11.1333 No S
9 10 1 2 Nasser, Mrs. Nicholas (Adele Achem) female 14.000000 1 0 237736 30.0708 No C
10 11 1 3 Sandstrom, Miss. Marguerite Rut female 4.000000 1 1 PP 9549 16.7000 Yes S
11 12 1 1 Bonnell, Miss. Elizabeth female 58.000000 0 0 113783 26.5500 Yes S
12 13 0 3 Saundercock, Mr. William Henry male 20.000000 0 0 A/5. 2151 8.0500 No S
13 14 0 3 Andersson, Mr. Anders Johan male 39.000000 1 5 347082 31.2750 No S
14 15 0 3 Vestrom, Miss. Hulda Amanda Adolfina female 14.000000 0 0 350406 7.8542 No S
15 16 1 2 Hewlett, Mrs. (Mary D Kingcome) female 55.000000 0 0 248706 16.0000 No S
16 17 0 3 Rice, Master. Eugene male 2.000000 4 1 382652 29.1250 No Q
17 18 1 2 Williams, Mr. Charles Eugene male 32.066493 0 0 244373 13.0000 No S
18 19 0 3 Vander Planke, Mrs. Julius (Emelia Maria Vande... female 31.000000 1 0 345763 18.0000 No S
19 20 1 3 Masselmani, Mrs. Fatima female 29.518205 0 0 2649 7.2250 No C
20 21 0 2 Fynney, Mr. Joseph J male 35.000000 0 0 239865 26.0000 No S
21 22 1 2 Beesley, Mr. Lawrence male 34.000000 0 0 248698 13.0000 Yes S
22 23 1 3 McGowan, Miss. Anna "Annie" female 15.000000 0 0 330923 8.0292 No Q
23 24 1 1 Sloper, Mr. William Thompson male 28.000000 0 0 113788 35.5000 Yes S
24 25 0 3 Palsson, Miss. Torborg Danira female 8.000000 3 1 349909 21.0750 No S
25 26 1 3 Asplund, Mrs. Carl Oscar (Selma Augusta Emilia... female 38.000000 1 5 347077 31.3875 No S
26 27 0 3 Emir, Mr. Farred Chehab male 29.518205 0 0 2631 7.2250 No C
27 28 0 1 Fortune, Mr. Charles Alexander male 19.000000 3 2 19950 263.0000 Yes S
28 29 1 3 O'Dwyer, Miss. Ellen "Nellie" female 22.380113 0 0 330959 7.8792 No Q
29 30 0 3 Todoroff, Mr. Lalio male 27.947206 0 0 349216 7.8958 No S
... ... ... ... ... ... ... ... ... ... ... ... ...
861 862 0 2 Giles, Mr. Frederick Edward male 21.000000 1 0 28134 11.5000 No S
862 863 1 1 Swift, Mrs. Frederick Joel (Margaret Welles Ba... female 48.000000 0 0 17466 25.9292 Yes S
863 864 0 3 Sage, Miss. Dorothy Edith "Dolly" female 10.888325 8 2 CA. 2343 69.5500 No S
864 865 0 2 Gill, Mr. John William male 24.000000 0 0 233866 13.0000 No S
865 866 1 2 Bystrom, Mrs. (Karolina) female 42.000000 0 0 236852 13.0000 No S
866 867 1 2 Duran y More, Miss. Asuncion female 27.000000 1 0 SC/PARIS 2149 13.8583 No C
867 868 0 1 Roebling, Mr. Washington Augustus II male 31.000000 0 0 PC 17590 50.4958 Yes S
868 869 0 3 van Melkebeke, Mr. Philemon male 25.977889 0 0 345777 9.5000 No S
869 870 1 3 Johnson, Master. Harold Theodor male 4.000000 1 1 347742 11.1333 No S
870 871 0 3 Balkic, Mr. Cerin male 26.000000 0 0 349248 7.8958 No S
871 872 1 1 Beckwith, Mrs. Richard Leonard (Sallie Monypeny) female 47.000000 1 1 11751 52.5542 Yes S
872 873 0 1 Carlsson, Mr. Frans Olof male 33.000000 0 0 695 5.0000 Yes S
873 874 0 3 Vander Cruyssen, Mr. Victor male 47.000000 0 0 345765 9.0000 No S
874 875 1 2 Abelson, Mrs. Samuel (Hannah Wizosky) female 28.000000 1 0 P/PP 3381 24.0000 No C
875 876 1 3 Najib, Miss. Adele Kiamie "Jane" female 15.000000 0 0 2667 7.2250 No C
876 877 0 3 Gustafsson, Mr. Alfred Ossian male 20.000000 0 0 7534 9.8458 No S
877 878 0 3 Petroff, Mr. Nedelio male 19.000000 0 0 349212 7.8958 No S
878 879 0 3 Laleff, Mr. Kristo male 27.947206 0 0 349217 7.8958 No S
879 880 1 1 Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) female 56.000000 0 1 11767 83.1583 Yes C
880 881 1 2 Shelley, Mrs. William (Imanita Parrish Hall) female 25.000000 0 1 230433 26.0000 No S
881 882 0 3 Markun, Mr. Johann male 33.000000 0 0 349257 7.8958 No S
882 883 0 3 Dahlberg, Miss. Gerda Ulrika female 22.000000 0 0 7552 10.5167 No S
883 884 0 2 Banfield, Mr. Frederick James male 28.000000 0 0 C.A./SOTON 34068 10.5000 No S
884 885 0 3 Sutehall, Mr. Henry Jr male 25.000000 0 0 SOTON/OQ 392076 7.0500 No S
885 886 0 3 Rice, Mrs. William (Margaret Norton) female 39.000000 0 5 382652 29.1250 No Q
886 887 0 2 Montvila, Rev. Juozas male 27.000000 0 0 211536 13.0000 No S
887 888 1 1 Graham, Miss. Margaret Edith female 19.000000 0 0 112053 30.0000 Yes S
888 889 0 3 Johnston, Miss. Catherine Helen "Carrie" female 16.232379 1 2 W./C. 6607 23.4500 No S
889 890 1 1 Behr, Mr. Karl Howell male 26.000000 0 0 111369 30.0000 Yes C
890 891 0 3 Dooley, Mr. Patrick male 32.000000 0 0 370376 7.7500 No Q
891 rows × 12 columns
因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化/one-hot编码。
什么叫做因子化/one-hot编码?举个例子:
以Embarked为例,原本一个属性维度,因为其取值可以是[‘S’,’C’,’Q‘],而将其平展开为’Embarked_C’,’Embarked_S’, ‘Embarked_Q’三个属性
原本Embarked取值为S的,在此处的”Embarked_S”下取值为1,在’Embarked_C’, ‘Embarked_Q’下取值为0
原本Embarked取值为C的,在此处的”Embarked_C”下取值为1,在’Embarked_S’, ‘Embarked_Q’下取值为0
原本Embarked取值为Q的,在此处的”Embarked_Q”下取值为1,在’Embarked_C’, ‘Embarked_S’下取值为0
我们使用pandas的”get_dummies”来完成这个工作,并拼接在原来的”data_train”之上,如下所示。
In [565]:
# 因为逻辑回归建模时,需要输入的特征都是数值型特征
# 我们先对类目型的特征离散/因子化
# 以Cabin为例,原本一个属性维度,因为其取值可以是['yes','no'],而将其平展开为'Cabin_yes','Cabin_no'两个属性
# 原本Cabin取值为yes的,在此处的'Cabin_yes'下取值为1,在'Cabin_no'下取值为0
# 原本Cabin取值为no的,在此处的'Cabin_yes'下取值为0,在'Cabin_no'下取值为1
# 我们使用pandas的get_dummies来完成这个工作,并拼接在原来的data_train之上,如下所示
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df
Out[565]:
PassengerId Survived Age SibSp Parch Fare Cabin_No Cabin_Yes Embarked_C Embarked_Q Embarked_S Sex_female Sex_male Pclass_1 Pclass_2 Pclass_3
0 1 0 22.000000 1 0 7.2500 1 0 0 0 1 0 1 0 0 1
1 2 1 38.000000 1 0 71.2833 0 1 1 0 0 1 0 1 0 0
2 3 1 26.000000 0 0 7.9250 1 0 0 0 1 1 0 0 0 1
3 4 1 35.000000 1 0 53.1000 0 1 0 0 1 1 0 1 0 0
4 5 0 35.000000 0 0 8.0500 1 0 0 0 1 0 1 0 0 1
5 6 0 23.828953 0 0 8.4583 1 0 0 1 0 0 1 0 0 1
6 7 0 54.000000 0 0 51.8625 0 1 0 0 1 0 1 1 0 0
7 8 0 2.000000 3 1 21.0750 1 0 0 0 1 0 1 0 0 1
8 9 1 27.000000 0 2 11.1333 1 0 0 0 1 1 0 0 0 1
9 10 1 14.000000 1 0 30.0708 1 0 1 0 0 1 0 0 1 0
10 11 1 4.000000 1 1 16.7000 0 1 0 0 1 1 0 0 0 1
11 12 1 58.000000 0 0 26.5500 0 1 0 0 1 1 0 1 0 0
12 13 0 20.000000 0 0 8.0500 1 0 0 0 1 0 1 0 0 1
13 14 0 39.000000 1 5 31.2750 1 0 0 0 1 0 1 0 0 1
14 15 0 14.000000 0 0 7.8542 1 0 0 0 1 1 0 0 0 1
15 16 1 55.000000 0 0 16.0000 1 0 0 0 1 1 0 0 1 0
16 17 0 2.000000 4 1 29.1250 1 0 0 1 0 0 1 0 0 1
17 18 1 32.066493 0 0 13.0000 1 0 0 0 1 0 1 0 1 0
18 19 0 31.000000 1 0 18.0000 1 0 0 0 1 1 0 0 0 1
19 20 1 29.518205 0 0 7.2250 1 0 1 0 0 1 0 0 0 1
20 21 0 35.000000 0 0 26.0000 1 0 0 0 1 0 1 0 1 0
21 22 1 34.000000 0 0 13.0000 0 1 0 0 1 0 1 0 1 0
22 23 1 15.000000 0 0 8.0292 1 0 0 1 0 1 0 0 0 1
23 24 1 28.000000 0 0 35.5000 0 1 0 0 1 0 1 1 0 0
24 25 0 8.000000 3 1 21.0750 1 0 0 0 1 1 0 0 0 1
25 26 1 38.000000 1 5 31.3875 1 0 0 0 1 1 0 0 0 1
26 27 0 29.518205 0 0 7.2250 1 0 1 0 0 0 1 0 0 1
27 28 0 19.000000 3 2 263.0000 0 1 0 0 1 0 1 1 0 0
28 29 1 22.380113 0 0 7.8792 1 0 0 1 0 1 0 0 0 1
29 30 0 27.947206 0 0 7.8958 1 0 0 0 1 0 1 0 0 1
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
861 862 0 21.000000 1 0 11.5000 1 0 0 0 1 0 1 0 1 0
862 863 1 48.000000 0 0 25.9292 0 1 0 0 1 1 0 1 0 0
863 864 0 10.888325 8 2 69.5500 1 0 0 0 1 1 0 0 0 1
864 865 0 24.000000 0 0 13.0000 1 0 0 0 1 0 1 0 1 0
865 866 1 42.000000 0 0 13.0000 1 0 0 0 1 1 0 0 1 0
866 867 1 27.000000 1 0 13.8583 1 0 1 0 0 1 0 0 1 0
867 868 0 31.000000 0 0 50.4958 0 1 0 0 1 0 1 1 0 0
868 869 0 25.977889 0 0 9.5000 1 0 0 0 1 0 1 0 0 1
869 870 1 4.000000 1 1 11.1333 1 0 0 0 1 0 1 0 0 1
870 871 0 26.000000 0 0 7.8958 1 0 0 0 1 0 1 0 0 1
871 872 1 47.000000 1 1 52.5542 0 1 0 0 1 1 0 1 0 0
872 873 0 33.000000 0 0 5.0000 0 1 0 0 1 0 1 1 0 0
873 874 0 47.000000 0 0 9.0000 1 0 0 0 1 0 1 0 0 1
874 875 1 28.000000 1 0 24.0000 1 0 1 0 0 1 0 0 1 0
875 876 1 15.000000 0 0 7.2250 1 0 1 0 0 1 0 0 0 1
876 877 0 20.000000 0 0 9.8458 1 0 0 0 1 0 1 0 0 1
877 878 0 19.000000 0 0 7.8958 1 0 0 0 1 0 1 0 0 1
878 879 0 27.947206 0 0 7.8958 1 0 0 0 1 0 1 0 0 1
879 880 1 56.000000 0 1 83.1583 0 1 1 0 0 1 0 1 0 0
880 881 1 25.000000 0 1 26.0000 1 0 0 0 1 1 0 0 1 0
881 882 0 33.000000 0 0 7.8958 1 0 0 0 1 0 1 0 0 1
882 883 0 22.000000 0 0 10.5167 1 0 0 0 1 1 0 0 0 1
883 884 0 28.000000 0 0 10.5000 1 0 0 0 1 0 1 0 1 0
884 885 0 25.000000 0 0 7.0500 1 0 0 0 1 0 1 0 0 1
885 886 0 39.000000 0 5 29.1250 1 0 0 1 0 1 0 0 0 1
886 887 0 27.000000 0 0 13.0000 1 0 0 0 1 0 1 0 1 0
887 888 1 19.000000 0 0 30.0000 0 1 0 0 1 1 0 1 0 0
888 889 0 16.232379 1 2 23.4500 1 0 0 0 1 1 0 0 0 1
889 890 1 26.000000 0 0 30.0000 0 1 1 0 0 0 1 1 0 0
890 891 0 32.000000 0 0 7.7500 1 0 0 1 0 0 1 0 0 1
891 rows × 16 columns
我们还得做一些处理,仔细看看Age和Fare两个属性,乘客的数值幅度变化,也忒大了吧!!如果大家了解逻辑回归与梯度下降的话,会知道,各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛! (╬▔皿▔)…所以我们先用scikit-learn里面的preprocessing模块对这俩货做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。
In [566]:
# 接下来我们要接着做一些数据预处理的工作,比如scaling,将一些变化幅度较大的特征化到[-1,1]之内
# 这样可以加速logistic regression的收敛
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df['Age'])
df['Age_scaled'] = scaler.fit_transform(df['Age'], age_scale_param)
fare_scale_param = scaler.fit(df['Fare'])
df['Fare_scaled'] = scaler.fit_transform(df['Fare'], fare_scale_param)
df
Out[566]:
PassengerId Survived Age SibSp Parch Fare Cabin_No Cabin_Yes Embarked_C Embarked_Q Embarked_S Sex_female Sex_male Pclass_1 Pclass_2 Pclass_3 Age_scaled Fare_scaled
0 1 0 22.000000 1 0 7.2500 1 0 0 0 1 0 1 0 0 1 -0.561417 -0.502445
1 2 1 38.000000 1 0 71.2833 0 1 1 0 0 1 0 1 0 0 0.613177 0.786845
2 3 1 26.000000 0 0 7.9250 1 0 0 0 1 1 0 0 0 1 -0.267768 -0.488854
3 4 1 35.000000 1 0 53.1000 0 1 0 0 1 1 0 1 0 0 0.392941 0.420730
4 5 0 35.000000 0 0 8.0500 1 0 0 0 1 0 1 0 0 1 0.392941 -0.486337
5 6 0 23.828953 0 0 8.4583 1 0 0 1 0 0 1 0 0 1 -0.427149 -0.478116
6 7 0 54.000000 0 0 51.8625 0 1 0 0 1 0 1 1 0 0 1.787771 0.395814
7 8 0 2.000000 3 1 21.0750 1 0 0 0 1 0 1 0 0 1 -2.029659 -0.224083
8 9 1 27.000000 0 2 11.1333 1 0 0 0 1 1 0 0 0 1 -0.194356 -0.424256
9 10 1 14.000000 1 0 30.0708 1 0 1 0 0 1 0 0 1 0 -1.148714 -0.042956
10 11 1 4.000000 1 1 16.7000 0 1 0 0 1 1 0 0 0 1 -1.882835 -0.312172
11 12 1 58.000000 0 0 26.5500 0 1 0 0 1 1 0 1 0 0 2.081420 -0.113846
12 13 0 20.000000 0 0 8.0500 1 0 0 0 1 0 1 0 0 1 -0.708241 -0.486337
13 14 0 39.000000 1 5 31.2750 1 0 0 0 1 0 1 0 0 1 0.686589 -0.018709
14 15 0 14.000000 0 0 7.8542 1 0 0 0 1 1 0 0 0 1 -1.148714 -0.490280
15 16 1 55.000000 0 0 16.0000 1 0 0 0 1 1 0 0 1 0 1.861183 -0.326267
16 17 0 2.000000 4 1 29.1250 1 0 0 1 0 0 1 0 0 1 -2.029659 -0.061999
17 18 1 32.066493 0 0 13.0000 1 0 0 0 1 0 1 0 1 0 0.177586 -0.386671
18 19 0 31.000000 1 0 18.0000 1 0 0 0 1 1 0 0 0 1 0.099292 -0.285997
19 20 1 29.518205 0 0 7.2250 1 0 1 0 0 1 0 0 0 1 -0.009489 -0.502949
20 21 0 35.000000 0 0 26.0000 1 0 0 0 1 0 1 0 1 0 0.392941 -0.124920
21 22 1 34.000000 0 0 13.0000 0 1 0 0 1 0 1 0 1 0 0.319529 -0.386671
22 23 1 15.000000 0 0 8.0292 1 0 0 1 0 1 0 0 0 1 -1.075302 -0.486756
23 24 1 28.000000 0 0 35.5000 0 1 0 0 1 0 1 1 0 0 -0.120944 0.066360
24 25 0 8.000000 3 1 21.0750 1 0 0 0 1 1 0 0 0 1 -1.589186 -0.224083
25 26 1 38.000000 1 5 31.3875 1 0 0 0 1 1 0 0 0 1 0.613177 -0.016444
26 27 0 29.518205 0 0 7.2250 1 0 1 0 0 0 1 0 0 1 -0.009489 -0.502949
27 28 0 19.000000 3 2 263.0000 0 1 0 0 1 0 1 1 0 0 -0.781653 4.647001
28 29 1 22.380113 0 0 7.8792 1 0 0 1 0 1 0 0 0 1 -0.533512 -0.489776
29 30 0 27.947206 0 0 7.8958 1 0 0 0 1 0 1 0 0 1 -0.124820 -0.489442
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
861 862 0 21.000000 1 0 11.5000 1 0 0 0 1 0 1 0 1 0 -0.634829 -0.416873
862 863 1 48.000000 0 0 25.9292 0 1 0 0 1 1 0 1 0 0 1.347299 -0.126345
863 864 0 10.888325 8 2 69.5500 1 0 0 0 1 1 0 0 0 1 -1.377148 0.751946
864 865 0 24.000000 0 0 13.0000 1 0 0 0 1 0 1 0 1 0 -0.414592 -0.386671
865 866 1 42.000000 0 0 13.0000 1 0 0 0 1 1 0 0 1 0 0.906826 -0.386671
866 867 1 27.000000 1 0 13.8583 1 0 1 0 0 1 0 0 1 0 -0.194356 -0.369389
867 868 0 31.000000 0 0 50.4958 0 1 0 0 1 0 1 1 0 0 0.099292 0.368295
868 869 0 25.977889 0 0 9.5000 1 0 0 0 1 0 1 0 0 1 -0.269391 -0.457142
869 870 1 4.000000 1 1 11.1333 1 0 0 0 1 0 1 0 0 1 -1.882835 -0.424256
870 871 0 26.000000 0 0 7.8958 1 0 0 0 1 0 1 0 0 1 -0.267768 -0.489442
871 872 1 47.000000 1 1 52.5542 0 1 0 0 1 1 0 1 0 0 1.273886 0.409741
872 873 0 33.000000 0 0 5.0000 0 1 0 0 1 0 1 1 0 0 0.246117 -0.547748
873 874 0 47.000000 0 0 9.0000 1 0 0 0 1 0 1 0 0 1 1.273886 -0.467209
874 875 1 28.000000 1 0 24.0000 1 0 1 0 0 1 0 0 1 0 -0.120944 -0.165189
875 876 1 15.000000 0 0 7.2250 1 0 1 0 0 1 0 0 0 1 -1.075302 -0.502949
876 877 0 20.000000 0 0 9.8458 1 0 0 0 1 0 1 0 0 1 -0.708241 -0.450180
877 878 0 19.000000 0 0 7.8958 1 0 0 0 1 0 1 0 0 1 -0.781653 -0.489442
878 879 0 27.947206 0 0 7.8958 1 0 0 0 1 0 1 0 0 1 -0.124820 -0.489442
879 880 1 56.000000 0 1 83.1583 0 1 1 0 0 1 0 1 0 0 1.934596 1.025945
880 881 1 25.000000 0 1 26.0000 1 0 0 0 1 1 0 0 1 0 -0.341180 -0.124920
881 882 0 33.000000 0 0 7.8958 1 0 0 0 1 0 1 0 0 1 0.246117 -0.489442
882 883 0 22.000000 0 0 10.5167 1 0 0 0 1 1 0 0 0 1 -0.561417 -0.436671
883 884 0 28.000000 0 0 10.5000 1 0 0 0 1 0 1 0 1 0 -0.120944 -0.437007
884 885 0 25.000000 0 0 7.0500 1 0 0 0 1 0 1 0 0 1 -0.341180 -0.506472
885 886 0 39.000000 0 5 29.1250 1 0 0 1 0 1 0 0 0 1 0.686589 -0.061999
886 887 0 27.000000 0 0 13.0000 1 0 0 0 1 0 1 0 1 0 -0.194356 -0.386671
887 888 1 19.000000 0 0 30.0000 0 1 0 0 1 1 0 1 0 0 -0.781653 -0.044381
888 889 0 16.232379 1 2 23.4500 1 0 0 0 1 1 0 0 0 1 -0.984830 -0.176263
889 890 1 26.000000 0 0 30.0000 0 1 1 0 0 0 1 1 0 0 -0.267768 -0.044381
890 891 0 32.000000 0 0 7.7500 1 0 0 1 0 0 1 0 0 1 0.172705 -0.492378
891 rows × 18 columns
我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模。
In [573]:
# 我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模
from sklearn import linear_model
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
clf
Out[573]:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr',
penalty='l1', random_state=None, solver='liblinear', tol=1e-06,
verbose=0)
In [574]:
X.shape
Out[574]:
(891, 14)
接下来咱们对训练集和测试集做一样的操作
In [569]:
data_test = pd.read_csv("test.csv")
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'], age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'], fare_scale_param)
df_test
Out[569]:
PassengerId Age SibSp Parch Fare Cabin_No Cabin_Yes Embarked_C Embarked_Q Embarked_S Sex_female Sex_male Pclass_1 Pclass_2 Pclass_3 Age_scaled Fare_scaled
0 892 34.500000 0 0 7.8292 1 0 0 1 0 0 1 0 0 1 0.307495 -0.496637
1 893 47.000000 1 0 7.0000 1 0 0 0 1 1 0 0 0 1 1.256225 -0.511497
2 894 62.000000 0 0 9.6875 1 0 0 1 0 0 1 0 1 0 2.394702 -0.463335
3 895 27.000000 0 0 8.6625 1 0 0 0 1 0 1 0 0 1 -0.261743 -0.481704
4 896 22.000000 1 1 12.2875 1 0 0 0 1 1 0 0 0 1 -0.641235 -0.416740
5 897 14.000000 0 0 9.2250 1 0 0 0 1 0 1 0 0 1 -1.248423 -0.471623
6 898 30.000000 0 0 7.6292 1 0 0 1 0 1 0 0 0 1 -0.034048 -0.500221
7 899 26.000000 1 1 29.0000 1 0 0 0 1 0 1 0 1 0 -0.337642 -0.117238
8 900 18.000000 0 0 7.2292 1 0 1 0 0 1 0 0 0 1 -0.944829 -0.507390
9 901 21.000000 2 0 24.1500 1 0 0 0 1 0 1 0 0 1 -0.717134 -0.204154
10 902 27.947206 0 0 7.8958 1 0 0 0 1 0 1 0 0 1 -0.189852 -0.495444
11 903 46.000000 0 0 26.0000 1 0 0 0 1 0 1 1 0 0 1.180327 -0.171000
12 904 23.000000 1 0 82.2667 0 1 0 0 1 1 0 1 0 0 -0.565337 0.837349
13 905 63.000000 1 0 26.0000 1 0 0 0 1 0 1 0 1 0 2.470600 -0.171000
14 906 47.000000 1 0 61.1750 0 1 0 0 1 1 0 1 0 0 1.256225 0.459367
15 907 24.000000 1 0 27.7208 1 0 1 0 0 1 0 0 1 0 -0.489439 -0.140162
16 908 35.000000 0 0 12.3500 1 0 0 1 0 0 1 0 1 0 0.345444 -0.415620
17 909 21.000000 0 0 7.2250 1 0 1 0 0 0 1 0 0 1 -0.717134 -0.507465
18 910 27.000000 1 0 7.9250 1 0 0 0 1 1 0 0 0 1 -0.261743 -0.494920
19 911 45.000000 0 0 7.2250 1 0 1 0 0 1 0 0 0 1 1.104428 -0.507465
20 912 55.000000 1 0 59.4000 1 0 1 0 0 0 1 1 0 0 1.863413 0.427557
21 913 9.000000 0 1 3.1708 1 0 0 0 1 0 1 0 0 1 -1.627915 -0.580120
22 914 52.314311 0 0 31.6833 1 0 0 0 1 1 0 1 0 0 1.659573 -0.069151
23 915 21.000000 0 1 61.3792 1 0 1 0 0 0 1 1 0 0 -0.717134 0.463026
24 916 48.000000 1 3 262.3750 0 1 1 0 0 1 0 1 0 0 1.332124 4.065049
25 917 50.000000 1 0 14.5000 1 0 0 0 1 0 1 0 0 1 1.483921 -0.377090
26 918 22.000000 0 1 61.9792 0 1 1 0 0 1 0 1 0 0 -0.641235 0.473779
27 919 22.500000 0 0 7.2250 1 0 1 0 0 0 1 0 0 1 -0.603286 -0.507465
28 920 41.000000 0 0 30.5000 0 1 0 0 1 0 1 1 0 0 0.800835 -0.090356
29 921 23.481602 2 0 21.6792 1 0 1 0 0 0 1 0 0 1 -0.528784 -0.248433
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
388 1280 21.000000 0 0 7.7500 1 0 0 1 0 0 1 0 0 1 -0.717134 -0.498056
389 1281 6.000000 3 1 21.0750 1 0 0 0 1 0 1 0 0 1 -1.855610 -0.259261
390 1282 23.000000 0 0 93.5000 0 1 0 0 1 0 1 1 0 0 -0.565337 1.038659
391 1283 51.000000 0 1 39.4000 0 1 0 0 1 1 0 1 0 0 1.559819 0.069140
392 1284 13.000000 0 2 20.2500 1 0 0 0 1 0 1 0 0 1 -1.324321 -0.274045
393 1285 47.000000 0 0 10.5000 1 0 0 0 1 0 1 0 1 0 1.256225 -0.448774
394 1286 29.000000 3 1 22.0250 1 0 0 0 1 0 1 0 0 1 -0.109946 -0.242236
395 1287 18.000000 1 0 60.0000 0 1 0 0 1 1 0 1 0 0 -0.944829 0.438310
396 1288 24.000000 0 0 7.2500 1 0 0 1 0 0 1 0 0 1 -0.489439 -0.507017
397 1289 48.000000 1 1 79.2000 0 1 1 0 0 1 0 1 0 0 1.332124 0.782391
398 1290 22.000000 0 0 7.7750 1 0 0 0 1 0 1 0 0 1 -0.641235 -0.497608
399 1291 31.000000 0 0 7.7333 1 0 0 1 0 0 1 0 0 1 0.041850 -0.498356
400 1292 30.000000 0 0 164.8667 0 1 0 0 1 1 0 1 0 0 -0.034048 2.317614
401 1293 38.000000 1 0 21.0000 1 0 0 0 1 0 1 0 1 0 0.573139 -0.260605
402 1294 22.000000 0 1 59.4000 1 0 1 0 0 1 0 1 0 0 -0.641235 0.427557
403 1295 17.000000 0 0 47.1000 1 0 0 0 1 0 1 1 0 0 -1.020728 0.207130
404 1296 43.000000 1 0 27.7208 0 1 1 0 0 0 1 1 0 0 0.952632 -0.140162
405 1297 20.000000 0 0 13.8625 0 1 1 0 0 0 1 0 1 0 -0.793032 -0.388515
406 1298 23.000000 1 0 10.5000 1 0 0 0 1 0 1 0 1 0 -0.565337 -0.448774
407 1299 50.000000 1 1 211.5000 0 1 1 0 0 0 1 1 0 0 1.483921 3.153324
408 1300 19.895581 0 0 7.7208 1 0 0 1 0 1 0 0 0 1 -0.800957 -0.498580
409 1301 3.000000 1 1 13.7750 1 0 0 0 1 1 0 0 0 1 -2.083305 -0.390083
410 1302 35.295824 0 0 7.7500 1 0 0 1 0 1 0 0 0 1 0.367897 -0.498056
411 1303 37.000000 1 0 90.0000 0 1 0 1 0 1 0 1 0 0 0.497241 0.975936
412 1304 28.000000 0 0 7.7750 1 0 0 0 1 1 0 0 0 1 -0.185845 -0.497608
413 1305 30.705727 0 0 8.0500 1 0 0 0 1 0 1 0 0 1 0.019516 -0.492680
414 1306 39.000000 0 0 108.9000 0 1 1 0 0 1 0 1 0 0 0.649038 1.314641
415 1307 38.500000 0 0 7.2500 1 0 0 0 1 0 1 0 0 1 0.611089 -0.507017
416 1308 30.705727 0 0 8.0500 1 0 0 0 1 0 1 0 0 1 0.019516 -0.492680
417 1309 25.729701 1 1 22.3583 1 0 1 0 0 0 1 0 0 1 -0.358157 -0.236263
418 rows × 17 columns
In [371]:
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_predictions.csv", index=False)
In [515]:
pd.read_csv("logistic_regression_predictions.csv")
Out[515]:
PassengerId Survived
0 892 0
1 893 0
2 894 0
3 895 0
4 896 1
5 897 0
6 898 1
7 899 0
8 900 1
9 901 0
10 902 0
11 903 0
12 904 1
13 905 0
14 906 1
15 907 1
16 908 0
17 909 0
18 910 1
19 911 1
20 912 0
21 913 0
22 914 1
23 915 0
24 916 1
25 917 0
26 918 1
27 919 0
28 920 0
29 921 0
... ... ...
388 1280 0
389 1281 0
390 1282 1
391 1283 1
392 1284 0
393 1285 0
394 1286 0
395 1287 1
396 1288 0
397 1289 1
398 1290 0
399 1291 0
400 1292 1
401 1293 0
402 1294 1
403 1295 0
404 1296 0
405 1297 1
406 1298 0
407 1299 0
408 1300 1
409 1301 1
410 1302 1
411 1303 1
412 1304 1
413 1305 0
414 1306 1
415 1307 0
416 1308 0
417 1309 0
418 rows × 2 columns
0.76555,恩,结果还不错。毕竟,这只是我们简单分析过后出的一个baseline系统嘛
要判定一下当前模型所处状态(欠拟合or过拟合)
有一个很可能发生的问题是,我们不断地做feature engineering,产生的特征越来越多,用这些特征去训练模型,会对我们的训练集拟合得越来越好,同时也可能在逐步丧失泛化能力,从而在待预测的数据上,表现不佳,也就是发生过拟合问题。
从另一个角度上说,如果模型在待预测的数据上表现不佳,除掉上面说的过拟合问题,也有可能是欠拟合问题,也就是说在训练集上,其实拟合的也不是那么好。
额,这个欠拟合和过拟合怎么解释呢。这么说吧:
过拟合就像是你班那个学数学比较刻板的同学,老师讲过的题目,一字不漏全记下来了,于是老师再出一样的题目,分分钟精确出结果。but数学考试,因为总是碰到新题目,所以成绩不咋地。
欠拟合就像是,咳咳,和博主level差不多的差生。连老师讲的练习题也记不住,于是连老师出一样题目复习的周测都做不好,考试更是可想而知了。
而在机器学习的问题上,对于过拟合和欠拟合两种情形。我们优化的方式是不同的。
对过拟合而言,通常以下策略对结果优化是有用的:
做一下feature selection,挑出较好的feature的subset来做training
提供更多的数据,从而弥补原始数据的bias问题,学习到的model也会更准确
而对于欠拟合而言,我们通常需要更多的feature,更复杂的模型来提高准确度。
著名的learning curve可以帮我们判定我们的模型现在所处的状态。我们以样本数为横坐标,训练和交叉验证集上的错误率作为纵坐标,两种状态分别如下两张图所示:过拟合(overfitting/high variace),欠拟合(underfitting/high bias)
著名的learning curve可以帮我们判定我们的模型现在所处的状态。我们以样本数为横坐标,训练和交叉验证集上的错误率作为纵坐标,两种状态分别如下两张图所示:过拟合(overfitting/high variace),欠拟合(underfitting/high bias)
我们也可以把错误率替换成准确率(得分),得到另一种形式的learning curve(sklearn 里面是这么做的)。
回到我们的问题,我们用scikit-learn里面的learning_curve来帮我们分辨我们模型的状态。举个例子,这里我们一起画一下我们最先得到的baseline model的learning curve。
In [579]:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.gca().invert_yaxis()
plt.show()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
plot_learning_curve(clf, u"学习曲线", X, y)
/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/sklearn/cross_validation.py:1601: DeprecationWarning: check_cv will return indices instead of boolean masks from 0.17
def _score(estimator, X_test, y_test, scorer):
/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/sklearn/cross_validation.py:69: DeprecationWarning: The indices parameter is deprecated and will be removed (assumed True) in 0.17
def __iter__(self):
Out[579]:
(0.80656968448540245, 0.018258876711338634)
在实际数据上看,我们得到的learning curve没有理论推导的那么光滑哈,但是可以大致看出来,训练集和交叉验证集上的得分曲线走势还是符合预期的。
目前的曲线看来,我们的model并不处于overfitting的状态(overfitting的表现一般是训练集上得分高,而交叉验证集上要低很多,中间的gap比较大)。因此我们可以再做些feature engineering的工作,添加一些新产出的特征或者组合特征到模型中。
接下来,我们就该看看如何优化baseline系统了
我们还有些特征可以再挖掘挖掘
1. 比如说Name和Ticket两个属性被我们完整舍弃了(好吧,其实是一开始我们对于这种,每一条记录都是一个完全不同的值的属性,并没有很直接的处理方式)
2. 比如说,我们想想,年龄的拟合本身也未必是一件非常靠谱的事情
3. 另外,以我们的日常经验,小盆友和老人可能得到的照顾会多一些,这样看的话,年龄作为一个连续值,给一个固定的系数,似乎体现不出两头受照顾的实际情况,所以,说不定我们把年龄离散化,按区段分作类别属性会更合适一些
那怎么样才知道,哪些地方可以优化,哪些优化的方法是promising的呢?
是的
要做交叉验证(cross validation)!
要做交叉验证(cross validation)!
要做交叉验证(cross validation)!
重要的事情说3编!!!
因为test.csv里面并没有Survived这个字段(好吧,这是废话,这明明就是我们要预测的结果),我们无法在这份数据上评定我们算法在该场景下的效果。。。
我们通常情况下,这么做cross validation:把train.csv分成两部分,一部分用于训练我们需要的模型,另外一部分数据上看我们预测算法的效果。
我们可以用scikit-learn的cross_validation来完成这个工作
在此之前,咱们可以看看现在得到的模型的系数,因为系数和它们最终的判定能力强弱是正相关的
In [493]:
pd.DataFrame({"columns":list(train_df.columns)[1:], "coef":list(clf.coef_.T)})
Out[493]:
coef columns
0 [-0.344189431858] SibSp
1 [-0.104924350555] Parch
2 [0.0] Cabin_No
3 [0.902071479485] Cabin_Yes
4 [0.0] Embarked_C
5 [0.0] Embarked_Q
6 [-0.417226462259] Embarked_S
7 [1.95649520339] Sex_female
8 [-0.677484871046] Sex_male
9 [0.341226064445] Pclass_1
10 [0.0] Pclass_2
11 [-1.19410912948] Pclass_3
12 [-0.523774279397] Age_scaled
13 [0.0844279740271] Fare_scaled
上面的系数和最后的结果是一个正相关的关系
我们先看看那些权重绝对值非常大的feature,在我们的模型上:
Sex属性,如果是female会极大提高最后获救的概率,而male会很大程度拉低这个概率。
Pclass属性,1等舱乘客最后获救的概率会上升,而乘客等级为3会极大地拉低这个概率。
有Cabin值会很大程度拉升最后获救概率(这里似乎能看到了一点端倪,事实上从最上面的有无Cabin记录的Survived分布图上看出,即使有Cabin记录的乘客也有一部分遇难了,估计这个属性上我们挖掘还不够)
Age是一个负相关,意味着在我们的模型里,年龄越小,越有获救的优先权(还得回原数据看看这个是否合理)
有一个登船港口S会很大程度拉低获救的概率,另外俩港口压根就没啥作用(这个实际上非常奇怪,因为我们从之前的统计图上并没有看到S港口的获救率非常低,所以也许可以考虑把登船港口这个feature去掉试试)。
船票Fare有小幅度的正相关(并不意味着这个feature作用不大,有可能是我们细化的程度还不够,举个例子,说不定我们得对它离散化,再分至各个乘客等级上?)
噢啦,观察完了,我们现在有一些想法了,但是怎么样才知道,哪些优化的方法是promising的呢?
恩,要靠交叉验证
In [560]:
from sklearn import cross_validation
# 简单看看打分情况
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
all_data = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
X = all_data.as_matrix()[:,1:]
y = all_data.as_matrix()[:,0]
print cross_validation.cross_val_score(clf, X, y, cv=5)
# 分割数据
split_train, split_cv = cross_validation.train_test_split(
df, test_size=0.3, random_state=0)
train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
# 生成模型
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(train_df.as_matrix()[:,1:], train_df.as_matrix()[:,0])
# 对cross validation数据进行预测
cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(cv_df.as_matrix()[:,1:])
split_cv[ predictions != cv_df.as_matrix()[:,0] ].drop()
[ 0.81564246 0.81005587 0.78651685 0.78651685 0.81355932]
Out[560]:
PassengerId Survived Age SibSp Parch Fare Cabin_No Cabin_Yes Embarked_C Embarked_Q Embarked_S Sex_female Sex_male Pclass_1 Pclass_2 Pclass_3 Age_scaled Fare_scaled
298 299 1 41.574877 0 0 30.5000 0 1 0 0 1 0 1 1 0 0 0.875617 -0.034314
14 15 0 14.000000 0 0 7.8542 1 0 0 0 1 1 0 0 0 1 -1.148714 -0.490280
803 804 1 0.420000 0 1 8.5167 1 0 1 0 0 0 1 0 0 1 -2.145650 -0.476941
474 475 0 22.000000 0 0 9.8375 1 0 0 0 1 1 0 0 0 1 -0.561417 -0.450347
642 643 0 2.000000 3 2 27.9000 1 0 0 0 1 1 0 0 0 1 -2.029659 -0.086664
55 56 1 44.064830 0 0 35.5000 0 1 0 0 1 0 1 1 0 0 1.058409 0.066360
587 588 1 60.000000 1 1 79.2000 0 1 1 0 0 0 1 1 0 0 2.228244 0.946246
740 741 1 38.426632 0 0 30.0000 0 1 0 0 1 0 1 1 0 0 0.644497 -0.044381
839 840 1 50.903700 0 0 29.7000 0 1 1 0 0 0 1 1 0 0 1.560465 -0.050421
301 302 1 23.332602 2 0 23.2500 1 0 0 1 0 0 1 0 0 1 -0.463588 -0.180290
567 568 0 29.000000 0 4 21.0750 1 0 0 0 1 1 0 0 0 1 -0.047532 -0.224083
712 713 1 48.000000 1 0 52.0000 0 1 0 0 1 0 1 1 0 0 1.347299 0.398582
489 490 1 9.000000 1 1 15.9000 1 0 0 0 1 0 1 0 0 1 -1.515774 -0.328280
312 313 0 26.000000 1 1 26.0000 1 0 0 0 1 1 0 0 1 0 -0.267768 -0.124920
483 484 1 63.000000 0 0 9.5875 1 0 0 0 1 1 0 0 0 1 2.448480 -0.455380
505 506 0 18.000000 1 0 108.9000 0 1 1 0 0 0 1 1 0 0 -0.855065 1.544246
251 252 0 29.000000 1 1 10.4625 0 1 0 0 1 1 0 0 0 1 -0.047532 -0.437762
279 280 1 35.000000 1 1 20.2500 1 0 0 0 1 1 0 0 0 1 0.392941 -0.240694
838 839 1 32.000000 0 0 56.4958 1 0 0 0 1 0 1 0 0 1 0.172705 0.489104
564 565 0 30.705727 0 0 8.0500 1 0 0 0 1 1 0 0 0 1 0.077689 -0.486337
390 391 1 36.000000 1 2 120.0000 0 1 0 0 1 0 1 1 0 0 0.466353 1.767741
643 644 1 29.568898 0 0 56.4958 1 0 0 0 1 0 1 0 0 1 -0.005768 0.489104
267 268 1 25.000000 1 0 7.7750 1 0 0 0 1 0 1 0 0 1 -0.341180 -0.491874
501 502 0 21.000000 0 0 7.7500 1 0 0 1 0 1 0 0 0 1 -0.634829 -0.492378
113 114 0 20.000000 1 0 9.8250 1 0 0 0 1 1 0 0 0 1 -0.708241 -0.450598
654 655 0 18.000000 0 0 6.7500 1 0 0 1 0 1 0 0 0 1 -0.855065 -0.512513
293 294 0 24.000000 0 0 8.8500 1 0 0 0 1 1 0 0 0 1 -0.414592 -0.470230
503 504 0 37.000000 0 0 9.5875 1 0 0 0 1 1 0 0 0 1 0.539765 -0.455380
362 363 0 45.000000 0 1 14.4542 1 0 1 0 0 1 0 0 0 1 1.127062 -0.357391
570 571 1 62.000000 0 0 10.5000 1 0 0 0 1 0 1 0 1 0 2.375068 -0.437007
264 265 0 35.295824 0 0 7.7500 1 0 0 1 0 1 0 0 0 1 0.414658 -0.492378
762 763 1 20.000000 0 0 7.2292 1 0 1 0 0 0 1 0 0 1 -0.708241 -0.502864
85 86 1 33.000000 3 0 15.8500 1 0 0 0 1 1 0 0 0 1 0.246117 -0.329287
140 141 0 25.352908 0 2 15.2458 1 0 1 0 0 1 0 0 0 1 -0.315273 -0.341452
402 403 0 21.000000 1 0 9.8250 1 0 0 0 1 1 0 0 0 1 -0.634829 -0.450598
447 448 1 34.000000 0 0 26.5500 1 0 0 0 1 0 1 1 0 0 0.319529 -0.113846
204 205 1 18.000000 0 0 8.0500 1 0 0 0 1 0 1 0 0 1 -0.855065 -0.486337
240 241 0 20.800154 1 0 14.4542 1 0 1 0 0 1 0 0 0 1 -0.649500 -0.357391
283 284 1 19.000000 0 0 8.0500 1 0 0 0 1 0 1 0 0 1 -0.781653 -0.486337
647 648 1 56.000000 0 0 35.5000 0 1 1 0 0 0 1 1 0 0 1.934596 0.066360
852 853 0 9.000000 1 1 15.2458 1 0 1 0 0 1 0 0 0 1 -1.515774 -0.341452
788 789 1 1.000000 1 2 20.5750 1 0 0 0 1 0 1 0 0 1 -2.103071 -0.234150
68 69 1 17.000000 4 2 7.9250 1 0 0 0 1 1 0 0 0 1 -0.928477 -0.488854
271 272 1 25.000000 0 0 0.0000 1 0 0 0 1 0 1 0 0 1 -0.341180 -0.648422
882 883 0 22.000000 0 0 10.5167 1 0 0 0 1 1 0 0 0 1 -0.561417 -0.436671
65 66 1 17.107664 1 1 15.2458 1 0 1 0 0 0 1 0 0 1 -0.920573 -0.341452
680 681 0 23.476432 0 0 8.1375 1 0 0 1 0 1 0 0 0 1 -0.453029 -0.484576
49 50 0 18.000000 1 0 17.8000 1 0 0 0 1 1 0 0 0 1 -0.855065 -0.290024
338 339 1 45.000000 0 0 8.0500 1 0 0 0 1 0 1 0 0 1 1.127062 -0.486337
261 262 1 3.000000 4 2 31.3875 1 0 0 0 1 0 1 0 0 1 -1.956247 -0.016444
In [562]:
# 去除预测错误的case看原始dataframe数据
#split_cv['PredictResult'] = predictions
origin_data_train = pd.read_csv("Train.csv")
bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.as_matrix()[:,0]]['PassengerId'].values)]
bad_cases
Out[562]:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
14 15 0 3 Vestrom, Miss. Hulda Amanda Adolfina female 14.00 0 0 350406 7.8542 NaN S
49 50 0 3 Arnold-Franchi, Mrs. Josef (Josefine Franchi) female 18.00 1 0 349237 17.8000 NaN S
55 56 1 1 Woolner, Mr. Hugh male NaN 0 0 19947 35.5000 C52 S
65 66 1 3 Moubarek, Master. Gerios male NaN 1 1 2661 15.2458 NaN C
68 69 1 3 Andersson, Miss. Erna Alexandra female 17.00 4 2 3101281 7.9250 NaN S
85 86 1 3 Backstrom, Mrs. Karl Alfred (Maria Mathilda Gu... female 33.00 3 0 3101278 15.8500 NaN S
113 114 0 3 Jussila, Miss. Katriina female 20.00 1 0 4136 9.8250 NaN S
140 141 0 3 Boulos, Mrs. Joseph (Sultana) female NaN 0 2 2678 15.2458 NaN C
204 205 1 3 Cohen, Mr. Gurshon "Gus" male 18.00 0 0 A/5 3540 8.0500 NaN S
240 241 0 3 Zabour, Miss. Thamine female NaN 1 0 2665 14.4542 NaN C
251 252 0 3 Strom, Mrs. Wilhelm (Elna Matilda Persson) female 29.00 1 1 347054 10.4625 G6 S
261 262 1 3 Asplund, Master. Edvin Rojj Felix male 3.00 4 2 347077 31.3875 NaN S
264 265 0 3 Henry, Miss. Delia female NaN 0 0 382649 7.7500 NaN Q
267 268 1 3 Persson, Mr. Ernst Ulrik male 25.00 1 0 347083 7.7750 NaN S
271 272 1 3 Tornquist, Mr. William Henry male 25.00 0 0 LINE 0.0000 NaN S
279 280 1 3 Abbott, Mrs. Stanton (Rosa Hunt) female 35.00 1 1 C.A. 2673 20.2500 NaN S
283 284 1 3 Dorking, Mr. Edward Arthur male 19.00 0 0 A/5. 10482 8.0500 NaN S
293 294 0 3 Haas, Miss. Aloisia female 24.00 0 0 349236 8.8500 NaN S
298 299 1 1 Saalfeld, Mr. Adolphe male NaN 0 0 19988 30.5000 C106 S
301 302 1 3 McCoy, Mr. Bernard male NaN 2 0 367226 23.2500 NaN Q
312 313 0 2 Lahtinen, Mrs. William (Anna Sylfven) female 26.00 1 1 250651 26.0000 NaN S
338 339 1 3 Dahl, Mr. Karl Edwart male 45.00 0 0 7598 8.0500 NaN S
362 363 0 3 Barbara, Mrs. (Catherine David) female 45.00 0 1 2691 14.4542 NaN C
390 391 1 1 Carter, Mr. William Ernest male 36.00 1 2 113760 120.0000 B96 B98 S
402 403 0 3 Jussila, Miss. Mari Aina female 21.00 1 0 4137 9.8250 NaN S
447 448 1 1 Seward, Mr. Frederic Kimber male 34.00 0 0 113794 26.5500 NaN S
474 475 0 3 Strandberg, Miss. Ida Sofia female 22.00 0 0 7553 9.8375 NaN S
483 484 1 3 Turkula, Mrs. (Hedwig) female 63.00 0 0 4134 9.5875 NaN S
489 490 1 3 Coutts, Master. Eden Leslie "Neville" male 9.00 1 1 C.A. 37671 15.9000 NaN S
501 502 0 3 Canavan, Miss. Mary female 21.00 0 0 364846 7.7500 NaN Q
503 504 0 3 Laitinen, Miss. Kristina Sofia female 37.00 0 0 4135 9.5875 NaN S
505 506 0 1 Penasco y Castellana, Mr. Victor de Satode male 18.00 1 0 PC 17758 108.9000 C65 C
564 565 0 3 Meanwell, Miss. (Marion Ogden) female NaN 0 0 SOTON/O.Q. 392087 8.0500 NaN S
567 568 0 3 Palsson, Mrs. Nils (Alma Cornelia Berglund) female 29.00 0 4 349909 21.0750 NaN S
570 571 1 2 Harris, Mr. George male 62.00 0 0 S.W./PP 752 10.5000 NaN S
587 588 1 1 Frolicher-Stehli, Mr. Maxmillian male 60.00 1 1 13567 79.2000 B41 C
642 643 0 3 Skoog, Miss. Margit Elizabeth female 2.00 3 2 347088 27.9000 NaN S
643 644 1 3 Foo, Mr. Choong male NaN 0 0 1601 56.4958 NaN S
647 648 1 1 Simonius-Blumer, Col. Oberst Alfons male 56.00 0 0 13213 35.5000 A26 C
654 655 0 3 Hegarty, Miss. Hanora "Nora" female 18.00 0 0 365226 6.7500 NaN Q
680 681 0 3 Peters, Miss. Katie female NaN 0 0 330935 8.1375 NaN Q
712 713 1 1 Taylor, Mr. Elmer Zebley male 48.00 1 0 19996 52.0000 C126 S
740 741 1 1 Hawksford, Mr. Walter James male NaN 0 0 16988 30.0000 D45 S
762 763 1 3 Barah, Mr. Hanna Assi male 20.00 0 0 2663 7.2292 NaN C
788 789 1 3 Dean, Master. Bertram Vere male 1.00 1 2 C.A. 2315 20.5750 NaN S
803 804 1 3 Thomas, Master. Assad Alexander male 0.42 0 1 2625 8.5167 NaN C
838 839 1 3 Chip, Mr. Chang male 32.00 0 0 1601 56.4958 NaN S
839 840 1 1 Marechal, Mr. Pierre male NaN 0 0 11774 29.7000 C47 C
852 853 0 3 Boulos, Miss. Nourelain female 9.00 1 1 2678 15.2458 NaN C
882 883 0 3 Dahlberg, Miss. Gerda Ulrika female 22.00 0 0 7552 10.5167 NaN S
对比bad case,我们仔细看看我们预测错的样本,到底是哪些特征有问题,咱们处理得还不够细?
我们随便列一些可能可以做的优化操作:
Age属性不使用现在的拟合方式,而是根据名称中的『Mr』『Mrs』『Miss』等的平均值进行填充。
Age不做成一个连续值属性,而是使用一个步长进行离散化,变成离散的类目feature。
Cabin再细化一些,对于有记录的Cabin属性,我们将其分为前面的字母部分(我猜是位置和船层之类的信息) 和 后面的数字部分(应该是房间号,有意思的事情是,如果你仔细看看原始数据,你会发现,这个值大的情况下,似乎获救的可能性高一些)。
Pclass和Sex俩太重要了,我们试着用它们去组出一个组合属性来试试,这也是另外一种程度的细化。
单加一个Child字段,Age<=12的,设为1,其余为0(你去看看数据,确实小盆友优先程度很高啊)
如果名字里面有『Mrs』,而Parch>1的,我们猜测她可能是一个母亲,应该获救的概率也会提高,因此可以多加一个Mother字段,此种情况下设为1,其余情况下设为0
登船港口可以考虑先去掉试试(Q和C本来就没权重,S有点诡异)
把堂兄弟/兄妹 和 Parch 还有自己 个数加在一起组一个Family_size字段(考虑到大家族可能对最后的结果有影响)
Name是一个我们一直没有触碰的属性,我们可以做一些简单的处理,比如说男性中带某些字眼的(‘Capt’, ‘Don’, ‘Major’, ‘Sir’)可以统一到一个Title,女性也一样。
大家接着往下挖掘,可能还可以想到更多可以细挖的部分。我这里先列这些了,然后我们可以使用手头上的”train_df”和”cv_df”开始试验这些feature engineering的tricks是否有效了。
In [440]:
data_train[data_train['Name'].str.contains("Major")]
Out[440]:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
449 450 1 1 Peuchen, Major. Arthur Godfrey male 52 0 0 113786 30.50 Yes S
536 537 0 1 Butt, Major. Archibald Willingham male 45 0 0 113050 26.55 Yes S
In [ ]:
In [546]:
data_train = pd.read_csv("Train.csv")
data_train['Sex_Pclass'] = data_train.Sex + "_" + data_train.Pclass.map(str)
from sklearn.ensemble import RandomForestRegressor
### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
dummies_Sex_Pclass = pd.get_dummies(data_train['Sex_Pclass'], prefix= 'Sex_Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass, dummies_Sex_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked', 'Sex_Pclass'], axis=1, inplace=True)
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df['Age'])
df['Age_scaled'] = scaler.fit_transform(df['Age'], age_scale_param)
fare_scale_param = scaler.fit(df['Fare'])
df['Fare_scaled'] = scaler.fit_transform(df['Fare'], fare_scale_param)
from sklearn import linear_model
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
clf
Out[546]:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr',
penalty='l1', random_state=None, solver='liblinear', tol=1e-06,
verbose=0)
In [543]:
data_test = pd.read_csv("test.csv")
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
data_test['Sex_Pclass'] = data_test.Sex + "_" + data_test.Pclass.map(str)
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
dummies_Sex_Pclass = pd.get_dummies(data_test['Sex_Pclass'], prefix= 'Sex_Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass, dummies_Sex_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked', 'Sex_Pclass'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'], age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'], fare_scale_param)
df_test
Out[543]:
PassengerId Age SibSp Parch Fare Cabin_No Cabin_Yes Embarked_C Embarked_Q Embarked_S ... Pclass_2 Pclass_3 Sex_Pclass_female_1 Sex_Pclass_female_2 Sex_Pclass_female_3 Sex_Pclass_male_1 Sex_Pclass_male_2 Sex_Pclass_male_3 Age_scaled Fare_scaled
0 892 34.500000 0 0 7.8292 1 0 0 1 0 ... 0 1 0 0 0 0 0 1 0.307495 -0.496637
1 893 47.000000 1 0 7.0000 1 0 0 0 1 ... 0 1 0 0 1 0 0 0 1.256225 -0.511497
2 894 62.000000 0 0 9.6875 1 0 0 1 0 ... 1 0 0 0 0 0 1 0 2.394702 -0.463335
3 895 27.000000 0 0 8.6625 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -0.261743 -0.481704
4 896 22.000000 1 1 12.2875 1 0 0 0 1 ... 0 1 0 0 1 0 0 0 -0.641235 -0.416740
5 897 14.000000 0 0 9.2250 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -1.248423 -0.471623
6 898 30.000000 0 0 7.6292 1 0 0 1 0 ... 0 1 0 0 1 0 0 0 -0.034048 -0.500221
7 899 26.000000 1 1 29.0000 1 0 0 0 1 ... 1 0 0 0 0 0 1 0 -0.337642 -0.117238
8 900 18.000000 0 0 7.2292 1 0 1 0 0 ... 0 1 0 0 1 0 0 0 -0.944829 -0.507390
9 901 21.000000 2 0 24.1500 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -0.717134 -0.204154
10 902 27.947206 0 0 7.8958 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -0.189852 -0.495444
11 903 46.000000 0 0 26.0000 1 0 0 0 1 ... 0 0 0 0 0 1 0 0 1.180327 -0.171000
12 904 23.000000 1 0 82.2667 0 1 0 0 1 ... 0 0 1 0 0 0 0 0 -0.565337 0.837349
13 905 63.000000 1 0 26.0000 1 0 0 0 1 ... 1 0 0 0 0 0 1 0 2.470600 -0.171000
14 906 47.000000 1 0 61.1750 0 1 0 0 1 ... 0 0 1 0 0 0 0 0 1.256225 0.459367
15 907 24.000000 1 0 27.7208 1 0 1 0 0 ... 1 0 0 1 0 0 0 0 -0.489439 -0.140162
16 908 35.000000 0 0 12.3500 1 0 0 1 0 ... 1 0 0 0 0 0 1 0 0.345444 -0.415620
17 909 21.000000 0 0 7.2250 1 0 1 0 0 ... 0 1 0 0 0 0 0 1 -0.717134 -0.507465
18 910 27.000000 1 0 7.9250 1 0 0 0 1 ... 0 1 0 0 1 0 0 0 -0.261743 -0.494920
19 911 45.000000 0 0 7.2250 1 0 1 0 0 ... 0 1 0 0 1 0 0 0 1.104428 -0.507465
20 912 55.000000 1 0 59.4000 1 0 1 0 0 ... 0 0 0 0 0 1 0 0 1.863413 0.427557
21 913 9.000000 0 1 3.1708 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -1.627915 -0.580120
22 914 52.314311 0 0 31.6833 1 0 0 0 1 ... 0 0 1 0 0 0 0 0 1.659573 -0.069151
23 915 21.000000 0 1 61.3792 1 0 1 0 0 ... 0 0 0 0 0 1 0 0 -0.717134 0.463026
24 916 48.000000 1 3 262.3750 0 1 1 0 0 ... 0 0 1 0 0 0 0 0 1.332124 4.065049
25 917 50.000000 1 0 14.5000 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 1.483921 -0.377090
26 918 22.000000 0 1 61.9792 0 1 1 0 0 ... 0 0 1 0 0 0 0 0 -0.641235 0.473779
27 919 22.500000 0 0 7.2250 1 0 1 0 0 ... 0 1 0 0 0 0 0 1 -0.603286 -0.507465
28 920 41.000000 0 0 30.5000 0 1 0 0 1 ... 0 0 0 0 0 1 0 0 0.800835 -0.090356
29 921 23.481602 2 0 21.6792 1 0 1 0 0 ... 0 1 0 0 0 0 0 1 -0.528784 -0.248433
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
388 1280 21.000000 0 0 7.7500 1 0 0 1 0 ... 0 1 0 0 0 0 0 1 -0.717134 -0.498056
389 1281 6.000000 3 1 21.0750 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -1.855610 -0.259261
390 1282 23.000000 0 0 93.5000 0 1 0 0 1 ... 0 0 0 0 0 1 0 0 -0.565337 1.038659
391 1283 51.000000 0 1 39.4000 0 1 0 0 1 ... 0 0 1 0 0 0 0 0 1.559819 0.069140
392 1284 13.000000 0 2 20.2500 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -1.324321 -0.274045
393 1285 47.000000 0 0 10.5000 1 0 0 0 1 ... 1 0 0 0 0 0 1 0 1.256225 -0.448774
394 1286 29.000000 3 1 22.0250 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -0.109946 -0.242236
395 1287 18.000000 1 0 60.0000 0 1 0 0 1 ... 0 0 1 0 0 0 0 0 -0.944829 0.438310
396 1288 24.000000 0 0 7.2500 1 0 0 1 0 ... 0 1 0 0 0 0 0 1 -0.489439 -0.507017
397 1289 48.000000 1 1 79.2000 0 1 1 0 0 ... 0 0 1 0 0 0 0 0 1.332124 0.782391
398 1290 22.000000 0 0 7.7750 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 -0.641235 -0.497608
399 1291 31.000000 0 0 7.7333 1 0 0 1 0 ... 0 1 0 0 0 0 0 1 0.041850 -0.498356
400 1292 30.000000 0 0 164.8667 0 1 0 0 1 ... 0 0 1 0 0 0 0 0 -0.034048 2.317614
401 1293 38.000000 1 0 21.0000 1 0 0 0 1 ... 1 0 0 0 0 0 1 0 0.573139 -0.260605
402 1294 22.000000 0 1 59.4000 1 0 1 0 0 ... 0 0 1 0 0 0 0 0 -0.641235 0.427557
403 1295 17.000000 0 0 47.1000 1 0 0 0 1 ... 0 0 0 0 0 1 0 0 -1.020728 0.207130
404 1296 43.000000 1 0 27.7208 0 1 1 0 0 ... 0 0 0 0 0 1 0 0 0.952632 -0.140162
405 1297 20.000000 0 0 13.8625 0 1 1 0 0 ... 1 0 0 0 0 0 1 0 -0.793032 -0.388515
406 1298 23.000000 1 0 10.5000 1 0 0 0 1 ... 1 0 0 0 0 0 1 0 -0.565337 -0.448774
407 1299 50.000000 1 1 211.5000 0 1 1 0 0 ... 0 0 0 0 0 1 0 0 1.483921 3.153324
408 1300 19.895581 0 0 7.7208 1 0 0 1 0 ... 0 1 0 0 1 0 0 0 -0.800957 -0.498580
409 1301 3.000000 1 1 13.7750 1 0 0 0 1 ... 0 1 0 0 1 0 0 0 -2.083305 -0.390083
410 1302 35.295824 0 0 7.7500 1 0 0 1 0 ... 0 1 0 0 1 0 0 0 0.367897 -0.498056
411 1303 37.000000 1 0 90.0000 0 1 0 1 0 ... 0 0 1 0 0 0 0 0 0.497241 0.975936
412 1304 28.000000 0 0 7.7750 1 0 0 0 1 ... 0 1 0 0 1 0 0 0 -0.185845 -0.497608
413 1305 30.705727 0 0 8.0500 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 0.019516 -0.492680
414 1306 39.000000 0 0 108.9000 0 1 1 0 0 ... 0 0 1 0 0 0 0 0 0.649038 1.314641
415 1307 38.500000 0 0 7.2500 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 0.611089 -0.507017
416 1308 30.705727 0 0 8.0500 1 0 0 0 1 ... 0 1 0 0 0 0 0 1 0.019516 -0.492680
417 1309 25.729701 1 1 22.3583 1 0 1 0 0 ... 0 1 0 0 0 0 0 1 -0.358157 -0.236263
418 rows × 23 columns
In [545]:
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_predictions2.csv", index=False)
一般做到后期,咱们要进行模型优化的方法就是模型融合啦
先解释解释啥叫模型融合哈,我们还是举几个例子直观理解一下好了。
大家都看过知识问答的综艺节目中,求助现场观众时候,让观众投票,最高的答案作为自己的答案的形式吧,每个人都有一个判定结果,最后我们相信答案在大多数人手里。
再通俗一点举个例子。你和你班某数学大神关系好,每次作业都『模仿』他的,于是绝大多数情况下,他做对了,你也对了。突然某一天大神脑子犯糊涂,手一抖,写错了一个数,于是…恩,你也只能跟着错了。
我们再来看看另外一个场景,你和你班5个数学大神关系都很好,每次都把他们作业拿过来,对比一下,再『自己做』,那你想想,如果哪天某大神犯糊涂了,写错了,but另外四个写对了啊,那你肯定相信另外4人的是正确答案吧?
最简单的模型融合大概就是这么个意思,比如分类问题,当我们手头上有一堆在同一份数据集上训练得到的分类器(比如logistic regression,SVM,KNN,random forest,神经网络),那我们让他们都分别去做判定,然后对结果做投票统计,取票数最多的结果为最后结果。
bingo,问题就这么完美的解决了。
模型融合可以比较好地缓解,训练过程中产生的过拟合问题,从而对于结果的准确度提升有一定的帮助。
话说回来,回到我们现在的问题。你看,我们现在只讲了logistic regression,如果我们还想用这个融合思想去提高我们的结果,我们该怎么做呢?
既然这个时候模型没得选,那咱们就在数据上动动手脚咯。大家想想,如果模型出现过拟合现在,一定是在我们的训练上出现拟合过度造成的对吧。
那我们干脆就不要用全部的训练集,每次取训练集的一个subset,做训练,这样,我们虽然用的是同一个机器学习算法,但是得到的模型却是不一样的;同时,因为我们没有任何一份子数据集是全的,因此即使出现过拟合,也是在子训练集上出现过拟合,而不是全体数据上,这样做一个融合,可能对最后的结果有一定的帮助。对,这就是常用的Bagging。
我们用scikit-learn里面的Bagging来完成上面的思路,过程非常简单。代码如下:
In [ ]:
from sklearn.ensemble import BaggingRegressor
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*|Mother|Child|Family|Title')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到BaggingRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=10, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y)
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass.*|Mother|Child|Family|Title')
predictions = bagging_clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("/Users/MLS/Downloads/logistic_regression_predictions2.csv", index=False)
In [ ]:
In [ ]:
下面是咱们用别的分类器解决这个问题的代码:
In [581]:
import numpy as np
import pandas as pd
from pandas import DataFrame
from patsy import dmatrices
import string
from operator import itemgetter
import json
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import train_test_split,StratifiedShuffleSplit,StratifiedKFold
from sklearn import preprocessing
from sklearn.metrics import classification_report
from sklearn.externals import joblib
##Read configuration parameters
train_file="train.csv"
MODEL_PATH="./"
test_file="test.csv"
SUBMISSION_PATH="./"
seed= 0
print train_file,seed
# 输出得分
def report(grid_scores, n_top=3):
top_scores = sorted(grid_scores, key=itemgetter(1), reverse=True)[:n_top]
for i, score in enumerate(top_scores):
print("Model with rank: {0}".format(i + 1))
print("Mean validation score: {0:.3f} (std: {1:.3f})".format(
score.mean_validation_score,
np.std(score.cv_validation_scores)))
print("Parameters: {0}".format(score.parameters))
print("")
#清理和处理数据
def substrings_in_string(big_string, substrings):
for substring in substrings:
if string.find(big_string, substring) != -1:
return substring
print big_string
return np.nan
le = preprocessing.LabelEncoder()
enc=preprocessing.OneHotEncoder()
def clean_and_munge_data(df):
#处理缺省值
df.Fare = df.Fare.map(lambda x: np.nan if x==0 else x)
#处理一下名字,生成Title字段
title_list=['Mrs', 'Mr', 'Master', 'Miss', 'Major', 'Rev',
'Dr', 'Ms', 'Mlle','Col', 'Capt', 'Mme', 'Countess',
'Don', 'Jonkheer']
df['Title']=df['Name'].map(lambda x: substrings_in_string(x, title_list))
#处理特殊的称呼,全处理成mr, mrs, miss, master
def replace_titles(x):
title=x['Title']
if title in ['Mr','Don', 'Major', 'Capt', 'Jonkheer', 'Rev', 'Col']:
return 'Mr'
elif title in ['Master']:
return 'Master'
elif title in ['Countess', 'Mme','Mrs']:
return 'Mrs'
elif title in ['Mlle', 'Ms','Miss']:
return 'Miss'
elif title =='Dr':
if x['Sex']=='Male':
return 'Mr'
else:
return 'Mrs'
elif title =='':
if x['Sex']=='Male':
return 'Master'
else:
return 'Miss'
else:
return title
df['Title']=df.apply(replace_titles, axis=1)
#看看家族是否够大,咳咳
df['Family_Size']=df['SibSp']+df['Parch']
df['Family']=df['SibSp']*df['Parch']
df.loc[ (df.Fare.isnull())&(df.Pclass==1),'Fare'] =np.median(df[df['Pclass'] == 1]['Fare'].dropna())
df.loc[ (df.Fare.isnull())&(df.Pclass==2),'Fare'] =np.median( df[df['Pclass'] == 2]['Fare'].dropna())
df.loc[ (df.Fare.isnull())&(df.Pclass==3),'Fare'] = np.median(df[df['Pclass'] == 3]['Fare'].dropna())
df['Gender'] = df['Sex'].map( {'female': 0, 'male': 1} ).astype(int)
df['AgeFill']=df['Age']
mean_ages = np.zeros(4)
mean_ages[0]=np.average(df[df['Title'] == 'Miss']['Age'].dropna())
mean_ages[1]=np.average(df[df['Title'] == 'Mrs']['Age'].dropna())
mean_ages[2]=np.average(df[df['Title'] == 'Mr']['Age'].dropna())
mean_ages[3]=np.average(df[df['Title'] == 'Master']['Age'].dropna())
df.loc[ (df.Age.isnull()) & (df.Title == 'Miss') ,'AgeFill'] = mean_ages[0]
df.loc[ (df.Age.isnull()) & (df.Title == 'Mrs') ,'AgeFill'] = mean_ages[1]
df.loc[ (df.Age.isnull()) & (df.Title == 'Mr') ,'AgeFill'] = mean_ages[2]
df.loc[ (df.Age.isnull()) & (df.Title == 'Master') ,'AgeFill'] = mean_ages[3]
df['AgeCat']=df['AgeFill']
df.loc[ (df.AgeFill<=10) ,'AgeCat'] = 'child'
df.loc[ (df.AgeFill>60),'AgeCat'] = 'aged'
df.loc[ (df.AgeFill>10) & (df.AgeFill <=30) ,'AgeCat'] = 'adult'
df.loc[ (df.AgeFill>30) & (df.AgeFill <=60) ,'AgeCat'] = 'senior'
df.Embarked = df.Embarked.fillna('S')
df.loc[ df.Cabin.isnull()==True,'Cabin'] = 0.5
df.loc[ df.Cabin.isnull()==False,'Cabin'] = 1.5
df['Fare_Per_Person']=df['Fare']/(df['Family_Size']+1)
#Age times class
df['AgeClass']=df['AgeFill']*df['Pclass']
df['ClassFare']=df['Pclass']*df['Fare_Per_Person']
df['HighLow']=df['Pclass']
df.loc[ (df.Fare_Per_Person<8) ,'HighLow'] = 'Low'
df.loc[ (df.Fare_Per_Person>=8) ,'HighLow'] = 'High'
le.fit(df['Sex'] )
x_sex=le.transform(df['Sex'])
df['Sex']=x_sex.astype(np.float)
le.fit( df['Ticket'])
x_Ticket=le.transform( df['Ticket'])
df['Ticket']=x_Ticket.astype(np.float)
le.fit(df['Title'])
x_title=le.transform(df['Title'])
df['Title'] =x_title.astype(np.float)
le.fit(df['HighLow'])
x_hl=le.transform(df['HighLow'])
df['HighLow']=x_hl.astype(np.float)
le.fit(df['AgeCat'])
x_age=le.transform(df['AgeCat'])
df['AgeCat'] =x_age.astype(np.float)
le.fit(df['Embarked'])
x_emb=le.transform(df['Embarked'])
df['Embarked']=x_emb.astype(np.float)
df = df.drop(['PassengerId','Name','Age','Cabin'], axis=1) #remove Name,Age and PassengerId
return df
#读取数据
traindf=pd.read_csv(train_file)
##清洗数据
df=clean_and_munge_data(traindf)
########################################formula################################
formula_ml='Survived~Pclass+C(Title)+Sex+C(AgeCat)+Fare_Per_Person+Fare+Family_Size'
y_train, x_train = dmatrices(formula_ml, data=df, return_type='dataframe')
y_train = np.asarray(y_train).ravel()
print y_train.shape,x_train.shape
##选择训练和测试集
X_train, X_test, Y_train, Y_test = train_test_split(x_train, y_train, test_size=0.2,random_state=seed)
#初始化分类器
clf=RandomForestClassifier(n_estimators=500, criterion='entropy', max_depth=5, min_samples_split=1,
min_samples_leaf=1, max_features='auto', bootstrap=False, oob_score=False, n_jobs=1, random_state=seed,
verbose=0)
###grid search找到最好的参数
param_grid = dict( )
##创建分类pipeline
pipeline=Pipeline([ ('clf',clf) ])
grid_search = GridSearchCV(pipeline, param_grid=param_grid, verbose=3,scoring='accuracy',
cv=StratifiedShuffleSplit(Y_train, n_iter=10, test_size=0.2, train_size=None, indices=None,
random_state=seed, n_iterations=None)).fit(X_train, Y_train)
# 对结果打分
print("Best score: %0.3f" % grid_search.best_score_)
print(grid_search.best_estimator_)
report(grid_search.grid_scores_)
print('-----grid search end------------')
print ('on all train set')
scores = cross_val_score(grid_search.best_estimator_, x_train, y_train,cv=3,scoring='accuracy')
print scores.mean(),scores
print ('on test set')
scores = cross_val_score(grid_search.best_estimator_, X_test, Y_test,cv=3,scoring='accuracy')
print scores.mean(),scores
# 对结果打分
print(classification_report(Y_train, grid_search.best_estimator_.predict(X_train) ))
print('test data')
print(classification_report(Y_test, grid_search.best_estimator_.predict(X_test) ))
model_file=MODEL_PATH+'model-rf.pkl'
joblib.dump(grid_search.best_estimator_, model_file)