目的:对概念有个准确的认识
-
mybatis是程序调用数据库的中间件?还是数据的中间件?
- mybatis是一个持久层框架--orm(对象关系映射框架) 相对应hibernate 由于需要编写sql 所有算半个ORM框架
- 持久层可以将业务数据存储到磁盘,具有长期存储的功能
- java通过mybatis访问数据库
- 内部封装了JDBC,加载驱动,创建连接,创建statement等复杂过程,开发人员只需要进行关注sql就行
-
mybatis的优缺点
- 由于使用sql 依赖数据库 所有数据库移植性查(切换数据库 需要重新梳理编写sql;THB项目的归属圈 从 oracle(总公司)--mysql(分公司))
- 使用sql 处理复杂的sql 字段多的 sql 对开发人员要求高
- mybatis 作为持久层框架 具有承上(程序)启下(数据库)的作用,由于基于sql编程,灵活 不会对程序或者数据库造成影响;sql写在xml里边解除了 与程序的耦合且方便管理;xml提供了标签,方便处理复杂的sql,还能复用
-
在做xml映射的时候 入参 单个参数 多个参数 实体类 ;以及出参参数的通过什么方式进行接收的?
- 参考 xml 中select 标签中 parameterType resultMap resultType 的使用
-
mybatis一级缓存 二级缓存值得是什么?
- 缓存的意义是 减少数据库的查询(索引硬盘)次数
- 把数据存储到内存中或者高速缓存处理中,提高查询效率,一般是把命中率搞得数据缓存起来,方便查找;命中率低的不缓存,还是需要从硬盘中查找。
- 一级缓存是SqlSession层面的缓存;二级缓存是SqlSessionFactory层面的缓存 默认的情况下开启的是一级缓存;开启二级缓存需要对缓存POJO对象进行序列化
- 如何开启二级缓存呢?在映射文件xml上 加上一行代码:<cache/>
- 一级缓存是sqlSession级别的缓存的作用域是SqlSession;二级缓存是sqlSessionFactory级别的缓存作用域是namespace(在mybatis中,映射文件中的namespace是用于绑定Dao接口的,即面向接口编程。)。
-
不同之处在于二级缓存的存储作用域是Mapper(Namespace),并且还能够自定义存储源。
-
二级缓存是多个sqlsession共享的,其作用域是mapper的同一个namespace。
即,在不同的sqlsession中,相同的namespace下,相同的sql语句,并且sql模板中参数也相同的,会命中缓存。
第一次执行完毕会将数据库中查询的数据写到缓存,第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。
- 二级缓存是在多个SqlSession在同一个Mapper文件中共享的缓存,它是Mapper级别的,其作用域是Mapper文件中的namespace,默认是不开启的
- 二级缓存开启后是怎么处理 增删改查逻辑的?
- 增删改 会清空(刷新)缓存 ;缓存的Entry对象(k,v),清空的意义是将所有的Entry对象中的value 设置成null;
- 增删改 的时候也可以不影响缓存 ,在增删改的 xml 标签中加上 flushCache=“false”
- 二级缓存在什么时候真正执行查询呢
- 根据key 没有这个Entry对象
- 或者通过key 可以查询到这个value 为null
- 二级缓存的配置 目前THB项目只是开启了二级缓存,并没有对二级缓存进行详细的配置 可以配置项 缓存存储的时间,存储的个数,已经数量超过后的删除规则
- 映射文件

-
size:二级缓存可以执行操作的数目(完成一次程序中的查询算一个)eviction:驱逐策略,当二级缓存满时,选择几个进行删除
- LRU - 最近最少回收,移除最长时间不被使用的对象(默认)
flushInterval:规定时间定时清空二级缓存
- 映射文件
- 二级缓存使用规则
-
)不要出现多个namespace操作一张表的情况2)对关联对象关系不要出现增删改操作3)当查询操作多于增删改操作时可以使用二级缓存
-
- 在MyBatis中有flushCache、useCache这两个配置属性,分为下面几种情况:
(1)当为select语句时:
flushCache默认为false,表示任何时候语句被调用,都不会去清空本地缓存和二级缓存。
useCache默认为true,表示会将本条语句的结果进行二级缓存。
(2)当为insert、update、delete语句时:
flushCache默认为true,表示任何时候语句被调用,都会导致本地缓存和二级缓存被清空。
useCache属性在该情况下没有。 - Mybatis的一级缓存是指Session缓存。一级缓存的作用域默认是一个SqlSession。Mybatis默认开启一级缓存。
- Mybatis的二级缓存是指mapper映射文件。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。
-
springboot 开启二级缓存分为两步
-
yml文件集成mybatis 设置缓存为开启,(THB给关了 所以该项目不支持二级缓存)
-
mybatis:
mapperLocations: classpath*:mapper/**/*Dao.xml
executor-type: REUSE
configuration:
# 开启mybatis 的二级缓存
cache-enabled: true
# 开启sql打印
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
-
- mapper 对应的xml 需要 开启 <cache/>
-
<!-- 默认开启二级缓存,使用Least Recently Used(LRU,最近最少使用的)算法来收回 --> <cache/>
-
-
- 验证
- spring boot集成mybatis 开启一级缓存 需要在service层 加上 @Transactional 事务
- 原理 那是因为它每条语句执行结束以后,都会执行提交方法,而提交方法在每次都会清空本地缓存。而开启了事务的话,方法是在所有操作结束以后才会提交,因此就会支持一级缓存
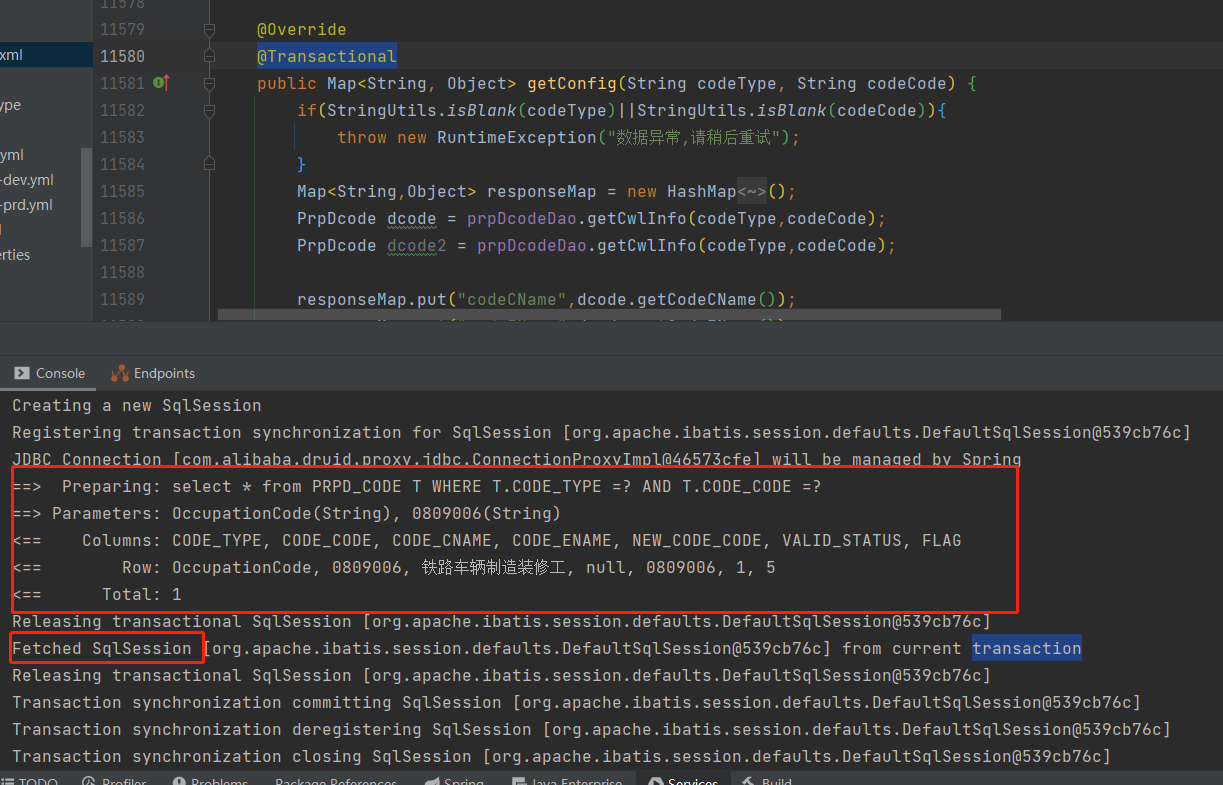
- spring boot集成 mybatis 开启二级缓存(目前存在的疑问是 二级缓存开启无效)
要想实现两个命名空间共享缓存,那么可以cache-ref标签的namespace属性引入另一个命名空间,如:
-
注意:如果应用是分布式部署,由于二级缓存存储在本地,必然导致查询出脏数据,所以,分布式部署的应用不建议开启。
- spring boot集成mybatis 开启一级缓存 需要在service层 加上 @Transactional 事务
-
作业 想一下 spring boot + mybatis + redis 实现二级缓存
-
-
什么是SqlSession 和 sqlSessionFactory 呢?
- sqlSessionFactory 可以认为是一个数据库连接池,为每个接入项目的用户 生成生成一个sqlSession(数据库连接对象 connection对象)
- sqlSessionFactory 占据着数据库的链接资源,如果存在多个不利于资源控制,一般应用中SqlSessionFactory作为单例共享使用
- sqlSession 相当于一个链接对象,可以处理多条语句,但是在完成业务操作之后,要关闭这条链接,归还给SqlSessionFactroy中,使用try catch finally 保证其正确关闭
- 所有一级缓存方便的是 同一个sqlSession下的查询操作,二级缓存是方便整个应用是跨sqlSession 的;二级缓存对应不同的SqlSession对象也能共享缓存,
-
.数据库连接池 用的是什么 ?阿里的德鲁伊吗?有什么作用呢?
- 使用一款数据库连接池作为缓冲,提高性能
修改application.properties文件,加入Druid配置和Mybatis配置
#修改tomcat端口为80 server.port=80 #设置Tomcat编码 server.tomcat.uri-encoding=UTF-8 #MyBatis配置 mybatis.config-location: classpath:mybatis/mybatis-cfg.xml mybatis.type-aliases-package=com.example.demo.pojo mybatis.mapper-locations=classpath:/com/example/demo/mapper/*.xml #数据库连接池配置 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.druid.initial-size = 5 spring.datasource.druid.max-active = 20 spring.datasource.druid.min-idle = 5 spring.datasource.druid.max-wait= 30000 #数据库配置 spring.datasource.druid.driver-class-name=com.mysql.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://127.0.0.1:3306/report_manage
# 配置druid后台登录 spring.datasource.druid.username=root spring.datasource.druid.password=root
2. 连接池的概念 优点
连接池就是用于存储连接对象的一个容器。而容器就是一个集合,且必须是线程安全的,即两个线程不能拿到同一个连接对象。同时还要具备队列的特性:先进先出原则。
实际开发中都会用到连接池 ,因为减少了我们获取连接消耗的时间
使用连接池的好处:避免频繁创建和关闭数据库连接造成的开销,节省系统资源。
7.mybatis 使用自己的连接池的为什么实际开发中使用的druid/C3P0 比较多
druid为阿里巴巴的数据源,(数据库连接池),集合了c3p0、dbcp、proxool等连接池的优点,还加入了日志监控,有效的监控DB池连接和SQL的执行情况。
- #{xx} 防止sql注入 这个时候 xx是以字符串的方式拼接到sql中的,自动在xx 加上引号 预处理
- ${xx} 不能防止sql注入,xx是以原样拼接到sql上,如果含有 ;seletc insett 这种语言 很有可能拼接到SQL上作为sql的关键语句处理
- ${}是字符串替换,#{}是预处理
- MyBatis在处理#{}时,会将SQL中的#{}替换为?号,使用PreparedStatement的set方法来赋值;MyBatis在处理 $ { } 时,就是把 ${ } 替换成变量的值。
- 使用 #{} 可以有效的防止SQL注入,提高系统安全性。
<select id ="getCwlInfo" resultMap="BaseResultMap" parameterType="map" useCache="true" flushCache="false">
select * from PRPD_CODE T WHERE T.CODE_TYPE =#{codeType} AND T.CODE_CODE ='${codeCode}'
</select>
-
一个mapper.xml文件对应一个Dao接口,这个Dao接口的工作原理是什么?
- 动态代理(作业2)
-
mybatis 如何进行分页的?
- RowBounds(行绑定) 分页类,使用十分简单在mapper接口中加一个rowBounds参数即可
- new RowBounds(0, 5),即第一页,每页取5条数据
-
模糊查询like怎么写的?
- sql 语句拼接:
- xxx like CONCAT('%',#{kw},'%') 字符串拼接
- string xx = haha ; xxx like '%${xx}%' ;
- '%#{xx}%' 报错 识别是一个字符串,无法识别到 #{xx}
- java代码中添加sql通配符%
- String xx = '%haha%' ; xxx like #{xx}
- sql 语句拼接:
-
当实体类中属性名和表中字段名不一致的情况下怎么处理?
- 我能想到的两种方式:1使用resultMap进行映射;2 查询sql 使用别名通过双引号转驼峰式
- resultMap字段映射
<resultMap id="getAllRenewalResult" type="HashMap"> <result property="ebusinessNo" column="ebusiness_no" jdbcType="VARCHAR" /> </resultMap> <select id="getRenewalStatus" parameterType="java.util.List" resultMap="getAllRenewalResult"> select eb.ebusiness_no from eb_order_form eb inner join prp_item_car prp on eb.ebusiness_no = prp.ebusiness_no inner join Prp_Car_Owner ow on prp.ebusiness_no = ow.ebusiness_no and ow.certificate_no is not null where eb.order_status = 'validPolicy' and substr(ow.certificate_no, -6) = #{idCode} <if test="frameNo != null and frameNo != ''"> and prp.frame_no = #{frameNo} </if> <if test="licenseNo != null and licenseNo != ''"> and eb.license_no = #{licenseNo} </if> order by eb.end_date desc </select> -
select eb.member_code "memberCode" from eb_order_form eb where eb.policy_no = '201021503202021000013';
- resultMap字段映射
- 我能想到的两种方式:1使用resultMap进行映射;2 查询sql 使用别名通过双引号转驼峰式
-
mapper中如何传递多个参数?
-
mapper中的 association 标签
- 级联查询 一对一
- 级联是在resultMap标签中配置。级联不是必须的,级联的好处是获取关联数据十分便捷,但是级联过多会增加系统的复杂度,同时降低系统的性能,次增彼减,所以记录超过3层时,就不要考虑使用级联了,因为这样会造成多个对象的关联,导致系统的耦合、负载和难以维护。
MyBatis中的级联分2种:
1.一对一(association)
2.一对多(collection)
-
mybatis中的 动态sql的作用?
- 方便处理复杂的业务逻辑
16.mybaits中的 两种映射器
1.mapper 和 xml 映射器
maper层
//根据电子商务号查询主表信息
List<PrpMain> selectByEbusinesssNo(@Param("ebusinessNo") String ebusinessNo);
xml层
<!-- 通用查询结果对象-->
<resultMap id="BaseResultMap" type="ins.platform.admin.policyCar.po.PrpMain">
<id column="ID" property="id"/>
<result column="EBUSINESS_NO" property="ebusinessNo"/>
</resultMap>
<!--按ebusinessNo查询数据-->
<select id="selectByEbusinesssNo" resultMap="BaseResultMap" parameterType="map">
select
<include refid="Base_Column_List"></include>
from PRP_MAIN
where EBUSINESS_NO = #{ebusinessNo}
</select>
2.注解映射器
/**
* 查询经营范围和行业归属
* @param custId
* @return
*/
@Select("select ZSOPSCOPE,INDU_CONAME,ENTSTATUS, OPFROM ,OPTO from AIC_CUST_BASIC_INFO_E where CUST_ID = #{custId}")
List<AicCustBasicInfo> getZsopscopeE(@Param("custId") String custId);
17.select元素中 parameterType resultMap resultType 的使用?
- parameterType 接受mapper中的参数
- resultMap , resultType 在select标签中只能用一个用于处理查询的返回值
18.mybatis 是否支持延迟加载,什么是延迟加载?
-- 支持 setting文件中配置;
-- 延迟加载是在级联数据查询中,对不常用的数据,在用到的时候才取出
19.传递参数paramterType(参数类型)
1.使用map接口传递参数 可读性差
---service HashMap<String, Object> map = new HashMap<>(); map.put("codeType",codeType); map.put("codeCode",codeCode); PrpDcode dcode = prpDcodeDao.getCwlInfo(map); --mapper dao PrpDcode getCwlInfo(Map<String,Object> parameterMap); --xml
<!-- 通用查询结果对象-->
<resultMap id="BaseResultMap" type="ins.platform.admin.code.po.PrpDcode">
<id column="CODE_CODE" property="codeCode"/>
<id column="CODE_TYPE" property="codeType"/>
<result column="CODE_CNAME" property="codeCName"/>
<result column="CODE_ENAME" property="codeEName"/>
<result column="NEW_CODE_CODE" property="newCodeCode"/>
<result column="VALID_STATUS" property="validStatus"/>
<result column="FLAG" property="flag"/>
</resultMap>
---1.使用POJO存储结果集
<select id ="getCwlInfo" resultMap="BaseResultMap" parameterType="map" > select * from PRPD_CODE T WHERE T.CODE_TYPE =#{codeType} AND T.CODE_CODE =#{codeCode} </select>
---2.使用map存储结果集(可读性下降)
<select id ="getCwlInfo" resultType="map" parameterType="map" > select * from PRPD_CODE T WHERE T.CODE_TYPE =#{codeType} AND T.CODE_CODE =#{codeCode} </select>
2.使用注解传递参数
使用注解传参,入参类型 parameterType 元素可以为空
--dao String selectCode(@Param("codeType") String codeType,@Param("codeCode") String codeCode); --xml <select id ="getCwlInfo" resultType="map" > select * from PRPD_CODE T WHERE T.CODE_TYPE =#{codeType} AND T.CODE_CODE =#{codeCode} </select>
3.使用Java Bean 对象传递参数(参数特别多,方便使用)
--dao List<EbCar> getMyCar(EbCar ebCar); --xml <select id="selectCarList" resultMap="BaseResultMap" parameterType="ins.platform.admin.member.po.EbCar"> select ID, LICENSE_NO AS licenseNo, from EB_CAR where id = #{id} </select>