前言
多年前入职了现在的公司,当时还没有完整的异常测试的体系,后来根据自己的经验结合现状,帮助公司建立了一套异常测试的流程和文档,和另外的同学一起设计了异常故障注入平台,也完成了一些演练的落地,在这里做一些总结。
kv故障演练
kv即key-value数据库,业界普遍使用的有redis、zookeeper等,和关系型数据库如mysql相比一般只提供对key的CRUD等的简单操作,读写速度却快很多。
kv在我们现在的系统中有几种使用用途:
- 用于缓存数据,将数据库的数据缓存到kv里,减轻大量查询对数据库访问的压力
- 用于临时数据的存储,比如锁、登陆态、记数器等
由于之前线上出现过因为kv异常导致整体业务不可用的问题,所以需要对所有使用kv的场景进行排查,确认是否是强依赖、是否能够降级,最终做到kv故障也不会影响核心业务的运行。
场景分析
在场景分析阶段,需要拉各业务线统一进行分析和梳理,确认各业务和应用在哪些场景和哪些接口逻辑里面有调用到kv,是否有降级,进行梳理和记录。
可以简单按这个方式登记下:
| 业务线 | 依赖kv的场景 | 是否有降级或者处理异常 |
| x x x |x x x | x x x |
在记录之后,需要审视和评估,这些使用到kv的地方是否合理,是否能做降级,比如:
- 查询kv失败,如果数据存储在db是否可以降级为查db;
- 核心流程里面加锁解锁访问kv失败,到底应该忽略错误让业务进行下去还是抛异常中断流程或是做其他异常处理,需要进行权衡、谨慎判断
在这过程中发现的问题可以提前进行优化,避免到了实际演练的时候出现太多的阻塞问题
确认用例&制定计划
根据之前的分析,整理出了各业务涉及kv的场景和用例,但仅仅有这些是不够的。做kv故障演练的根本目的还是保证核心主流程在kv异常时还能够正常运行,所以演练的用例还是要以核心主流程为基础。另一方面,随着系统复杂度的提高,业务方互相调用错综复杂,以业务方为纬度的梳理往往不够全面,比如业务方A没有调用kv的场景,但A的主流程会调用业务方B的接口,而该业务方B的接口的是个不太重要的功能但依赖了kv,可能就会被遗漏。
这样的问题适合在演练的时候发现,这实际上也是种集成的概念:各业务单元先保证自己对kv的依赖和处理是合理的,然后集成在一起,通过演练确保整体业务是健壮的。
于是我们可以根据核心主流程和依赖kv的场景输出演练时候的用例。有了场景和用例,可以制定相关的演练计划。考虑到业务之间存在依赖,比如只有账号功能正常了,才能登陆后做后续的操作;只有支付功能正常,才能下单走交易流程。所以在执行上需要安排基础业务方先行进行操作和验证,没有问题后再安排后续业务方进行验证。
最后,一个完整的演练计划包括这么几个步骤:
- 起始时间和各阶段的时间。因为故障演练一般在测试环境进行,会影响其他人的使用,所以时间选择需要避开高峰时间段同时控制时长,并提前通知。
- 执行故障。需要提前和运维或者kv维护人员沟通,安排人进行故障注入操作。
- 执行降级。有些降级需要手动执行,需要加入计划中,注明操作项和操作人,只有确保降级成功后再开始后续验证。
- 业务回归。先让基础业务方进行回归,再安排上层业务方参与。
- 问题排查和记录,对于发现的问题统一进行记录。
- 故障恢复。恢复故障后,各业务方确认业务是否都恢复正常。
- 分析汇总结果。对于执行失败的case和发现的问题,进行记录和补充原因,需要进行后续排查、优化的给出后续计划和时间点。
执行演练
按照之前的计划执行演练,最好将参与演练的开发和测试都安排在大会议室方便交流和问题排查。
先找人对kv注入故障,比如停掉服务,然后通知需要手动降级的业务方开始操作降级。降级完成后,让基础业务方先行进行验证,没有问题则通知上层业务方开始介入进行功能回归。
期间可能需要协调不同业务方去排查互相调用时出现的问题。
最后,等各业务方都确认用例执行完成,则可以恢复环境。
记录和分析结果
对于执行过程中的失败,需要详细记录失败场景、报错日志等信息,帮助开发排查问题,也方便自己下次进行回归验证。
演练结束后,对失败的原因进行分析,并给出后续的action。
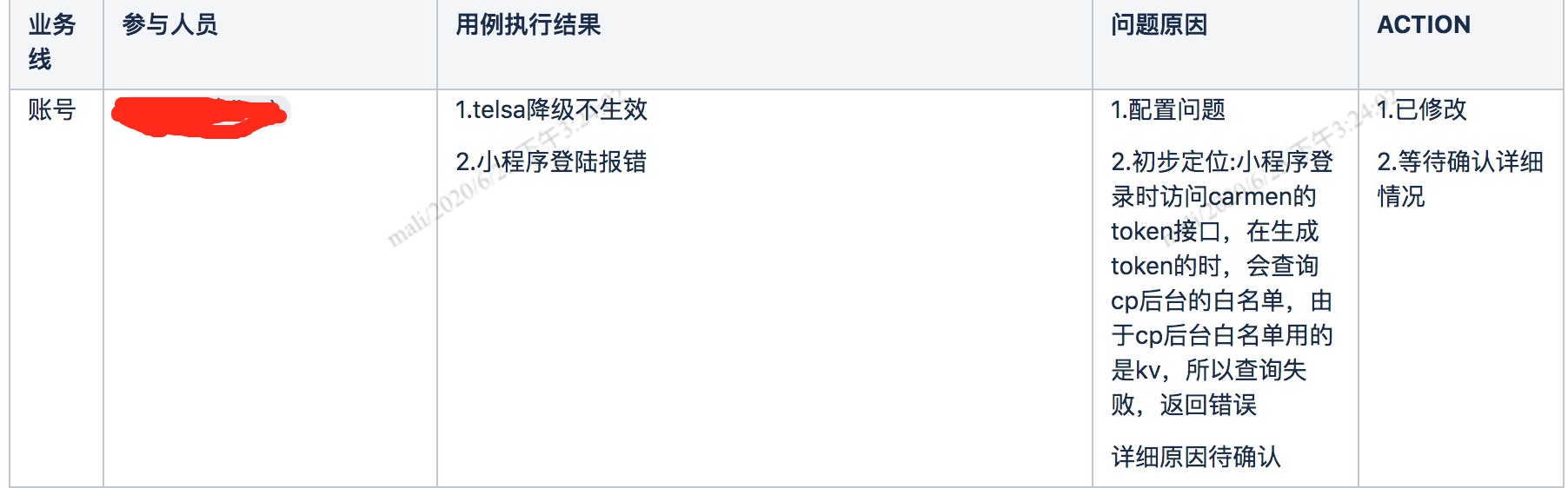
作为演练的负责人,需要不定期的跟进action的完成情况,督促业务方尽快进行优化改进,等上一次演练发现的问题解决的差不多了,就可以开启新一轮的演练。
一般情况下,如果这次是第一次做故障演练,对于整体功能的可用性就不能抱有太大期望,可能在基础业务方这层就会存在问题,导致上层业务无法正常运行。
但是不必气馁,演练就是个需要不断迭代改进和巩固的过程,之前演练了2-3次之后,整体的流程基本上就能跑下来了。看到系统不断的变健壮,还是很有成就感的。
降级演练
双11期间,系统往往会遭遇大流量的洗礼,作为质量保障的一环,需要对系统自动降级和过载保护的有效性进行验证。所以组织了针对性的一次验证和演练。
用例设计
降级
执行方式:接口接入自动降级组件,构造请求,触发配置的规则
关注点:
1.规则是否生效(超时/失败等)
2.降级行为是否符合预期,如返回默认数据或错误,
3.降级期间业务功能是否正常
4.解除异常,降级行为是否能够自动恢复
5.可能的话关注下降级切换花费的时间以及切换过程中的失败率
限流
执行方式:接口接入过载保护组件,构造流量进行加压
关注点:
1.流量超过限制,是否触发限流
2.限流行为是否符合预期
3.流量降低,业务是否恢复正常
热点缓存
执行方式:接口接入过载保护组件,构造流量进行加压
关注点:
1.出现热点商品是否触发过载保护,将热点商品加载到localcache
2.流量降低,业务是否恢复正常模式
测试策略与执行
接口级别验证->功能级别验证
先针对单接口,验证接入组件是否生效。此时可以在降级和过载保护组件里配置强制开启降级,通过简单的接口调用直接触发降级和过载保护,验证处理结果是否符合预期。在这个层次上主要发现降级是否生效,处理逻辑是否正常的问题。
然后根据功能场景,构造流量进行降级和过载的验证。通过不断加压,让流量达到配置的阈值,观察系统是否自动开启了降级和过载保护,持续一段时间,然后观察接口返货、系统响应是否正常,系统状态和日志输出是否正常,然后慢慢降低流量,观察系统是否能够恢复正常。这这个层次上主要发现降级和过载配置合理性的问题以及性能上的问题。
分析总结
对于发现的问题进行分析和总结,推动开发进行优化和改进。
执行单独的降级和过载保护的验证解决的是有无保护的问题,一些配置参数配置是否合理往往需要结合全链路压测的时候来一起进行分析判断。
后记
之前参与主导和编写了公司的测试白皮书,今年出了电子版。有兴趣的朋友可以交流学习下:
https://shop13579785.youzan.com/wscvis/course/detail/2ocqwv300c8oh
