基本统计:

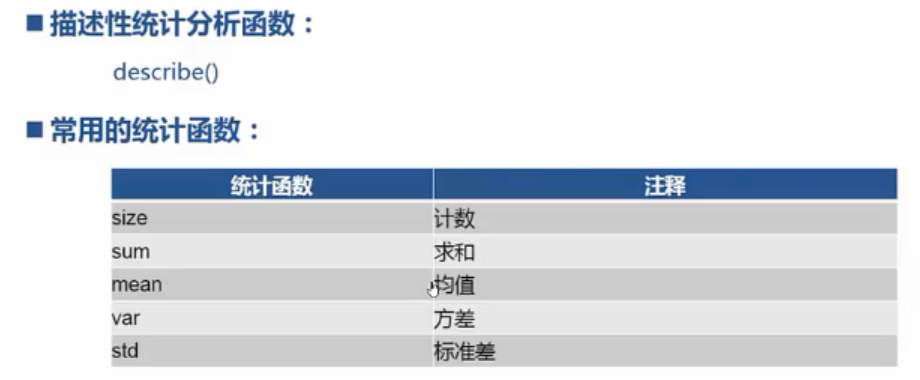


from pandas import read_csv; data = read_csv('D:\PA\8.1\data.csv') data.score.describe() data.score.size data.score.max(); data.score.min; data.score.sum; data.score.mean; data.score.var; data.score.std;
分组分析:

import numpy; from pandas import read_csv; data = read_csv('C:\PA\8.2\data.csv'); data['score2'] = data['score']*2 data.groupby(by=['class'])['score'].agg({ '总分':numpy.sum, '人数':numpy.size, '平均值':numpy.mean, '方差':numpy.var, '标准差':numpy.std }) data.groupby(by=['class', 'name'])[['score', 'score2']].agg([ numpy.size, numpy.sum ]) result = data.groupby(by=['class'])['score'].agg({ '总分':numpy.sum, '人数':numpy.size, '平均值':numpy.mean, '方差':numpy.var, '标准差':numpy.std }) result.index result.columns result['平均值'] result2 = data.groupby(by=['class', 'name'])[['score', 'score2']].agg([ numpy.size, numpy.sum ]) result2.index result2.columns result2['score'] result2['score']['sum'] result.reset_index() result2.reset_index()
分布分析:

import numpy; import pandas; from pandas import read_csv; data = read_csv('D:\PA\8.3\data.csv'); bins = [min(data.年龄)-1, 20, 30, 40, max(data.年龄)+1]; labels = ['20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上']; 年龄分层 = pandas.cut(data.年龄, bins, labels=labels) data['年龄分层'] = 年龄分层; data.groupby(by=['年龄分层'])['年龄'].agg({'人数':numpy.size})
交叉分析:


import numpy; import pandas; from pandas import read_csv; df = read_csv('D:\PA\8.4\data.csv'); bins = [min(df.年龄)-1, 20, 30, 40, max(df.年龄)+1]; labels = ['20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上']; 年龄分层 = pandas.cut(df.年龄, bins, labels=labels) df['年龄分层'] = 年龄分层; r1 = df.pivot_table( values=['年龄'], index=['年龄分层'], columns=['性别'], aggfunc=[numpy.size, numpy.mean] ); r2 = df.pivot_table( values=['年龄'], index=['年龄分层'], columns=['性别'], aggfunc=[numpy.std] ); r1.join(r2)
结构分析:

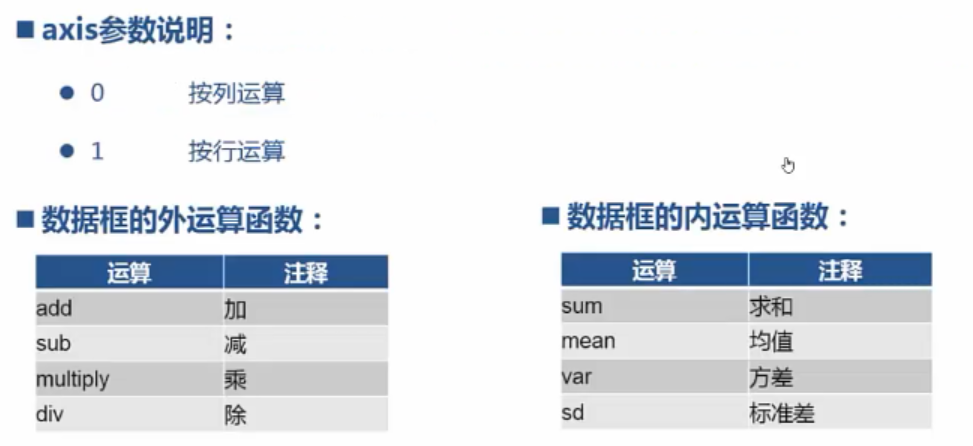
import numpy; from pandas import read_csv; data = read_csv('C:\PA\8.5\data.csv'); data_pt = data.pivot_table( values=['月消费(元)'], index=['省份'], columns=['通信品牌'], aggfunc=[numpy.sum] ); data_pt.sum() data_pt.sum(axis=0) data_pt.sum(axis=1) data_pt.div(data_pt.sum(axis=1), axis=0); data_pt.div(data_pt.sum(axis=0), axis=1);
相关分析:
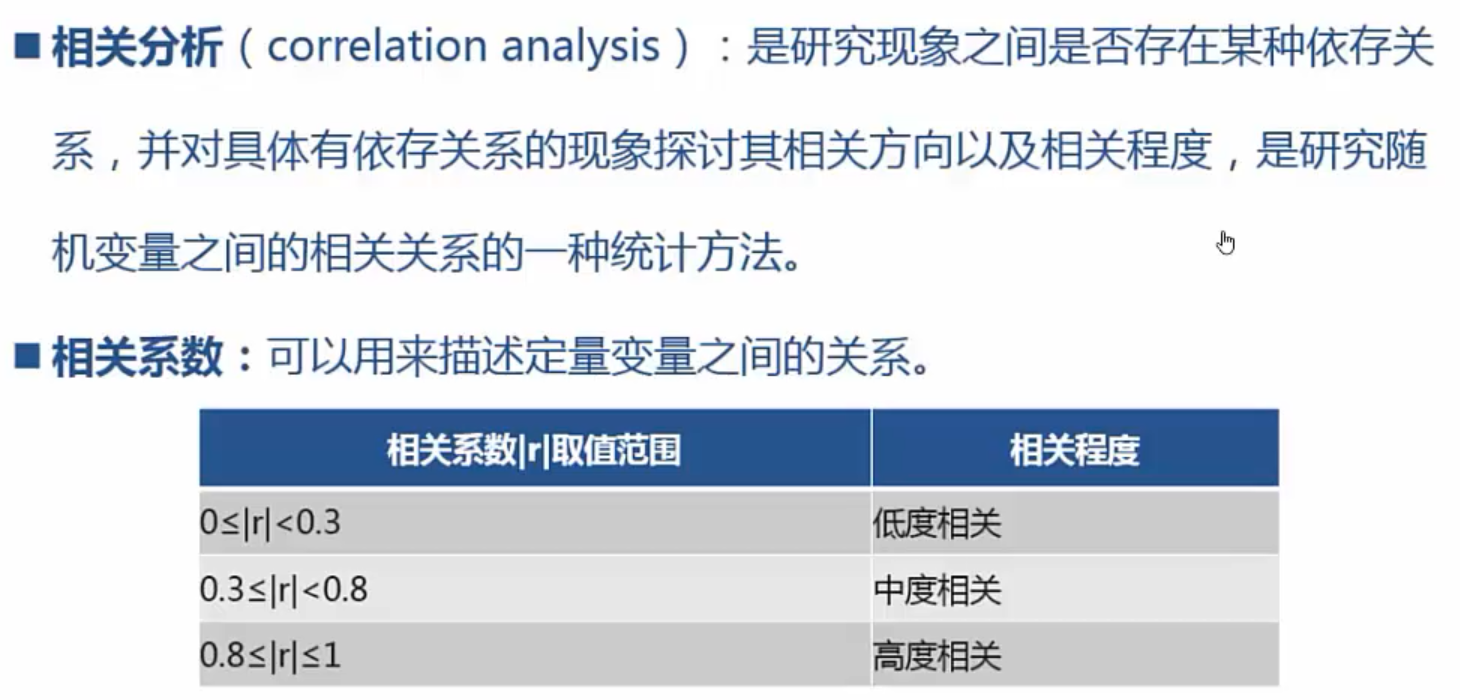

# -*- coding: utf-8 -*- from pandas import read_csv; data = read_csv('D:\PA\8.6\data.csv'); #先来看看如何进行两个列之间的相关度的计算 data['人口'].corr(data['文盲率']) #多列之间的相关度的计算方法 #选择多列的方法 #data.loc[:, ['列1', '列2', '……', '列n']] data.loc[:, ['超市购物率', '网上购物率', '文盲率', '人口']].corr()