其他图像识别链接:https://www.cnblogs.com/sjzh/p/6104105.html
图像归一化和二值化处理链接:https://blog.csdn.net/m0_38052500/article/details/107305000
一、图像基础知识
1) 图像(如rpg格式)由像素点组成
400*300意思是行400像素点,列300像素点
2)每个像素点 => RGB(a,b,c) 其中a b c介于 [0,255]
3)灰色的像素点 a=b=c ,靠近白色则近255,靠近黑色则近0
即:黑白灰图片的像素点必然 a=b=c
总结:一个图像的shape:(行像素,列像素,3)
二、图像识别流程分析
4-0 opencv: 计算机视觉lib
4-1 读取图片 import cv2
digit = cv2.imread("D:/PyProjects/data/KNN/mnist_data/0.0.jpg") plt.imshow(digit) plt.show()
结果:
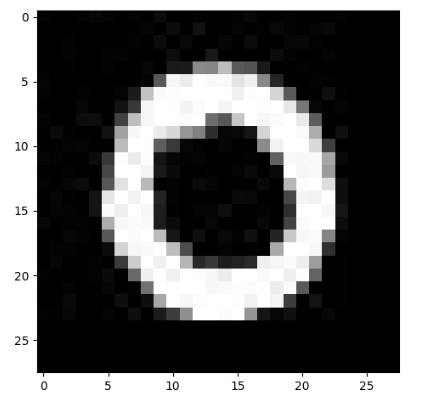
4-2 提取特征
由于处理的是黑白灰图,a=b=c,提取图像的特征只需要2轴中的一个数字,于是
先求出原图的shape => (28,28,3)
digit[:,:,0] 降维成2维, .reshape(784,) 变成1维,28*28=784
结果:获得一维特征

4-3 特征优化—— 二值化处理:黑白灰变成黑白,防止灰色混杂在黑色里
1)手写字体情况:我们并不需要知晓黑色的深浅,只需要知道黑色的部分是否不是黑色。因为不是白色的位置,就意味着是字体的一部分。
>>> 直接 if x!= 255 赋值 1 else 0 # 只要不是白色,就一定是黑色
2)其他:
Q1: 待解决的问题:如何界定判定黑 白的标准?
# 灰 -> 黑 or 白 for rn in range(len(res)): res[rn] = 0 if res[rn] < 100 else 255 train.append(res)
4-4 循环读入图片,num是label,flag是对应num的图片
# 训练目标数组和训练集数组 train,target = [],[] # 利用循环读入0-9的每个3000张图片 for num in range(10): for flag in range(3000): target.append(num) # array-like of shape (n_samples,) or (n_samples, n_outputs) digit = cv2.imread("D:/PyProjects/data/KNN/mnist_data/"+str(num)+"."+str(flag)+".jpg") res = digit[:,:,0].reshape(784) # 灰色R=P=G # 灰 -> 黑 or 白 for rn in range(len(res)): res[rn] = 0 if res[rn] < 100 else 255 train.append(res)
4-5 求最佳近邻值
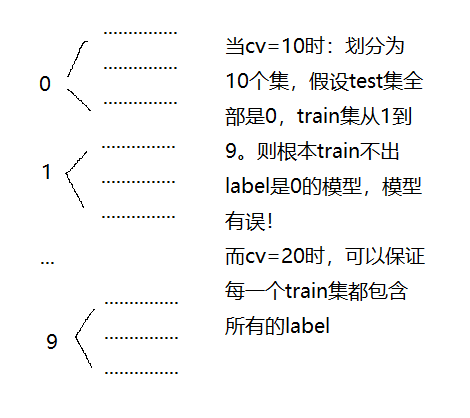
krange = range(1,55) knnscore = [] for k in krange: knn = KNeighborsClassifier() val = cross_val_score(knn,train,target,cv=20,scoring='accuracy') # 为什么20? => 一定有0-9 knnscore.append(val.mean()) plt.plot(krange,knnscore,'r') plt.show()
结果:
问题:为什么cv=20?
4-6 建立KNN模型算法
knn = KNeighborsClassifier(n_neighbors=6,weights='distance',p=2,n_jobs=-1) # p=2 欧式距离;n_jobs=-1 所有线程都工作; knn.fit(train,target) # KNN模型已生成
参数含义见
https://blog.csdn.net/weixin_41990278/article/details/93169529
4-7 测试模型识别结果是否准确
# 图像识别测试 # 数据准备 test,test_target = [],[] for rn in range(10): for co in range(300,310): # 使用每个label的第300-309个图片测试 test_target.append(rn) digit1 = cv2.imread("D:/PyProjects/data/KNN/mnist_data/" + str(rn) + "." + str(co) + ".jpg") res1 = digit1[:, :, 0].reshape(784) # 灰色R=P=G for rn in range(len(res1)): res1[rn] = 0 if res1[rn] < 100 else 255 test.append(res1) # 数据预测 pred_res = knn.predict(test) print("====识别结果===") print(pred_res) print("====真实结果===") print(test_target)