学习慕课网的视频:Hadoop大数据平台架构与实践--基础篇http://www.imooc.com/learn/391
一、第一章
#,Hadoop的两大核心: #,HDFS,分布式文件系统,存储海量的数据;
#,MapReduce,并行计算框架,实现任务分解和调度;
#,Hadoop的优势有哪些呢?
#,高扩张;
#,低成本,不依赖于高端硬件,只要普通pc就可以了,使用软件的容错就可以保证系统的可靠性;
#,有成熟的生态圈,主要是依赖于开源的力量,比如Hive、HBase等,这些工具可以让我们对于Hadoop的使用更加顺手。
在国内、国外的很多大型公司都在用hadoop来搭建自己的平台。已经成为业界的大数据平台的首选;
目前行业对于Hadoop的人才的需求主要包括两个方面,一个是开发人才,一个是运维人才。
第四节,Hadoop生态系统及其版本
#,比如有了Hive之后,我们只需要去写sql语句,然后他就会自动转换为HDFS的命令去执行。
#,HBASE是一个存储结构化数据的分布式数据库,和传统的关系型数据库相比,他放弃了事务特性,转而追求更高的扩展性。与HDFS的不同在于,他提供了对于数据的随机读写和实时访问,实现了对表数据的读写功能。
#,Zookeeper,用于监控hadoop节点的状态,维护他们的一致性等,做集群管理的;
目前Hadoop已经到了ver2.x,不过本次课程主要使用ver1.2的版本来讲解。
第二章,Hadoop安装
主要就是,安装Linux,安装Jdk,安装Hadoop,具体就不写了
第三章,Hadoop的核心,HDFS简介
第一节,HDFS设计架构
基本概念,BLOCK、NameNode、DataNode
HDFS里面的所有文件被分成相同大小的块,每个块的默认大小为64M。块是文件存储和处理的逻辑单元。
HDFS有2类节点,NameNode和DataNode
NameNode是管理节点,用于存放文件的元数据,他包括2点:
1)文件与数据块的映射表;
2)数据块与数据节点的映射表;
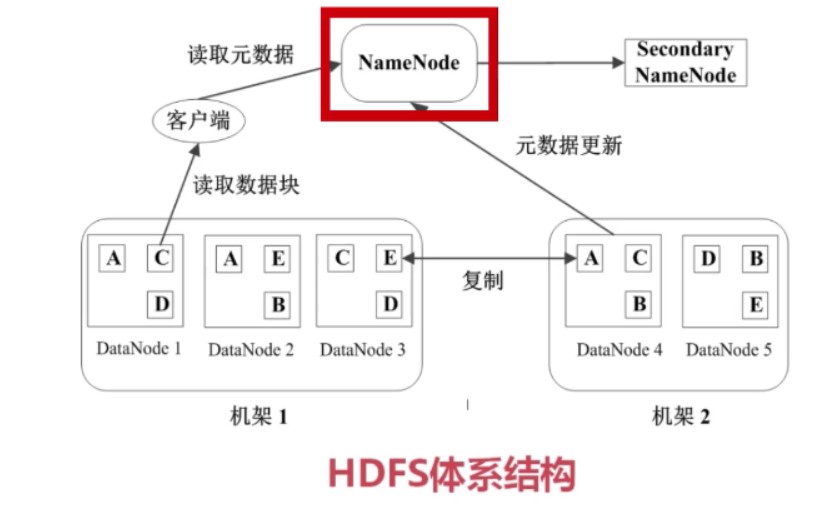
DataNode是HDFS的工作节点,是用于存储真正的数据块的。
第二节,HDFS数据管理策略
HDFS中任何数据块都存储了3份。分布在2个机架的3个节点上。
心跳检测,每个DataNode每隔几秒钟都要以心跳协议向NameNode发送心跳。
二级NameNode,他其实就是NameNode的备机,热备,一旦NameNode挂了,他就自动切换为主NameNode
第三节,HDFS中文件的读写操作
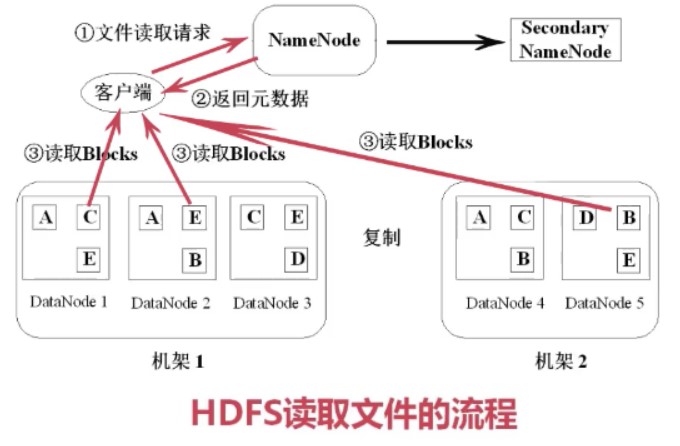
客户端读取文件的基本流程如下:找NameNode要元数据,这样就知道他包括哪些块以及这些块在哪些节点上,然后直接去读取,拼接,如下图所示。
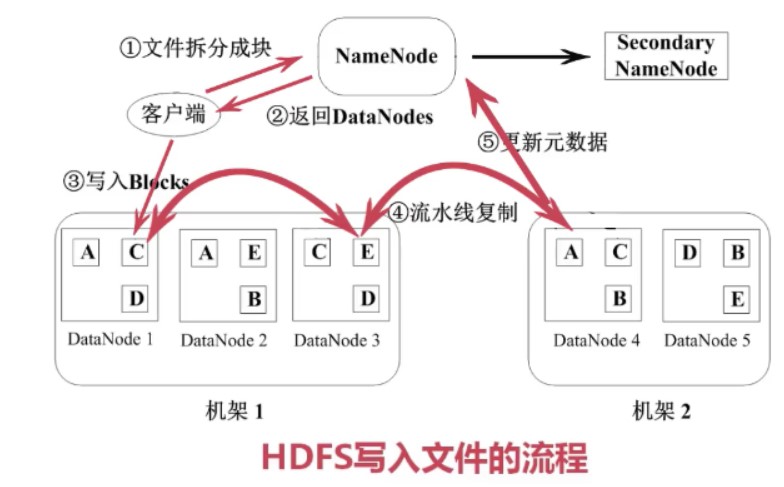
写文件的流程如下:首先是把文件按照64M拆分成多个块,然后找NameNode要DataNode列表,然后开始逐个块写入,先把块写入到其中一个节点,然后他内部会做流水线复制到其他2个节点,然后在更新NameNode的元数据,这样一个块就算写完了,然后再写下一个块。
第四节,HDFS的特点
1)数据冗余,硬件容错;
2)流式的数据访问,写一次,读多次。数据没办法修改,如果要修改只能把之前的数据删除,然后重新写入一份;
3)适合存储大文件,这是设计之初就这么考虑的,如果是大量的小文件的话,不适合,因为一个小文件也要存储元数据,此时NameNode的压力会非常大。
4)适合数据的批量读写,吞吐量高,不适合做交互式应用,低延迟很难满足;
5)支持顺序读写,不支持此多用户并发写相同文件;
第五节,HDFS的使用
这里讲师使用了几个hadoop的几个常用命令来演示如何在hadoop中创建一个目录,然后上传一个文件,然后再下载一个文件。
大致都是:
hadoop fs -put filea.dat input/
或者是get命令下载文件
或者是cat命令查看文件内容
或者是hdfsadmin命令来查看整个系统的一些统计信息。
第四章,Hadoop的核心,MapReduce的原理与实现
第一节,MapReduce的原理
其实这个和Java8最新引入流操作中的并行操作类似,概念也都是想同的。
所谓Map就是要将任务拆分成很多份,这里给了一个例子,有1000副牌,少了一张,然后要找出到底是少了哪一章。

然后又给了一个从日志中统计出访问此处最多的ip的例子,也都是类似的,先把日志分块,然后由不同的任务分别统计,然后再把他们的结果拿来合并,也就是Reduce了
第二节,MapReduce的运行流程
几个基本的概念:
#,Job&Task,比如上面的找出访问次数最多的任务就是一个Job,然后这个Job要完成的话要被分解为多个Task,放到不同的节点上去执行。Task又可以分为MapTask和ReduceTask
#,JobTracker,作业调度,分配任务并监控任务的执行进度,任务分配出去之后,TaskTracker每隔几秒钟要向JobTracker更新状态
#,TaskTracker,作业的执行
这几个概念互相之间的关系如下图:

一般来说,TaskTracker就是分配在其数据所在的DataNode上,这样可以保证运行的效率最高,毕竟读取本机的磁盘总是更快的。这也是MapReduce的一个设计思想,用移动计算来避免移动数据。 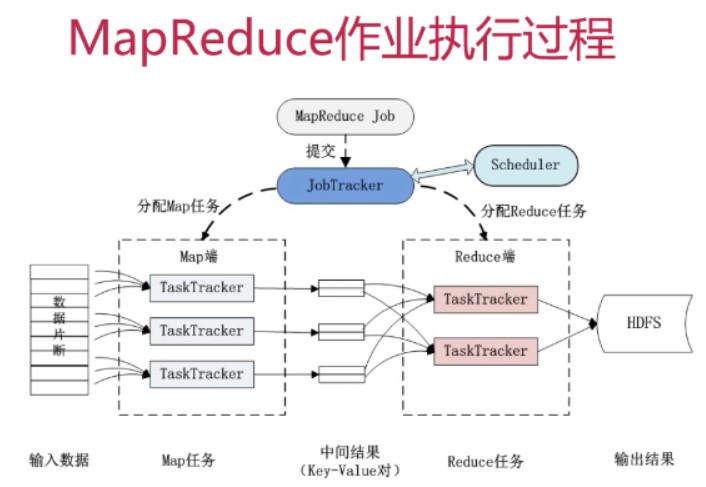
MapReduce的容错机制,
1)重复执行;也就是执行的过程中如果出错了,他会重复执行,但是重复了4次之后如果还出错,他就放弃了。
2)推测执行,用于解决那种计算速度特别慢的情况,此时会新开一个任务,然后再看这两个任务谁先执行完。