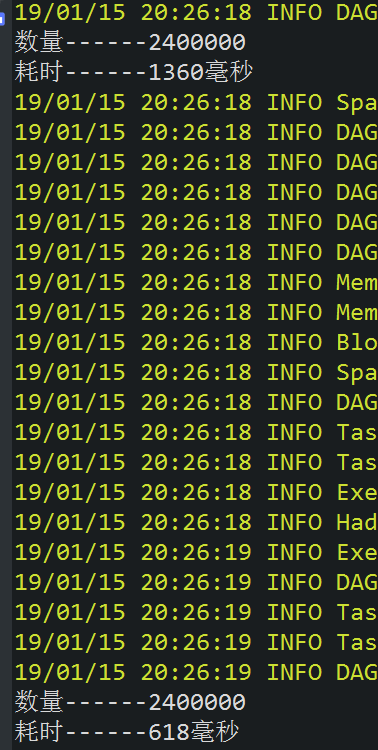
未使用rdd持久化
使用后
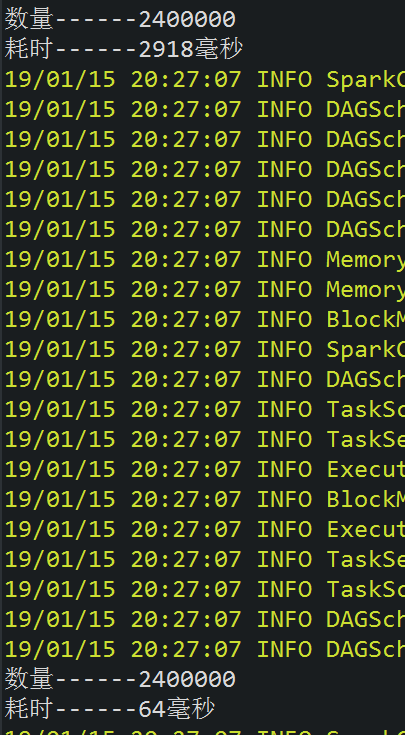
通过对比可以发现,未使用RDD持久化时,第一次计算比使用RDD持久化要快,但之后的计算显然要慢的多,差不多10倍的样子
代码
1 public class PersistRDD {
2 private static SparkConf conf = new SparkConf().setMaster("local").setAppName("persistrdd");
3 private static JavaSparkContext jsc = new JavaSparkContext(conf);
4 public static void main(String[] args) {
5 JavaRDD<String> rdd = jsc.textFile("D:\inputword\result.txt").cache();
6
7 long start = System.currentTimeMillis();
8 long count = rdd.count();
9 System.out.println("数量------" + count);
10 long end = System.currentTimeMillis();
11 System.out.println("耗时------" + (end-start) + "毫秒");
12
13
14 start = System.currentTimeMillis();
15 count = rdd.count();
16 System.out.println("数量------" + count);
17 end = System.currentTimeMillis();
18 System.out.println("耗时------" + (end-start) + "毫秒");
19
20 jsc.close();
21 }
22 }