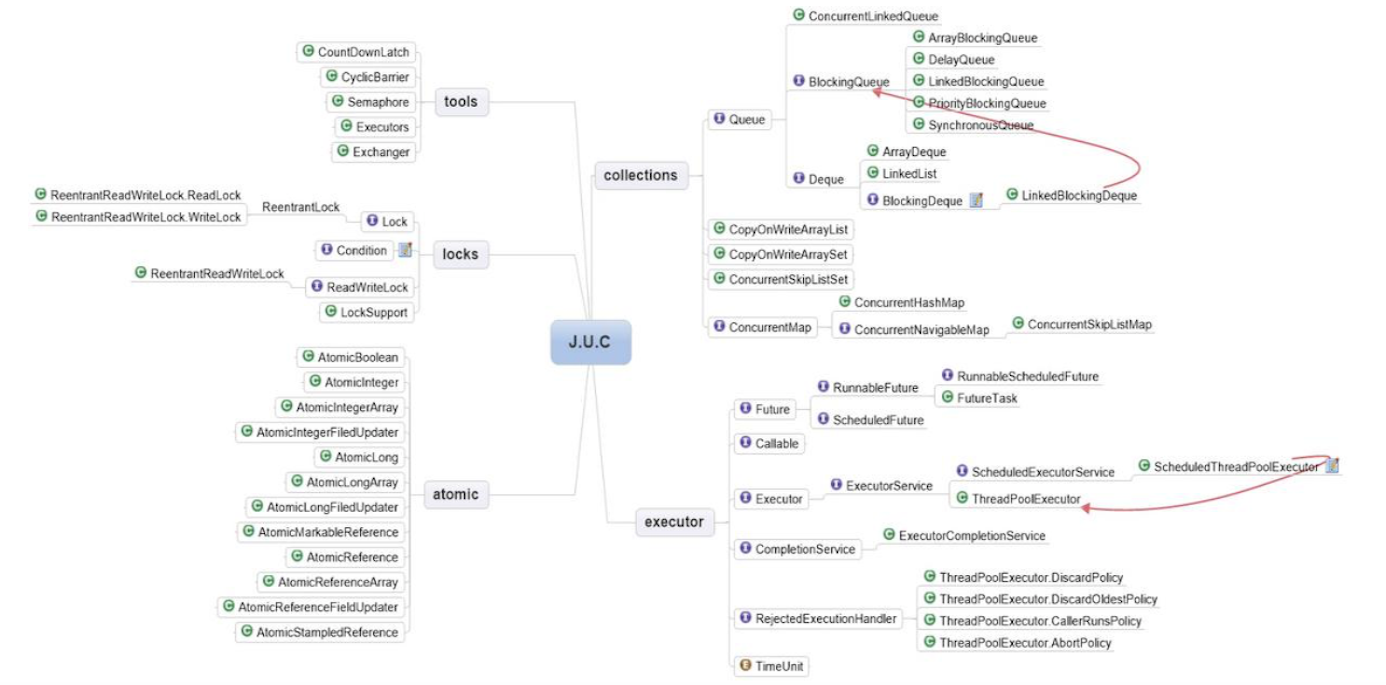
java.util.concurrent 包是在 Java5 时加入的,与 concurrent 的相关的有 JMM及 AbstractQueuedSynchronizer (AQS),两者是实现 concurrent 的基础,下面我们来看一下
1 JMM
JMM 是 Java Memory Model,围绕着并发过程中如何处理可见性、原子性、有序性这三个特征而建立的模型。
1.1 主内存和工作内存
JMM 中规定了所有变量都储存在主内存中,每条线程都有自己的工作内存(类似处理器的高速缓存),线程的工作内存中保存了所使用变量的副本(从主内存中拷贝的),线程对变量的所有操作(读取、赋值)都在工作内存中,而不能直接读写主内存的变量。不同线程间无法直接访问其工作内存中的变量,线程间变量值的传递需要在主内存中完成,如下图所示
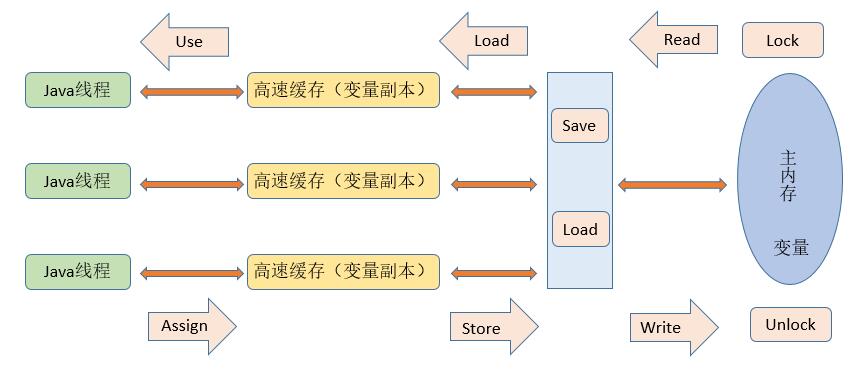
注:这里说的主内存、工作内存与 JVM 内存区域的Java堆、Java栈、方法区等不是同一层次的划分。
1.2 主内存和工作内存的交互
关于一个变量如何从主内存拷贝到工作内存、如何从工作内存拷贝到主内存,JMM 定义了8种操作来完成:
- lock (锁定):作用于主内存,把一个变量标志为一个线程独占,即锁定。
- unlock (解锁):作用于主内存,把一个锁定的变量释放出来。
- read (读取):作用于主内存,把一个变量值传入到线程的工作内存中。
- load (载入):作用于工作内存,把 read 到的值放入工作内存的副本中。
- use (使用):作用于工作内存,把工作内存的一个变量值传递给执行引擎(每当执行到需要变量的字节码指令)
- assign (赋值):作用于工作内存,把从执行引擎接收到的值赋给工作内存的变量中(每当执行到给变量赋值的字节码指令)
- store (存储):作用于工作内存,把工作内存的一个变量传递到主内存中。
- write (写入):作用于主内存,把 store 的值放入到主内存的变量中。
JMM要求lock、unlock、read、load、assign、use、store、write这8个操作都必须具有原子性,但对于64为的数据类型(long和double),具有非原子协定:允许虚拟机将没有被volatile修饰的64位数据的读写操作划分为2次32位操作进行。与此类似的是,在栈帧结构的局部变量表中,long和double类型的局部变量可以使用2个能存储32位变量的变量槽(Variable Slot)来存储。
如果多个线程共享一个没有声明为volatile的long或double变量,并且同时读取和修改,某些线程可能会读取到一个既非原值,也不是其他线程修改值的代表了“半个变量”的数值。不过这种情况十分罕见。因为非原子协议换句话说,同样允许long和double的读写操作实现为原子操作,并且目前绝大多数的虚拟机都是这样做的。
1.3 原子性、可见性、有序性
- 原子性:JMM 保证的原子性变量操作包括 read、load、assign、use、store、write,而 long、double 非原子协定导致的非原子性操作基本可以忽略。如果需要对更大范围的代码实行原子性操作,则需要 JMM 提供的 lock、unlock、synchronized 等来保证。
- 可见性:是指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。JMM在变量修改后将新值同步回主内存,在变量被线程读取前从内存刷新变量新值,保证变量的可见性。普通变量和 volatile 变量都是如此,只不过 volatile 的特殊规则保证了这种可见性是立即得知的,而普通变量并不具备这种严格的可见性。除了 volatile 外,synchronized 和 final 也能保证可见性。
- 有序性:如果在本线程内观察,所有的操作都是有序的;如果在一个线程中观察另一个线程,所有的操作都是无序的。前半句指“线程内表现为串行的语义”,后半句指“指令重排序”和普通变量的”工作内存与主内存同步延迟“的现象。
1.4 volatile 变量
volatile 是最轻量的同步机制,具有以下特性:
- 保证变量的可见性:读一个 volatile 变量时,总是能看到(任意线程)对这个变量的写入结果。
- 屏蔽指令重排序:指令重排序是编译器和处理器为了高效而对程序优化的手段。
并且要注意 volatile 只能保证变量的可见性和屏蔽指令重排序,并不能保证变量的原子性,对任意单个 volatile 变量的读/写是原子性的,但类似于i++、i--这种复合操作不具有原子性,因为自增运算包括读取i的值、i值增加1、重新赋值3步操作,并不具备原子性。只有满足下面2条时,才能使用 volatile 来保证并发的安全性,否则就要加锁(使用synchronized、lock 或 Atomic 原子类)来保证并发中的原子性。
- 对变量的写操作不依赖于当前值。运算结果不存在依赖数据(重排序的数据依赖性),或者只有单一的线程改修变量的值
- 该变量没有包含在具有其他变量的不变式中。变量不需要与其他的状态变量共同参与不变约束
为了能够良好的使用 volatile 变量,我们牢记:只有在状态独立于程序其他内容时才可以使用 volatile。下面是正确使用 volatile 的情况
1) 状态标志
当一个 boolean 变量作用仅仅是用于指示状态时,可以使用 volatile,如运行状态的开启或关闭等
volatile boolean shutdown; public void close() { shutdown = true; } public void do() { while (!shutdown) { // do thing... } }
上述情况 shutdown 只有一种从 false 到 true 的转换状态,也可以扩展到来回切换的状态,但是
2) 安全发布
在单例模式中我们遇到的双重校验锁的问题,即 instance = new Singleton() 这个操作时,可能当前线程申请到内存地址后会直接赋值给 instance 但还未进行 Singleton 的初始化,此时 instance 已经不为空,另一个线程判断 instance 不为空后会将其直接返回,而 Singleton 可能并未完成初始化,这是由于 Java 内存模型允许“无序写入”。实现安全发布就是将对象的引用定义为 volatile 类型。
public class Singleton { private volatile static Singleton instance; private Singleton() {}; public static Singleton getInstance() { if(instance == null) { synchronized (Singleton.class) { if(instance == null) { instance = new Singleton(); } } } return instance; } }
3) 独立观察
定期“发布”观察结果供程序内部使用,例如有一种温度感应器,后台线程每隔几秒读取一次改传感器,并更新 volatile 变量,其他线程读取这个变量时能看到最新温度。
另一种使用方式是作为统计信息的收集程序,下面程序展示了身份验证机制如何记忆最近一次登陆用户的名字,反复使用lastUser 引用来发布值,以供程序其他部分使用
public class UserManager { public volatile String lastUser; public boolean authenticate(String user, String password) { boolean valid = passwordIsValid(user, password); if (valid) { User u = new User(); activeUsers.add(u); lastUser = user; } return valid; } }
该方式要求被发布的值是有效不可变的,即值的状态在发布后不会更改。
4) volatile bean
即 JavaBean 的所有成员都是 volatile 的,且 get 和 set 方法要非常普通,不能包含除获取和设置属性之外的其他逻辑。此外对于引用类型的成员,引用的对象必须是有效且不可变的(所以数组不可以)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性
@ThreadSafe public class Person { private volatile String firstName; private volatile String lastName; private volatile int age; public String getFirstName() { return firstName; } public String getLastName() { return lastName; } public int getAge() { return age; } public void setFirstName(String firstName) { this.firstName = firstName; } public void setLastName(String lastName) { this.lastName = lastName; } public void setAge(int age) { this.age = age; } }
2 AQS
AbstractQueuedSynchronizer 是一个用于构建锁和同步容器,在 concurrent 包中很多类都是基于 AQS 构建的,如 ReetrantLock、ReetrantLockWriteLock、Semaphore、CountDownLatch、Futuretask 等。
AQS 中有一个表示状态的字段 volatile int state 和一个 FIFO 的队列表示排队等待锁的线程(多线程争用资源被阻塞时会进入此队列),队列的头节点称为“哨兵节点”或“哑节点”,它不与任何线程关联。其他的节点与等待线程关联,每个节点维护一个等待状态 waitStatus,如图
AQS 定义了两种资源共享方式:Exclusive(独占,只能一个线程执行,如 ReentrantLock)和 Share(共享,多个线程可以同时执行,如 Semaphore/CountDownLatch)。如果我们自已自定义同步器。只需要维护 state 变量即可(对 state 的更新都采用了 CAS 操作保证原子性),线程等待队列的维护(如获取资源失败入队、唤醒出队等)AQS 已经在顶层实现了。自定义同步器主要实现以下几种方法:
- isHeldExclusively():该线程是否正在独占资源
- tryAcquire(int):以独占方式,尝试获取资源,成功返回true,失败则返回false
- tryRelease(int):以独占方式,尝试释放资源,成功返回true,失败则返回false
- tryAcquireShared(int):以共享方式,尝试获取资源,返回剩余可用资源,负数表示失败
- tryReleaseShared(int):以共享方式,尝试释放资源,如果释放后允许唤醒后续等待节点返回true,否则返回flase
我们来看一下系统的自定义同步器
ReentrantLock:state 表示线程重入锁次数,初始为0,表示未锁定状态。当调用 lock() 方法时,会调用 tryAcquire() 方法独占该锁并将 state + 1,之后其他线程再调用 lock() 即 tryAcquire() 时就会失败,直到这个线程 unlock() 到 state为0时(即释放锁)为止。
CountDownLatch:任务划分为 n 个子线程执行,state 也初始化为 n,这些子线程是并行执行的,每个子线程执行后 countDown() 一次,state 会以 CAS 方式减1。等所有子线程执行完后,会使用 unpark() 调用主线程,然后主线程就会从 await() 方法返回,继续执行后续动作。
3 CAS(Compare and Swap, 比较并交换)
java.util.cuncurrent 包完全建立在 CAS 之上,没有 CAS 就不会有这个包。CAS 是通过 C 语言来调用 CPU 底层指令实现的。在 CAS 有3个操作数,内存值V、预期值A(即旧值)、新值B,当且仅当预期值A和内存值V相同时,才将内存值改为B,否则什么也不做。
CAS 的目的是提升性能,利用 CPU 的 CAS 执行与 JNI 可以完成 Java 的非阻塞算法,对于 synchronized 的阻塞算法,在性能上有很大的提升。
CAS 虽然很高效的解决了原子操作,但仍存在三大问题:ABA问题、循环事件长开销大和只能保证一个共享变量的原子操作。
1) ABA问题。因为 CAS 需要在操作值的时候检查下值是否已经变化,没有变化才更新。但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS检查的时候就会发现它的值没有发生变化,但实际上缺变化了。解决思路就是使用版本号,在变量前追加上版本号。在 atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题,这个类的 compareAndSet 方法作用是首先检查当前引用是否等于预期,并且当前标志是否是预期标志,如果全部相等,则以原子方式将该引用和标志更新。
2) 循环时间长开销大。自旋 CAS 如果长时间不成功,会给 CPU 带来很大的开销。
3) 只能保证一个共享变量的原子操作。当一个共享变量操作时,我们可以使用循环 CAS 的方式保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候需要用锁。有个取巧的办法是把多个共享变量合并成一个共享变量来操作,比如 i=2,j=a 合并成 ij=2a,然后再用 CAS 操作。在 atomic 包里提供了 AtomicReference 类来保证引用对象间的原子性,可以把多个变量放在一个对象里进行 CAS 操作。
由于java的CAS同时具有 volatile 读和volatile写的内存语义,因此Java线程之间的通信现在有了下面四种方式:
- A线程写volatile变量,随后B线程读这个volatile变量。
- A线程写volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
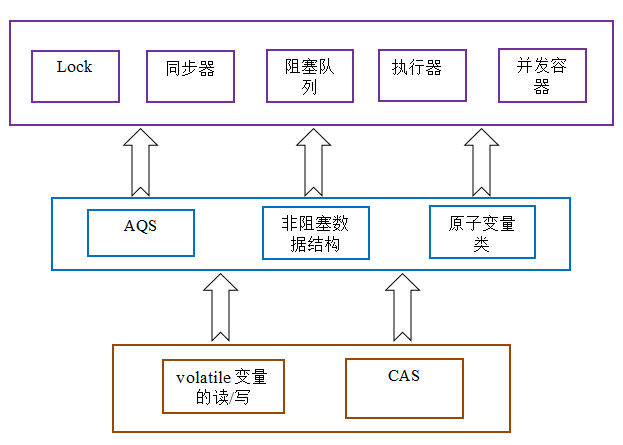
Java的CAS会使用现代处理器上提供的高效机器级别原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键(从本质上来说,能够支持原子性读-改-写指令的计算机器,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会去支持某种能对内存执行原子性读-改-写操作的原子指令)。同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式:
- 首先,声明共享变量为volatile;
- 然后,使用CAS的原子条件更新来实现线程之间的同步;
- 同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。从整体来看,concurrent包的实现示意图如下:
一、locks
java.util.concurrent.locks 包下提供的一种同步方式,主要用来解决 synchronized 的缺陷。
举个例子,如果一个代码块被 synchronized 修饰,当一个线程获取到锁后,其他线程只能一直等待,直到锁被释放,有两种情况锁会被释放:1 获取锁的线程执行完该代码块;2 获取锁的线程执行发生了异常,JVM 会让线程释放锁。如果获取这个锁的线程被 IO 或其他原因阻塞了,但又没有释放锁,那其他线程只能等待。因此就要有一种机制可以不让线程一直占有锁(比如只等待一定的时间或能够响应中断),而通过 Lock 就可以做到。
再举个例子,如果有多个线程读写文件时,读操作和写操作会发生冲突、写操作和写操作会发生冲突,但读操作和读操作不会发生冲突。当采用 synchronized 来实现同步的话,就会导致一个问题:如果多个线程都是只读操作,当一个线程在进行读操作时其他线程只能等待。而使用 Lock 可以解决这个问题。
关于 Lock 与 synchronized 有以下几点不同:
- Lock 是一个类(接口),而 synchronized 是 java 的关键字。
- 使用 Lock 需要用户手动释放锁,如果没有主动释放,可能会导致死锁。
- Lock 可以让等待锁的线程响应中断,而 synchronized 不可以,会让线程一直等待下去。
- 通过 Lock 可以知道线程有没有获取到锁,这个 synchronized 无法做到。
- 使用 Lock 可以提高多个线程进行读操作的效率。
- 当资源竞争不激烈时,Lock 与 synchronized 性能相似,而竞争激烈时,Lock 要更优一些。
下面我们来讨论下 java.util.concurrent.locks 包中常用的类和接口
1 Lock
Lock 是一个接口,其方法如下:
- void lock(); // 获取锁,如果锁已被占用则等待
- void lockInterruptibly() throws InterruptedException; // 获取锁,如果锁已被占用,则中断线程
- boolean tryLock(); // 无论是否得到锁都会立刻返回,获取锁成功返回true,失败返回false
- boolean tryLock(long, TimeUnit) throws InterruptedException; // 类似 tryLock() 但会等待一定时间
- void unlock();
- Condition newCondition();
ReentrantLock 是可重入锁,唯一实现了 Lock 接口的类。
2 ReadWriteLock
ReadWriteLock 是一个接口,将读写进行了分离,它里面只有两个方法:
- Lock readLock(); // 获取读锁
- Lock writeLock(); // 获取写锁
ReentrantReadWriteLock 实现了 ReadWriteLock 接口。
注:锁的分类:
- 公平锁/非公平锁:是指是否按照线程申请锁的顺序来获取锁,非公平锁可能导致优先级反转或饥饿现象。
- 可重入锁:又名递归锁,如果外层方法获取了锁,那么进入内层方法时会自动获取锁。
- 独享锁/共享锁:指该锁一次能被一个线程或者多个线程持有。
- 互斥锁/读写锁:是独享锁/共享锁的具体实现。
- 乐观锁/悲观锁:悲观锁认为数据一定发生修改,不加锁的并发一定会出问题,乐观锁则相反。
- 分段锁:是一种锁的设计,如 concurrentHashMap
- 偏向锁/轻量级锁/重量级锁
- 自旋锁:自选锁指尝试获取锁的线程不会立即阻塞,而是采用循环的方式尝试获取锁。
二、atomic
java.util.concurrent.atomic 包可以方便在多线程环境下,无锁的进行原子性操作。在 atomic 包中一共有 12 个类,四种原子更新方式,分别是:原子更新基本类型、原子更新数组、原子更新引用和原子更新字段。基本上都是通过 Unsafe 实现的。
1 原子更新基本类型
通过原子方式更新基本类型,有三个类:AtomicInteger、AtomicLong、AtomicBoolean。
1.1 AtomicInteger 类
- int get()
- void set(int newValue)
- void lazySet(int newValue) //
- int getAndSet(int newValue) // 更新,并返回旧值
- int getAndAdd(int delta) // 相加,并返回旧值
- int addAndGet(int delta) // 相加,并返回新值
- boolean compareAndSet(int expect, int update) // 如果输入值等于预期,则更新
- boolean weakCompareAndSet(int expect, int update) //
- int getAndIncrement() // 类似于 i++,返回旧值
- int getAndDecrement() // 类似于 i--,返回旧值
- int incrementAndGet() // 类似 ++i,返回新值
- int decrementAndGet() // 类似 --i,返回新值
- int getAndUpdate(IntUnaryOperator updateFunction) // 使用给定函数的结果更新值,返回旧值
- int updateAndGet(IntUnaryOperator updateFunction) // 使用给定函数的结果更新值,返回新值
- int getAndAccumulate(int, IntBinaryOperator) // 使用给定函数计算当前值与给定值,返回旧值
- int accumulateAndGet(int, IntBinaryOperator) // 使用给定函数计算当前值与给定值,返回新值
1.2 AtomicLong 类
AtomicLong 与 AtomicInteger 类似,就不再列出具体方法。
1.3 AtomicBoolean 类
AtomicBoolean 是将 boolean 当作整型的 0 1 去操作的,与 AtomicInteger 方法类似。
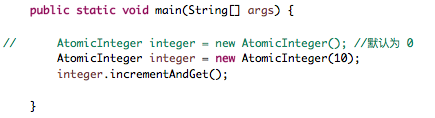
注:使用以上原子更新基本类型,只需要创建其对象并传入初始值即可使用
2 原子更新字段
原子更新字段类都是抽象类,每次使用都时候必须使用静态方法 newUpdater 创建一个更新器。原子更新类的字段的必须使用public volatile修饰符
2.1 AtomicIntegerFieldUpdater 类
AtomicIntegerFieldUpdater 用于更新整型字段,部分方法如下
- boolean compareAndSet(T obj, int expect, int update)
- boolean weakCompareAndSet(T obj, int expect, int update)
- void set(T obj, int newValue)
- void lazySet(T obj, int newValue)
- int get(T obj)
- int getAndSet(T obj, int newValue)
- int getAndAdd(T obj, int delta)
- int addAndGet(T obj, int delta)
- int getAndIncrement(T obj)
- int getAndDecrement(T obj)
- int incrementAndGet(T obj)
- int decrementAndGet(T obj)
- int getAndUpdate(T obj, IntUnaryOperator updateFunction)
- int updateAndGet(T obj, IntUnaryOperator updateFunction)
- int getAndAccumulate(T obj, int x, IntBinaryOperator accumulatorFunction)
- int accumulateAndGet(T obj, int x, IntBinaryOperator accumulatorFunction)
2.2 AtomicLongFieldUpdater 类
AtomicLongFieldUpdater 用于更新长整型字段,这里就不再列出具体方法
2.3 AtomicStampedReference 类
3 原子更新引用
3.1 AtomicReference 类
AtomicReference 是用于原子更新引用类型,部分方法如下(V 指引用对象类型)
- V get()
- void set(V newValue)
- void lazySet(V newValue)
- boolean compareAndSet(V expect, V update) // 输入值符合预期,则更新
- boolean weakCompareAndSet(V expect, V update) // 同上
- V getAndSet(V newValue) // 更新,返回旧值
- V getAndUpdate(UnaryOperator<V> updateFunction) // 使用给定函数的结果更新值,返回旧值
- V updateAndGet(UnaryOperator<V> updateFunction) // 使用给定函数的结果更新值,返回新值
- V getAndAccumulate(V x, BinaryOperator<V> accumulatorFunction) // 使用给定函数计算当前值与给定值,返回旧值
- V accumulateAndGet(V x, BinaryOperator<V> accumulatorFunction) // 使用给定函数计算当前值与给定值,返回新值
3.2 AtomicReferenceFieldUpdater 类
AtomicReferenceFieldUpdater 用于更新引用类型里的字段,部分方法如下(T 指引用对象类型,V 指字段类型)
- boolean compareAndSet(T obj, V expect, V update)
- boolean weakCompareAndSet(T obj, V expect, V update)
- void set(T obj, V newValue)
- void lazySet(T obj, V newValue)
- V get(T obj)
- V getAndSet(T obj, V newValue)
- V getAndUpdate(T obj, UnaryOperator<V> updateFunction)
- V updateAndGet(T obj, UnaryOperator<V> updateFunction)
- V getAndAccumulate(T obj, V x, BinaryOperator<V> accumulatorFunction)
- V accumulateAndGet(T obj, V x, BinaryOperator<V> accumulatorFunction)
3.3 AtomicMarkableReference 类
AtomicMarkableReference 用于原子更新带有标记位的引用类型,部分方法如下
- V getReference()
- V get(boolean[] markHolder)
- void set(V newReference, boolean newMark)
- boolean isMarked()
- boolean compareAndSet(V expectedReference, V newReference, boolean expectedMark, boolean newMark)
- boolean weakCompareAndSet(V expectedReference, V newReference, boolean expectedMark, boolean newMark)
- boolean attemptMark(V expectedReference, boolean newMark)
注:使用以上原子更新引用大致使用方法如下

4 原子更新数组
4.1 AtomicIntegerArray 类
- int length()
- int get(int i)
- void set(int i, int newValue)
- void lazySet(int i, int newValue)
- int getAndSet(int i, int newValue) // 设置第 i 个元素,返回原值
- int getAndAdd(int i, int delta) // 将第 i 个元素加上指定参数,并返回旧值
- int addAndGet(int i, int delta) // 将第 i 个元素加上指定参数,并返回新值
- boolean compareAndSet(int i, int expect, int update) // 如果输入值符合预期,则更新
- boolean weakCompareAndSet(int i, int expect, int update) // 同上
- int getAndIncrement(int i) // 操作第 i 个元素,类似于 i++,返回旧值
- int getAndDecrement(int i) // 操作第 i 个元素,类似于 i--,返回旧值
- int incrementAndGet(int i) // 操作第 i 个元素,类似于 ++i,返回新值
- int decrementAndGet(int i) // 操作第 i 个元素,类似于 --i,返回新值
- int getAndUpdate(int i, IntUnaryOperator updateFunction)
- int updateAndGet(int i, IntUnaryOperator updateFunction)
- int getAndAccumulate(int i, int x, IntBinaryOperator accumulatorFunction)
- int accumulateAndGet(int i, int x, IntBinaryOperator accumulatorFunction)
4.2 AtomicLongArray 类
AtomicLongArray 与 AtomicIntegerArray 类似,就不再列出具体方法。
4.3 AtomicReferenceArray 类
AtomicReferenceArray 与 AtomicIntegerArray 类似。
三、executor
1 Executor
Executor 基于生产者-消费者模式,其提交的任务线程相当于生产者,执行任务的线程相当于消费者,并用 Runnable 来表示任务
首先在 Executor 接口,里面只有一个方法 void execute(Runnable command) ,我们继续来看一下它的继承和实现。
1.1 ExecutorService
ExecutorService 接口继承自 Executor,提供了生命周期管理的方法,以及可跟踪一个或多个异步任务执行状况并返回 Future 的方法,其方法如下
- void shutdown(); //启动关闭命令,不再接受新任务,当所有已提交任务执行完后关闭
- List<Runnable> shutdownNow(); // 试图停止所有正在执行的任务,返回正在等待的任务
- boolean isShutdown();
- boolean isTerminated(); // 如果关闭后所有任务都已完成,则返回 true。注意,除非首先调用 shutdown 或 shutdownNow,否则 isTerminated 永不为 true
- boolean awaitTermination(long timeout, TimeUnit unit); // 等待关闭(true)、超时(falise)或发生中断(异常)
- Future<T> submit(Callable<T> task);
- Future<?> submit(Runnable task); // 提交 Runnable 执行,返回表示该任务的 Future,Future 的 get 方法在成功完成时返回 null
- Future<T> submit(Runnable task, T result); // 同上,不过要将结果返回给 result
- List<Future<T>> invokeAll(Collection tasks); // 执行给定任务,当所有任务完成,返回 Future 列表
- List<Future<T>> invokeAll(Collection tasks, long timeout, TimeUnit unit) // 同上,弱超时
- T invokeAny(Collection tasks);
- T invokeAny(Collection tasks, long timeout, TimeUnit unit);
1.2 ThreadPoolExecutor
ThreadPoolExecutor 类继承自 AbstractExecutorService 抽象类,是线程池,可以通过调用 Executors 下的静态工厂方法来创建线程池并返回一个 ExecutorService 对象。
在 ThreadPoolExecutor 的构造方法中一共有 7 个参数,我们来看一下
- int corePoolSize // 线程池中线程数
- int maximumPoolSize // 线程池允许的最大线程数
- long keepAliveTime // 当线程数大于核心时,如果一个线程的空闲时间超过keepAliveTime则终止。线程数不大于核心时,如果调用allowCoreThreadTimeOut(boolean)方法,keepAliveTime也会起作用,直到线程数为0。
- TimeUnit unit // keepAliveTime 参数的时间单位
- BlockingQueue<Runnable> workQueue // 阻塞队列,储存等待执行的任务
- ThreadFactory threadFactory // 创建线程时使用的工厂
- RejectedExecutionHandler handler // 超出线程范围和队列容量时使得执行被阻塞时,采取的措施,有四种策略:AbortPolicy(丢弃任务并抛出异常)、DiscardPolicy(丢弃任务但不抛异常)、DiscardOldestPolicy(丢弃队列最前面的,然后重复此过程)、CallerRunsPolicy(调用线程处理该任务)
我们来看一下 ThreadPoolExecutor 类中的方法
- public void execute(Runnable command) // 执行给定的任务
- public void shutdown()
- public List<Runnable> shutdownNow()
- public boolean isShutdown()
- public boolean isTerminating()
- public boolean isTerminated()
- public boolean awaitTermination(long timeout, TimeUnit unit)
- public void setThreadFactory(ThreadFactory threadFactory)
- public ThreadFactory getThreadFactory()
- public void setRejectedExecutionHandler(RejectedExecutionHandler handler)
- public RejectedExecutionHandler getRejectedExecutionHandler()
- public void setCorePoolSize(int corePoolSize)
- public int getCorePoolSize()
- public boolean prestartCoreThread()
- public int prestartAllCoreThreads() // 启动所有核心线程,使其处于等待工作的空闲状态,返回启动数量
- public boolean allowsCoreThreadTimeOut()
- public void allowCoreThreadTimeOut(boolean value)
- public void setMaximumPoolSize(int maximumPoolSize)
- public int getMaximumPoolSize()
- public void setKeepAliveTime(long time, TimeUnit unit)
- public long getKeepAliveTime(TimeUnit unit)
- public BlockingQueue<Runnable> getQueue()
- public boolean remove(Runnable task)
- public void purge()
- public int getPoolSize()
- public int getActiveCount()
- public int getLargestPoolSize()
- public long getTaskCount()
- public long getCompletedTaskCount()
1.3 ScheduledExecutorService
ScheduledExecutorService 是一个接口,继承自 ExecutorService,增加了四个方法,其中 command 是执行线程、initialDelay 是初始化延时、period 是两次开始执行最小时间间隔、unit 是计时单位。
- schedule(Runnable command, long delay, TimeUnit unit);
- schedule(Callable<V> callable, long delay, TimeUnit unit);
- scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit); // 从上个任务执行开始计算下次任务时间
- scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit); // 从上个任务执行结束计算下次任务时间
1.4 ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 类实现了 ScheduledExecutorService 接口,以下是其增加的方法
- void execute(Runnable command) // 立即执行 command 任务
- Future<?> submit(Runnable task)
- Future<T> submit(Runnable task, T result)
- Future<T> submit(Callable<T> task)
- void setContinueExistingPeriodicTasksAfterShutdownPolicy(boolean value) // 关闭了也继续执行周期任务
- void setExecuteExistingDelayedTasksAfterShutdownPolicy(boolean value)
- void setRemoveOnCancelPolicy(boolean value)
- boolean getContinueExistingPeriodicTasksAfterShutdownPolicy()
- boolean getExecuteExistingDelayedTasksAfterShutdownPolicy()
- boolean getRemoveOnCancelPolicy()
- void shutdown()
- List<Runnable> shutdownNow()
- BlockingQueue<Runnable> getQueue()
四、Collections
1 ConcurrentHashMap
首先我们知道 HashMap 是线程不安全的,而 Hashtable 是线程安全的,但是它实现线程安全的方式是在方法上加入 synchronized 锁住整张 hash 表,效率比较低。那么 ConcurrentHashMap 是如何做到线程安全的呢?ConcurrentHashMap 在 Java7 和 Java8 的实现方式不同,我们来分别看一下它的实现方式:
1) Java 7
在 Java7 中采用 Segment + HashEntry 的方式进行实现,每个 Segment 就相当于一个 HashTable,其结构如下
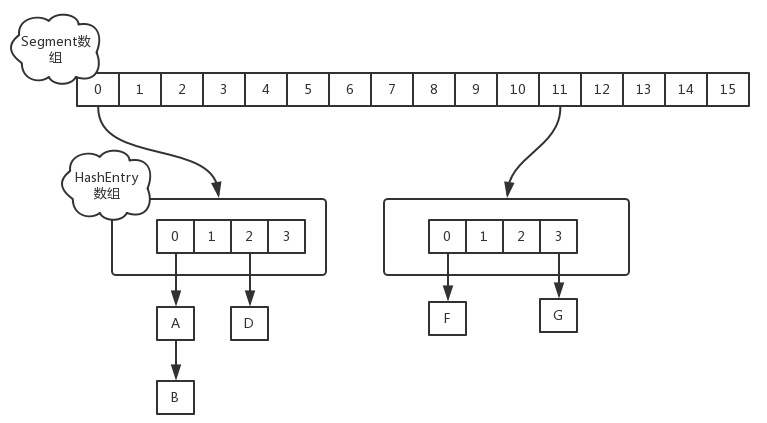
当执行 put 方法放入元素时,会先根据 key 的哈希值,在 Segment 数组中找到相应的位置。如果 Seqment 还未初始化,则通过 CAS 方式初始化赋值,然后执行 Segment 的 put 方法通过加锁机制插入元素。假设两个线程同时向一个 Segment 中插入对象,其中一个线程使用 tryLock() 方法获取到锁,另一个线程获取锁失败时会重复执行 tryLock() 方法尝试获取锁,当超过一定次数后(单处理器为1次,多处理器64次),会执行 lock() 方法去尝试获取。
2) Java8
在 Java8 中放弃了 Segment 臃肿的设计,采取 Node + CAS + synchronized 来保证并发安全,其结构如下
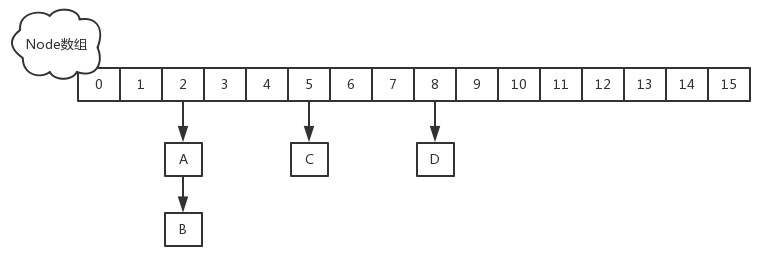
当执行 put 方法放入元素时,会先根据 key 的哈希值,在 Node 数组中找到相应的位置。如果 Node 还未初始化,则通过 CAS 方式初始化赋值;如果 Node 不为空,且当前节点不处于移动状态,则对该节点加 synchronized 锁,然后遍历链表放入元素,具体实现如下
public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 如果 Node 数组,即哈希表为空,则先进行初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); // 根据哈希值找到要插入位置的头节点 // 如果头节点为空,则以 CAS 方式创建一个新节点并将元素放入 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; } // 如果头节点的哈希值等于 MOVED else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); // 如果头节点不为空时 else { V oldVal = null; // 将头节点加锁 synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } // 如果这个链表是红黑树结构 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }
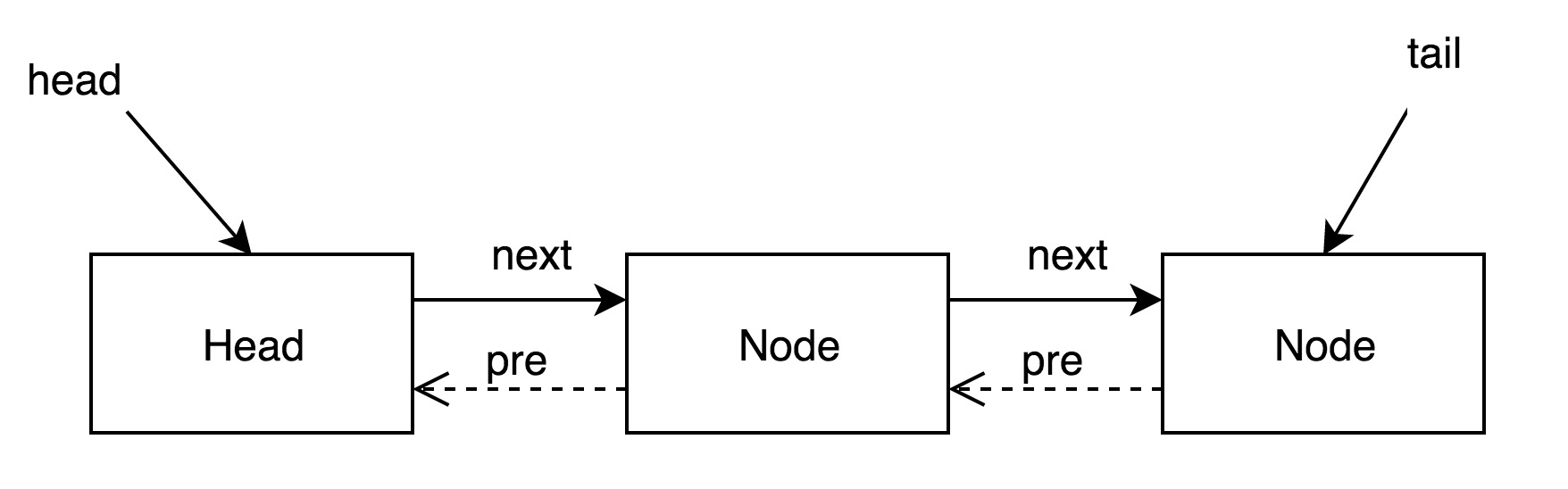
2 ConcurrentSkipList
ConcurrentSkipList 称为跳表,跳表是一种以“空间换取时间”的算法,它是一个有序的链表,其结构大致如下图所示

3 ConcurrentLinkedQueue
ConcurrentLinkedQueue 的实现是依靠 CAS 算法。我们来看一下它的入队与出队:
入队:
public boolean add(E e) { return offer(e); } public boolean offer(E e) { checkNotNull(e); // 入队前,创建一个入队节点 final Node<E> newNode = new Node<E>(e); // 死循环,入队不成功反复输入,初始一个指向tail节点的引用 for (Node<E> t = tail, p = t;;) { // 获取下一个节点 Node<E> q = p.next; // p是最后一个节点 if (q == null) { if (p.casNext(null, newNode)) { if (p != t) // hop two nodes at a time casTail(t, newNode); // Failure is OK. return true; } // Lost CAS race to another thread; re-read next } else if (p == q) p = (t != (t = tail)) ? t : head; else // Check for tail updates after two hops. p = (p != t && t != (t = tail)) ? t : q; } }
出队:
4 ConcurrentLinkedDeque
5 BlockingQueue
如果 BlockQueue 是空的,从 BlockingQueue 取东西的操作将会被阻断进入等待状态,直到 BlockingQueue 进了东西才会被唤醒。同样,如果 BlockingQueue 是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到 BlockingQueue 里有空间才会被唤醒继续操作。
BlockingQueue有四个具体的实现类,根据不同需求,选择不同的实现类
- ArrayBlockingQueue:规定大小的 BlockingQueue,其构造函数必须带一个int参数来指明其大小,其所含的对象是以 FIFO(先入先出)顺序排序的。
- LinkedBlockingQueue:大小不定的 BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue 有大小限制,若不带大小参数,所生成的 BlockingQueue 的大小由Integer.MAX_VALUE来决定,其所含的对象是以 FIFO(先入先出)顺序排序的 。
- PriorityBlockingQueue:类似于 LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序。
- SynchronousQueue:特殊的 BlockingQueue,对其的操作必须是放和取交替完成的.