Mapreduce实例——Map端join
实验步骤
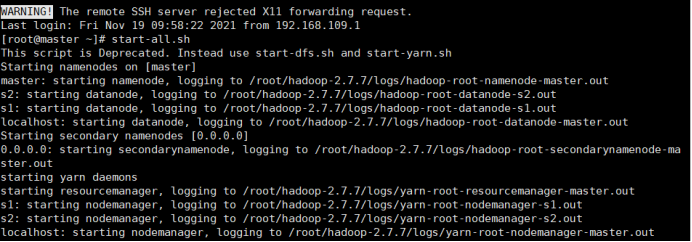
1.开启Hadoop
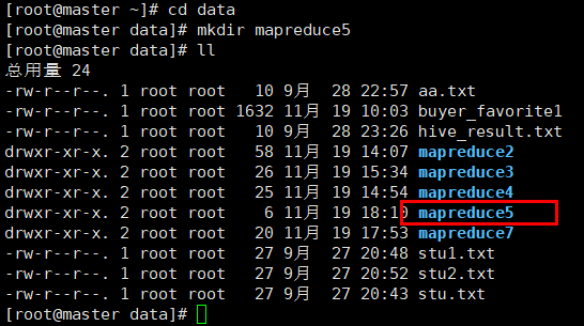
2.新建mapreduce5目录
在Linux本地新建/data/mapreduce5目录
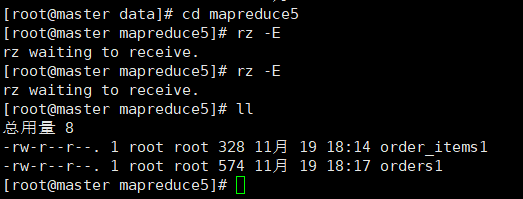
3. 上传文件到linux中
(自行生成文本文件,放到个人指定文件夹下)
orders1
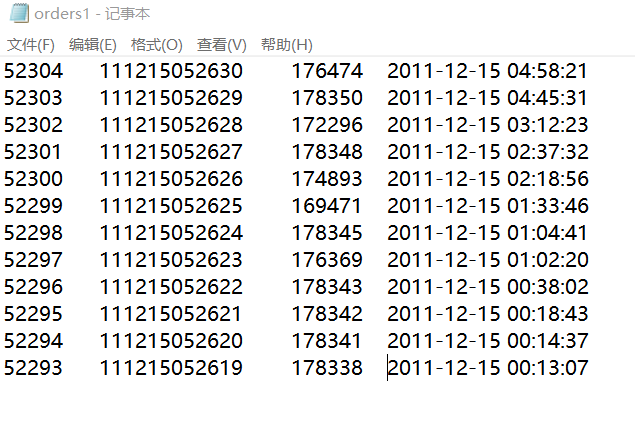
52304 111215052630 176474 2011-12-15 04:58:21
52303 111215052629 178350 2011-12-15 04:45:31
52302 111215052628 172296 2011-12-15 03:12:23
52301 111215052627 178348 2011-12-15 02:37:32
52300 111215052626 174893 2011-12-15 02:18:56
52299 111215052625 169471 2011-12-15 01:33:46
52298 111215052624 178345 2011-12-15 01:04:41
52297 111215052623 176369 2011-12-15 01:02:20
52296 111215052622 178343 2011-12-15 00:38:02
52295 111215052621 178342 2011-12-15 00:18:43
52294 111215052620 178341 2011-12-15 00:14:37
52293 111215052619 178338 2011-12-15 00:13:07
order_items1

252578 52293 1016840
252579 52293 1014040
252580 52294 1014200
252581 52294 1001012
252582 52294 1022245
252583 52294 1014724
252584 52294 1010731
252586 52295 1023399
252587 52295 1016840
252592 52296 1021134
252593 52296 1021133
252585 52295 1021840
252588 52295 1014040
252589 52296 1014040
252590 52296 1019043
4.在HDFS中新建目录
首先在HDFS上新建/mymapreduce5/in目录,然后将Linux本地/data/mapreduce5目录下的orders1和order_items1文件导入到HDFS的/mymapreduce5/in目录中。
hadoop fs -mkdir -p /mymapreduce5/in
hadoop fs -put /root/data/mapreduce5/orders1 /mymapreduce5/in
hadoop fs -put /root/data/mapreduce5/order_items1 /mymapreduce5/in

5.新建Java Project项目
新建Java Project项目,项目名为mapreduce。
在mapreduce项目下新建包,包名为mapreduce5。
在mapreduce5包下新建类,类名为MapJoin。
6.添加项目所需依赖的jar包
右键项目,新建一个文件夹,命名为:hadoop2lib,用于存放项目所需的jar包。
将/data/mapreduce2目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce2项目的hadoop2lib目录下。
hadoop2lib为自己从网上下载的,并不是通过实验教程里的命令下载的
选中所有项目hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码
MapJoin.java
package mapreduce5; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.util.HashMap; import java.util.Map; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MapJoin { public static class MyMapper extends Mapper<Object, Text, Text, Text>{ private Map<String, String> dict = new HashMap<>(); @Override protected void setup(Context context) throws IOException, InterruptedException { String fileName = context.getLocalCacheFiles()[0].getName(); //System.out.println(fileName); BufferedReader reader = new BufferedReader(new FileReader("E:\\kejian\\大三\\王建民\\课堂测试\\Mapreduce实验\\"+fileName)); String codeandname = null; while (null != ( codeandname = reader.readLine() ) ) { String str[]=codeandname.split("\t"); dict.put(str[0], str[2]+"\t"+str[3]); } reader.close(); } @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] kv = value.toString().split("\t"); if (dict.containsKey(kv[1])) { context.write(new Text(kv[1]), new Text(dict.get(kv[1])+"\t"+kv[2])); } } } public static class MyReducer extends Reducer<Text, Text, Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { for (Text text : values) { context.write(key, text); } } } public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException, URISyntaxException { Job job = Job.getInstance(); job.setJobName("mapjoin"); job.setJarByClass(MapJoin.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); Path in = new Path("hdfs://192.168.109.10:9000/mymapreduce5/in/order_items1"); Path out = new Path("hdfs://192.168.109.10:9000/mymapreduce5/out"); FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); URI uri = new URI("hdfs://192.168.109.10:9000/mymapreduce5/in/orders1"); job.addCacheFile(uri); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
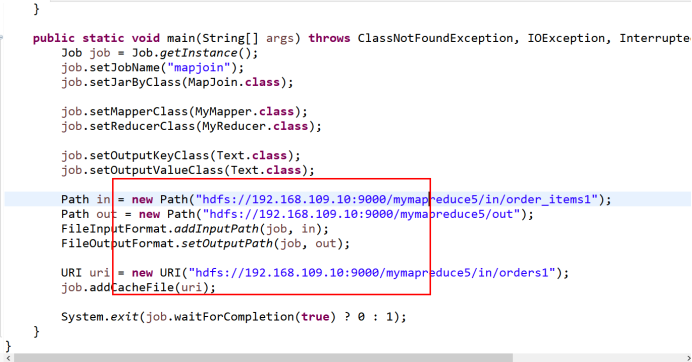
本次实验除了修改主机地址外,还需注意修改下图的代码
添加的部分为你文件的路径

8.运行代码
在MapJoin类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
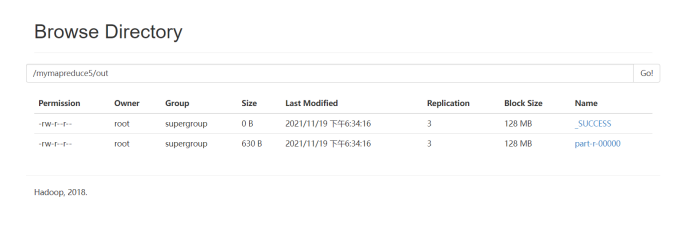
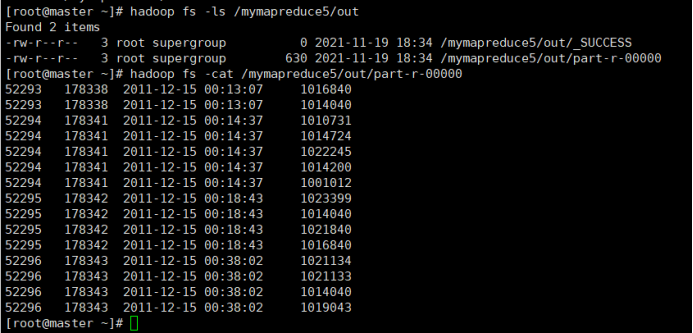
9.查看实验结果
待执行完毕后,进入命令模式下,在HDFS中/mymapreduce5/out查看实验结果。
hadoop fs -ls /mymapreduce5/out
hadoop fs -cat /mymapreduce5/out/part-r-00000
图一为我的运行结果,图二为实验结果
经过对比,发现结果一样

此处为浏览器截图