###基础概念
GBDT(Gradient Boosting Decision Tree) 全称梯度提升决策树,是一种迭代的决策树算法。GBDT是集成学习Boosting的家族成员,GBDT中的树是回归树,用于回归预测,调整后也可以用于分类。
####分类树与回归树的差异
分类树大致的实现过程是:穷举每一个属性特征的信息增益值,每一次都选取使信息增益最大(或信息增益比,基尼系数等)的特征进行分枝,直到分类完成或达到预设的终止条件,实现决策树的递归构建。
回归树的实现过程与分类树大体类似,在划分标准上回归树使用最小化均方差(x-x1)2/n+(x-x2)2/n+...+(x-xn)2/n,而不是使用信息增益等指标。同时回归树的预测值是数值型。
关于决策树原理可查看我之前的文章:决策树算法
####Gradient Boosting: Gradient Boosting是一种Boosting的方法,它主要的思想是沿着梯度方向,构造一系列的弱分类器函数,并以一定权重组合起来,形成最终决策的强分类器。
具体的实现方式是:
下一个分类器是在前一个分类器得到的残差基础上进行进一步分类,采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差(残差 = 真实值 - 预测值 ),拟合得到一个当前的残差回归树。它是一种串行的分类器集合方法。
####梯度下降: 梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一。 在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
同样的,GBDT的核心也是让损失函数沿着梯度方向下降。
迭代过程:
结合Gradient Boosting和梯度下降两个概念,说明GBDT的迭代过程:
针对数据集:T={(x1,y1),(x2,y2),⋅⋅⋅,(xN,yN)},xi∈χ=Rn,yi∈γ={−1,+1}, i=1,2,⋅⋅⋅,N
- 初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树,初始化:
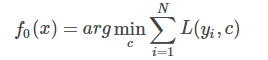
循环过程:
-
计算损失函数的负梯度在当前模型的值,将它作为残差的估计。以下是残差计算公式:
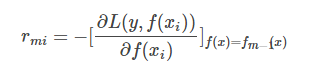
-
估计回归树叶节点区域,以拟合残差的近似值,得到决策树
-
利用线性搜索估计叶节点区域的值,使损失函数极小化,最优估计节点区域的值计算:
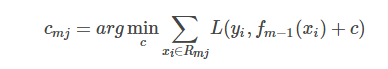
-
更新回归树
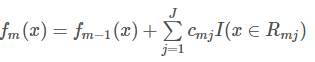
迭代完成后,输出最终模型 :
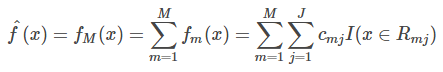
####负梯度方向:
负梯度方向(negative gradient direction)多元可微函数在一点处梯度向量的反方向,它是使函数f在点x附近下降最快的方向.
####残差
在GBDT中,残差是损失函数为MSE平方损失下的真实值和某一轮模型预测值的差值即 yi - f(xi)。其实这个是对平方损失函数求导之后的结果,也就是说在平方损失下求完导,它的负梯度就是残差。
####GBDT的优缺点:
优点:
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 精度一般都比较高
- GBDT几乎可用于所有回归问题(线性/非线性)
缺点:
- 对异常值比较敏感
- 算法的执行过程是串行的,树过得多时容易过拟合,而且会影响速度
###GBDT的回归与分类
GBDT既可以用于处理回归问题也可以处理分类问题,二者之间的差异主要是通过改变模型的损失函数进行更换。
回归问题对应的损失及在sklearn中的参数值:
- 平方损失,sklearn参数ls
- 绝对值损失,sklearn参数lad
- Huber损失,sklearn参数huber
- 分为数损失,,sklearn参数quantile
分类问题对应的损失及在sklearn中的参数值:
- 对数损失,sklearn参数deviance(类似与逻辑回归的损失函数)
- 指数损失,sklearn参数exponential
###python代码实现
from sklearn.datasets import load_boston
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import GradientBoostingClassifier
boston = load_boston()
#查看波士顿数据集的keys
print(boston.keys())
boston_data=boston.data
target_var=boston.target
feature=boston.feature_names
boston_df=pd.DataFrame(boston_data,columns=boston.feature_names)
boston_df['tar_name']=target_var
#查看目标变量描述统计
print(boston_df['tar_name'].describe())
#把数据集转变为二分类数据
boston_df.loc[boston_df['tar_name']<=21,'tar_name']=0
boston_df.loc[boston_df['tar_name']>21,'tar_name']=1
X_train, X_test, y_train, y_test = train_test_split(boston_df[feature], boston_df['tar_name'], test_size=0.30, random_state=1)
GB=GradientBoostingClassifier(n_estimators=500,max_depth=2,random_state=1,learning_rate=0.03)
GB.fit(X_train,y_train)
# 度量GBDT的准确性
y_train_pred = GB.predict(X_train)
y_test_pred = GB.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('GBDT train/test accuracies %.3f/%.3f' % (tree_train, tree_test))
结果:
Random Forest train/test accuracies 0.986/0.882
参考资料: https://www.cnblogs.com/pinard/p/6140514.html