XLNET
But the AE language model also has its disadvantages. It uses the [MASK] in the pretraining, but this kind of artificial symbols are absent from the real data at finetuning time, resulting in a pretrain-finetune discrepancy.Another disadvantage of [MASK] is that it assumes the predicted (masked) tokens are independent of each other given the unmasked tokens. For example, we have a sentence "It shows that the housing crisis was turned into a banking crisis". We mask "banking" and "crisis". Attention here, we know the masked "banking" and "crisis" contains implicit relation to each other. But AE model is trying to predict "banking" given unmasked tokens, and predict "crisis" given unmasked tokens separately. It ignores the relation between "banking" and "crisis". In other words, it assumes the predicted (masked) tokens are independent of each other. But we know the model should learn such correlation among the predicted (masked) tokens to predict one of the tokens.
A traditional language model would predict the tokens in the order
"I", "like", "cats", "more", "than", "dogs"
where each token uses all previous tokens as context.
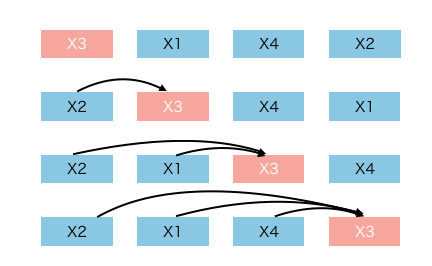
In permutation language modeling, the order of prediction is not necessarily left to right and is sampled randomly instead. For instance, it could be
"cats", "than", "I", "more", "dogs", "like"
where "than" would be conditioned on seeing "cats", "I" would be conditioned on seeing "cats, than" and so on. The following animation demonstrates this.
输入看上去仍然是x1,x2,x3,x4,可以通过不同的掩码矩阵,让当前单词Xi只能看到被排列组合后的顺序x3->x2->x4->x1中自己前面的单词


Robertra
与BERT的差别
Facebook的研究人员发现超参数选择对BERT的最终结果有重大影响,因此他们重新研究了BERT的预训练模型,测量了不同超参数和训练集大小的影响,结果发现BERT存在明显的训练不足。
经过调整后,BERT可以达到或超过其后发布的每个模型的性能,这些结果突出了之前被忽视的设计选择的重要性,
RoBERTa与BERT的不同之处在于,它依赖于预训练大量数据和改变训练数据的mask模式,而且RoBERTa删除了下一句预测(NSP)。
RoBERTa的修改很简单,包括:
- 更长时间的训练时间,更大的batch,更多的数据;
- 删除下一句预测(NSP)目标;
- 在较长序列上进行训练;
- 动态改变用于训练数据的mask模式。(The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training.)
参考:
https://zhuanlan.zhihu.com/p/75856238
https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335