目录
- Seq2Seq介绍
- 原理解析和进化发展过程
- Seq2Seq的预处理
- seq2seq模型预测
一句话简介:2014年提出的Seq2Seq(Sequence to Sequence), 就是一种能够根据给定的序列,通过特定的方法生成另一个序列的方法。 一般用于机器翻译,图片描述,对话等场景。早期基本上基于LSTM,后面发展使用attention。
一、Seq2Seq介绍
来源:所谓最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的论文【2】和Yoshua Bengio团队的论文【1】。这两篇文章不谋而合地提出了相似的解决思路,Seq2Seq由此产生。
应用场景:
- 机器翻译(当前最为著名的Google翻译,就是完全基于Seq2Seq+Attention机制开发出来的)。
- 聊天机器人(小爱,微软小冰等也使用了Seq2Seq的技术(不是全部))。
- 文本摘要自动生成(今日头条等使用了该技术)。
- 图片描述自动生成。
- 机器写诗歌、代码补全、生成 commit message、故事风格改写等。
二、原理解析和进化发展过程
2.1 论文【1】和【2】的基础版本
首先,我们要明确Seq2Seq解决问题的主要思路是通过深度神经网络模型(常用的是LSTM)将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码输入(encoder)与解码输出(decoder)两个环节组成。这里我们必须强调一点,Seq2Seq的实现程序设计好之后的输入序列和输出序列长度是不可变的。
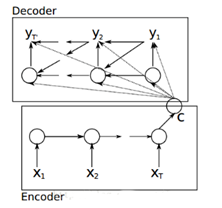
图1. 论文[1] 模型按时间展开的结构
论文[1]Cho et al. 首次提出了 Gated Recurrent Unit (GRU)这个使用频率非常高的 RNN 结构。还提出 Encoder-Decoder 这样一个伟大的结构以外,其中 Encoder 部分应该是非常容易理解的,就是一个RNNCell(RNN ,GRU,LSTM 等,当然也可以是比如CNN/RNN/BiRNN/Deep LSTM等) 结构。每个 timestep, 我们向 Encoder 中输入一个字/词(一般是表示这个字/词的一个实数向量),直到我们输入这个句子的最后一个字/词 XT ,然后输出整个句子的语义向量 c
(一般情况下, 是最后一个输入)。因为 RNN 的特点就是把前面每一步的输入信息都考虑进来了,所以理论上这个 c 就能够把整个句子的信息都包含了。
论文[1] 中的公式表示如下:

yt的条件概率
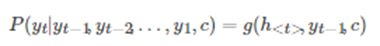
f 函数结构应该是一个 RNNCell 结构或者类似的结构(论文[1]原文中用的是 GRU);g函数一般是 softmax (或者是论文 [4] 中提出的 sampled_softmax 函数)
注意到这里的c 不仅仅作用在第一个词,而是作用到所有的词,对比论文[2]只作用在第一个词上,其Decoder 预测第 t 个 timestep 的输出时可以表示为:
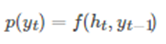
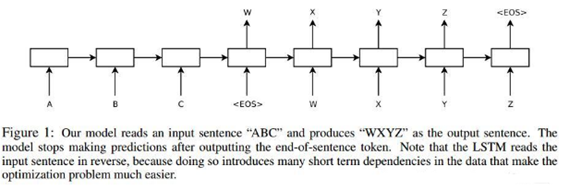
图2. 论文[2] 模型结构
论文 [2]Sutskever et al. 也是我们在看 seq2seq 资料是最经常提到的一篇文章, 在原论文中,上面的Encoder 和 Decoder 都是 4 层的 LSTM,但是原理其实和 1 层 LSTM 是一样的。原文有个小技巧:应用在机器翻译中的,作者将源句子顺序颠倒后再输入 Encoder 中,比如源句子为"A B C",那么输入 Encoder 的顺序为 "C B A",经过这样的处理后,取得了很大的提升,而且这样的处理使得模型能够很好地处理长句子。此外,Google 那篇介绍机器对话的文章(论文[5] )用的就是这个 seq2seq 模型。
在 CS224n lecture1 中, 也介绍了论文[2]的这个模型,下图是该课件中展示的模型结构。原文中提到的模型是 4 层的,课件上只是展示了三层,但是已经足够帮助我们理解模型结构了。
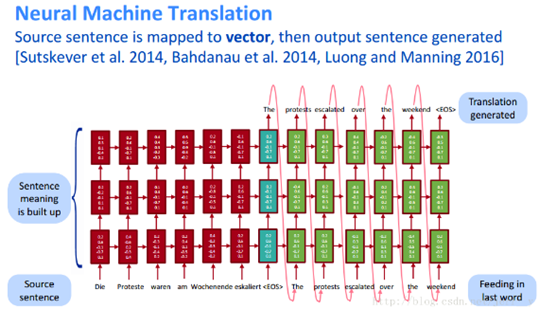
图3. 多层LSTM的 seq2seq 模型结构(来自 CS224n lecture1)
2.2 论文【3】和【4】的升级版本
论文[3] Bahdanau et al. (已经被应用千次)是在 Encoder 和 Decoder 的基础上提出了注意力机制。在上面提到的结构中,有个缺点:如果句子很长的话,c 未必能把所有的信息都保留好,所以就有了 Attention Model 这样一种东西出现了,它的出现让机器翻译的效果大大地提升了。引入注意力机制的原理其实还是挺好理解的:
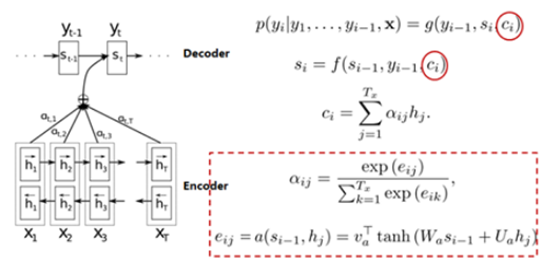
图4. 论文[3] 模型结构
在论文[1] 的 decoder 中,每次预测下一个词都会用到中间语义 c,c主要就是最后一个时刻的隐藏状态。在论文[3] 中,我们可以看到在Decoder进行预测的时候,Encoder中每个时刻的隐藏状态都被利用上了。这样子,Encoder 就能利用多个语义信息(隐藏状态)来表达整个句子的信息了。关于Attention后续文章将继续讨论,这里不展开描述。
此外,在论文[3] 中,Encoder用的是双端的 GRU,这个结构其实非常直观,在这种 seq2seq 中效果也要比单向的 GRU 要好。至于模型的细节可以看原论文来进行理解,在这里我就不做展开,也可以参考文末的【10】。
论文【3】中,

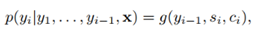
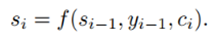
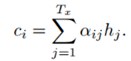
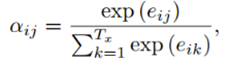

解释:对于时间步i的隐藏状态si,可以通过求时间步i-1的隐藏状态si-1、输入内容的编码向量ci和上一个输出yi-1得到。输入内容编码ci是新加入的内容,可以通过计算输入句子中每个单词的权重,然后加权求和得到ci。直观解释这个权重:对于decoder的si和encoder的hj的权重,就是上一个时间步长的隐藏状态si-1与encoder的hj通过非线性函数得到的。这样就把输入内容加入到解码的过程中,这和我们人类翻译的过程也是类似的,即对于当前输出的词,每一个输入给与的注意力是不一样的。
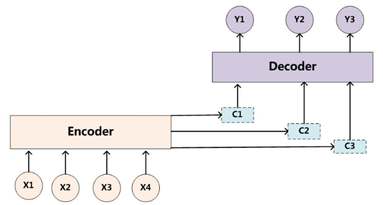
图5. 引入AM模型的Encoder-Decoder框架
论文[4]介绍了机器翻译在训练时经常用到的一个方法(小技巧)sample_softmax ,主要解决词表数量太大的问题。
三、Seq2Seq的预处理
最后,我们要说的还有一点关键的预处理工作。NLP乃至人工智能处理的数据都是数字,那么这里的文字该怎么处理呢?我们都知道OneHot,TF-IDF,词袋法等等都可以将文档数值化处理。我们通常的预处理步骤如下:
- 首先我们假设有10000个问答对,统计得到1000个互异的字以及每个字对于出现的次数。
- 根据统计得到的这1000个字,按照次数从多到少进行排序,序号从0开始到999结束(得到我们的字典表ids)。
- 对于问答对,进行One-Hot编码。
- 由于One-Hot编码的维度较大且0较多,因此我们进行embedding降维(具体维数自定义)得到我们的特征矩阵。
四、seq2seq模型预测
在准备训练数据集时,我们通常会在样本的输入序列和输出序列后面分别附上一个特殊符号"<eos>"(end of sequence)表该序列的终止。为了便于讨论,设输出本词典Y(包含特殊符号"<eos>")的大小为|Y|,输出序列的最大长度为T′。所有可能的输出序列共有 种 ,下面讨论三种方式:
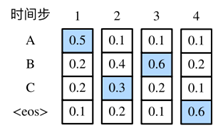
图6. 预测模型
使用全局搜索将会得到最优解,ACB。
4.1 穷举搜索
就是所有的输出词典单词进行组合,这样有 种可能性,虽然能得到最优解,但是随着输出的增大,将呈现指数增长形式。
4.2 贪婪搜索

在每个时间步,贪婪搜索选取条件概率最大的词,其复杂度 。因此图7中使用贪婪搜索,将只能得到ABC这种序列。
5.3 束搜索
束搜索(beam search)是对贪婪搜索的一种改进算法。它有束宽(beam size)超参数。我们将它设为 k。在时间步 1 时,选取当前时间步条件概率最大的 k 个词,分别组成 k 个候选输出序列的词。在之后的每个时间步,基于上个时间步的 k 个候选输出序列,从 k |Y| 个可能的输出序列中选取条件概率最大的 k 个,作为该时间步的候选输出序列。
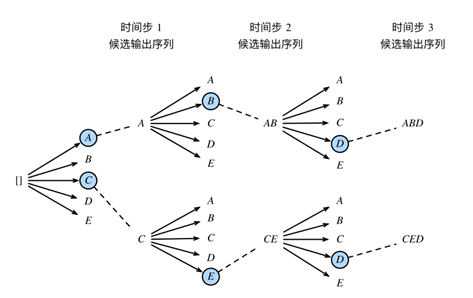
图7. 束搜索
上图中束宽为2,输出序列最大长度为3。候选输出序列有A、C、AB、CE、ABD和CED。我们将根据这6个序列得出最终候选输出序列的集合。在最终候选输出序列的集合中,我们取以下分数最大的序列作为输出序列:

其中 L 为最终候选序列长度,α 一般可选为0.75。分母上的 Lα 是为了惩罚较长序列在以上分数中较多的对数相加项。分析可知,束搜索的计算开销介于贪婪搜索和穷举搜索的计算开销之间。此外,贪婪搜索可看作是束宽为 1 的束搜索。束搜索通过灵活的束宽 k 来权衡计算开销和搜索质量。
备注:后续再考虑细读论文和实现问题。
参考文献
【1】Cho et al., 2014 . Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
【2】Sutskever et al., 2014. Sequence to Sequence Learning with Neural Networks
【3】Bahdanau et al., 2014. Neural Machine Translation by Jointly Learning to Align and Translate
【4】 Jean et. al., 2014. On Using Very Large Target Vocabulary for Neural Machine Translation
【5】 Vinyals et. al., 2015. A Neural Conversational Model[J]. Computer Science
【6】EMNLP 2015 [1509.00685] A Neural Attention Model for Abstractive Sentence Summarization
【7】基础学习: https://blog.csdn.net/qq_32241189/article/details/81591456
【9】趣味阅读-神经网络和seq2seq: http://www.dataguru.cn/article-9779-1.html?utm_source=tuicool&utm_medium=referral
【10】自然语言处理中的Attention Model:是什么及为什么 https://blog.csdn.net/malefactor/article/details/50550211
【11】最新代码和理论:https://zhuanlan.zhihu.com/p/57155059 和