一、配置/etc/profile:
文件尾部增加以下内容:
export SPARK_HOME=/home/spark/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin
export SPARK_EXAMPLES_JAR=$SPARK_HOME/examples/jars/spark-examples_2.11-2.2.0.jar
二、配置spark环境变量
在spark的conf文件夹中复制 spark-env.sh.template生成 spark-env.sh文件,在尾部添加如下代码:
export JAVA_HOME=/home/java/jdk1.8.0_161 export PATH=$PATH:$JAVA_HOME/bin export SPARK_MASTER_HOST="10.217.2.240"
第三行的变量指定的是master的IP,我的机器上面worker节点不能直接根据hostname找到master,所以必须要在这里声明masterIP,worker才能连接到master
三、配置worker节点ip:
在spark的conf文件夹中复制 slaves.template生成 slaves文件,在尾部添加如下代码:
localhost 10.217.2.241 10.217.2.242
这里配置的是worker的ip,我这里的意思就是在本地和后面两个节点都启动worker,一共3个worker。
以上三点配置必须在所有节点上同步
四、配置ssh:
运行start-all.sh脚本的机器必须要有所有worker节点的访问权,所以要么是在环境变量中配置各个节点的登陆密码,要么就配置ssh密钥登陆,ssh更方便些。在本节点生成密钥 ,ssh-keygen -t rsa,
然后将密钥拷贝到所有worker节点的authorized_keys中,注意由于这里我把本机也设为worker节点,所以在本机的 authorized_keys 文件中也要放公钥。
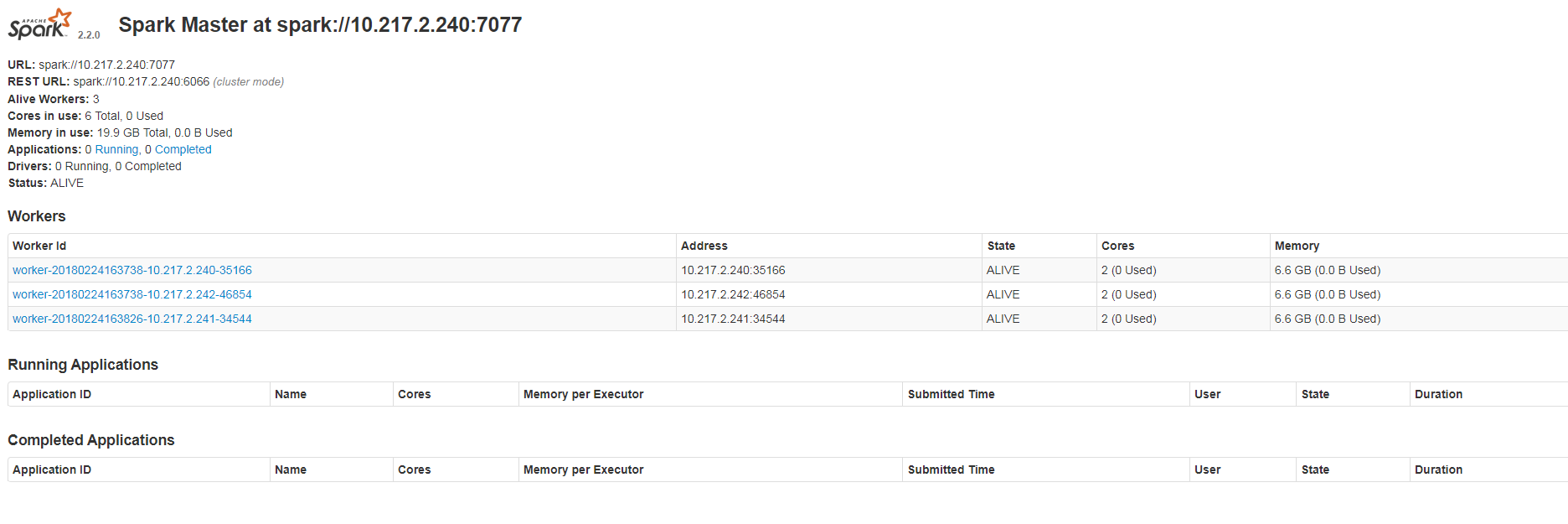
五、运行start-all.sh,稍等一会,然后就可以在masterUI中看到启动成功了.