爬虫中接触或者使用过那些数据解析的方式?
- 正则 - bs4(只能在python中使用) - xpath - pyquery(了解,自学)
解析原理:
标签的定位(从请求到的页面中找到需要的数据的标签)
提取数据(从标签中获取到需要的数据)
bs4解析
解析原理: 实例化一个BeautifulSoup对象,并且将即将被解析的源码数据对象加载到该对象中 调用BeautifulSoup对象中相关的属性和方法进行标签定位和数据的提取 环境的安装: pip install bs4 pip install lxml BeautifulSoup对象的实例化 #将本地的html文档中的源码数据加载到该对象中,fp是本地文件 soup=BeautifulSoup(fp,'lxml') #将从互联网中获取到的数据加载到该对象中,page_text是从网上获取到的数据 BeautifulSoup(page_text,'lxml')
用法
from bs4 import BeautifulSoup
#从本地获取数据
fp=open('./a.html','r',encoding='utf-8')
soup=BeautifulSoup(fp,'lxml')
#从网页中获取的数据
page_text=requests.get(url=url,headers=headers).text
soup=BeautifulSoup(page_text,'lxml')
#标签定位
soup.TagName #获取到网页中第一次出现的标签
soup.find('tagName',attrName='属性名') #通过属性名定位到标签,也是只能拿到一条数据
soup.find_all('tagName',attrName='属性名') #也是通过属性定位,但是能拿到所有的数据
soup.select('选择器')
soup.select('#fei')
soup.select('.fei > ul > li') # > 是只能一层一层的找, 空格是可以多层找
#数据提取
提取文本信息内容
soup.p.string #获取的是标签中直系的文本内容
soup.p.text #获取的是标签中所有的文本内容
soup.p.get_text() #和text效果差不多
提取属性值
soup.img['标签名']
实例
#爬取三国演义小说全篇内容 from bs4 import BeautifulSoup import requests url = 'http://www.shicimingju.com/book/sanguoyanyi.html' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' } page_text = requests.get(url=url,headers=headers).text #数据解析:章节标题 soup = BeautifulSoup(page_text,'lxml') a_list = soup.select('.book-mulu > ul > li > a') fp = open('./sanguo.txt','w',encoding='utf-8') for a in a_list: title = a.string detail_url = 'http://www.shicimingju.com'+a['href'] #获取详情页的源码数据 detail_page_text = requests.get(url=detail_url,headers=headers).text soup = BeautifulSoup(detail_page_text,'lxml') content = soup.find('div',class_="chapter_content").text fp.write(title+':'+content+' ') print(title,'下载完毕!') fp.close()
xpath解析
解析原理:
实例化一个etree对象,并将页面源码数据加载到该对象中
可以通过etree对象中的xpath方法接个不同类型的xpath表达式进行标签定位和数据提取
环境安装:
pip install lxml
#etree对象的实例化
tree=etree.parse(filepath) #读取本地文件,将本地文件传入对象中
tree=etree.HTML(page_text) #将互联网中的源代码传入对象
用法:
from lxml import etree tree=etree.parse('./test.html') page_text=requests.get(url=url,headers=headers).text tree=etree.HTML(page_text) tree.xpath('/html/head/title') # 用'/'必须是从根节点开始找 tree.xpath('//head/title') #'//'不是从根节点开始寻找 #属性定位 tree.xpath('//div[@class="tang"]/li[2]')#通过索引定位,这里的索引是从1开始的 #数据提取
#提取文本内容 tree.xpath('//div/a[1]/text()') #/text()取出直系文本内容 tree.xpath('//div/a[1]//text()') # //text()取出的是a标签下的所有文本内容 #提取属性内容 tree.xpath('div[2]/@href') #直接@属性名
实例:
#爬取boss中岗位的名称,薪资,公司名称 url = 'https://www.zhipin.com/job_detail/?query=python%E7%88%AC%E8%99%AB&city=101010100&industry=&position=' page_text = requests.get(url=url,headers=headers).text #数据解析 tree = etree.HTML(page_text) li_list = tree.xpath('//div[@class="job-list"]/ul/li') for li in li_list: job_title = li.xpath('.//div[@class="job-title"]/text()')[0] salary = li.xpath('.//div[@class="info-primary"]/h3/a/span/text()')[0] company = li.xpath('.//div[@class="company-text"]/h3/a/text()')[0] print(job_title,salary,company)
分页处理:
#需求:爬取http://pic.netbian.com/4kmeinv/ 所有的图片数据 分页处理 url = 'http://pic.netbian.com/4kmeinv/index_%d.html' for page in range(1,6): if page == 1: new_url = 'http://pic.netbian.com/4kmeinv/' else: new_url = format(url%page) response = requests.get(url=new_url,headers=headers) # response.encoding = 'utf-8' page_text = response.text
......
懒加载:
我们在查看网页源码的时候发现,这里图片的有一个src属性储存的是图片地址,这是我们在网页的可视化界面中看到的,如图下:
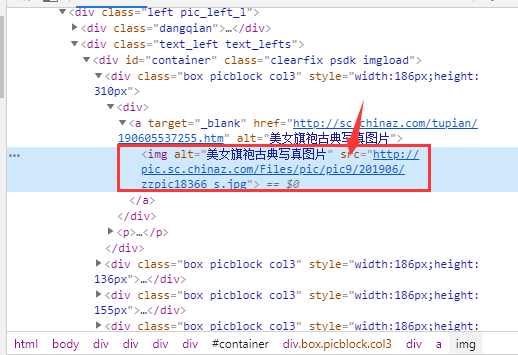
但是我们发现,图片不在我们可视化范围内的图片的src属性名变成了src2属性名,如图下:
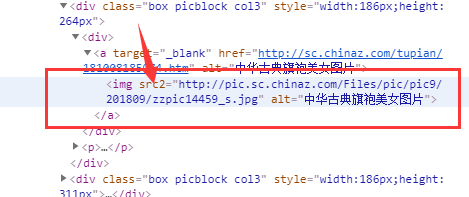
我们在进行爬虫数据分析获取标签属性值的时候,我们的爬虫程序时不会进入到可视化界面中的,所以如果用src属性找的话,是获取不到的,因此在这里我们获取属性值的时候,只需要获取src2就可以了.
实例: (图片懒加载怎么解决)
#站长素材中图片下载应用了图片懒加载的技术 url = 'http://sc.chinaz.com/tupian/gudianmeinvtupian.html' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #获取页面文本数据 response = requests.get(url=url,headers=headers) response.encoding = 'utf-8' page_text = response.text #解析页面数据(获取页面中的图片链接) #创建etree对象 tree = etree.HTML(page_text) div_list = tree.xpath('//div[@id="container"]/div') #解析获取图片地址和图片的名称 for div in div_list: image_url = div.xpath('.//img/@src2') #src2伪属性 image_name = div.xpath('.//img/@alt')