作业一
要求:
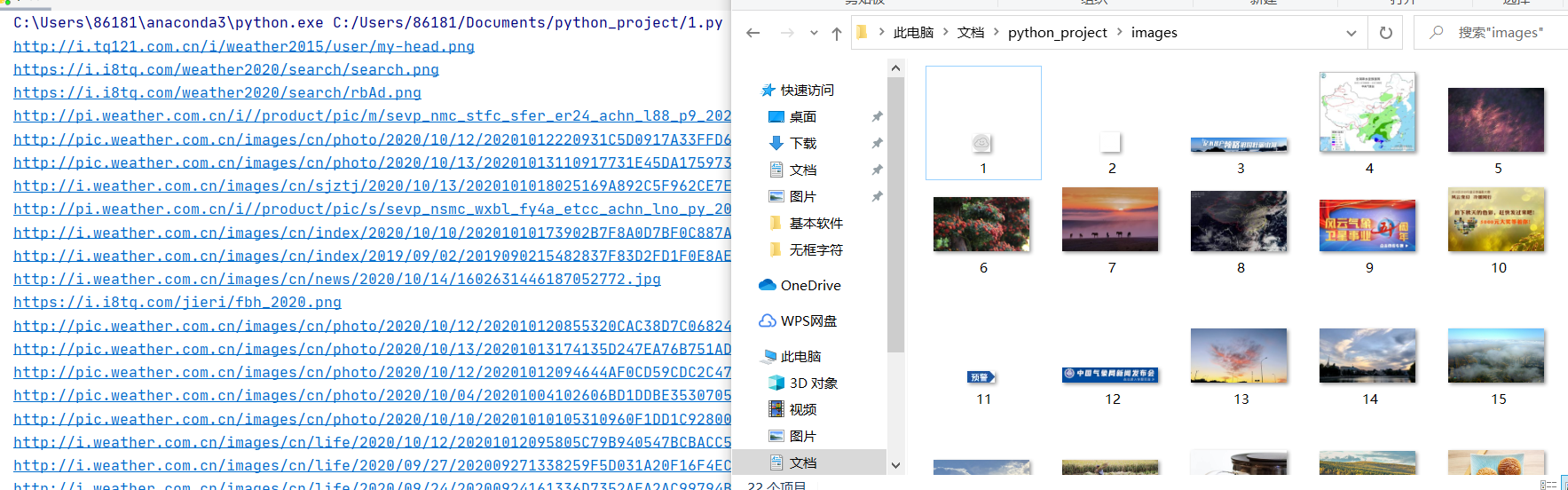
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)
分别使用单线程和多线程的方式爬取
代码
第一部分:单线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def goal_images(goal_url):#从目标的url中得到所有图片的urls的集合
try:
image_urls=[]#先初始化最终的图片结果
req = urllib.request.Request(goal_url, headers=headers) # 引入全局变量headers改换头部信息实现多次爬取
data = urllib.request.urlopen(req) # 目标网址打开
data = data.read() # 对网站内容进行读操作
dammit = UnicodeDammit(data, ["utf-8", "gbk"]) # 用utf-8和gbk来猜测文本编码,从而设置函数最终信息编码标准
data = dammit.unicode_markup # 将内容可转化为text
soup = BeautifulSoup(data, "lxml") # 用lxml来解析
images = soup.select("img") # 选取我们的目标(图片)的tag
try:
for image in images:
image_urls=get_image_in_url(goal_url,image,image_urls)#更新图片地址的集合
except Exception as e:
print(e)
except Exception as err:
print(err)
return image_urls
def get_image_in_url(goal_or_url,target_image,new_image_urls):#网页的地址,图片所在地址,最终获得图片地址集合
src = target_image["src"] # src存储的是图片的名称
this_url = urllib.request.urljoin(goal_or_url, src) # urljoin构建绝对路径
if this_url not in new_image_urls: # 将每一次获取得到的新的单个网址存入urls里面 避免重复
new_image_urls.append(this_url) # 不在,就添加.append
return new_image_urls
def download_all(image_urls):#下载所有的图片集合
for url in image_urls:
enc=judge_url(url)
download(url,enc)
print(url)
def download(url,ext):
global count # 全局变量,设置这个完全是因为想名称给解决哈哈!
req = urllib.request.Request(url, headers=headers) # 可以更有效的多次爬虫
data = urllib.request.urlopen(req, timeout=100) # 防止超时,和第一个函数比有相同的部分,这个就不太好重复工作
data = data.read() # 进行图片的数据读
fobj = open("images\" + str(count) + ext, "wb") # 默认是在编译器存储在同一个文档中,命名形式用count的具体指哈哈,根据读取的格式来结尾,允许读写图片
fobj.write(data) # 写数据
fobj.close() # 最后要关闭这个进程
count=count+1
def judge_url(pic_url):
if (pic_url[len(pic_url) - 4] == "."): # 判断是否为目标文件(图片)
ext = pic_url[len(pic_url) - 4:] # 获取图片的格式jdp还是png
else:
ext = ""
return ext
headers = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
count = 1
gurl="http://www.weather.com.cn/"
imageurls=goal_images(gurl)
download_all(imageurls)
print("over!")
第二部分:多线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):#图片爬取
global count # 全局变量,设置这个完全是因为想名称给解决哈哈!
global threads
try:
urls = [] #最终所要得到爬取图片的网址一开始会置为空
req = urllib.request.Request(start_url, headers=headers) #引入全局变量headers改换头部信息实现多次爬取
data = urllib.request.urlopen(req) #目标网址打开
data = data.read() #对网站内容进行读操作
dammit = UnicodeDammit(data, ["utf-8", "gbk"])#用utf-8和gbk来猜测文本编码,从而设置函数最终信息编码标准
data = dammit.unicode_markup #将内容可转化为text
soup = BeautifulSoup(data, "lxml") #用lxml来解析
images = soup.select("img")#选取我们的目标(图片)的tag
for image in images:#images是存储所有的图片,而image是存取单个图片(可替换)
src = image["src"]#src存储的是图片的名称
url = urllib.request.urljoin(start_url, src)#urljoin构建绝对路径
if url not in urls:#将每一次获取得到的新的单个网址存入urls里面 避免重复
count = count+1
T = threading.Thread(target=download,args=(url,count))# 单个线程的执行操作,执行目标函数download(url,count)4
T.setDaemon(False) #确保所有的线程都已经执行完毕(后台线程不会随主线程结束而结束)
T.start() #开始执行
threads.append(T) #将该线程归为线程池,确保后续的所有线程都已经完成
print(url)#打印已经下载的图片
except Exception as er:
print(er)
def download(url,count):#具体的下载过程
try:
count = count + 1#我是选择一开始就加一
if (url[len(url) - 4] == "."):#判断是否为目标文件(图片)
ext = url[len(url) - 4:]#获取图片的格式jdp还是png
else:
ext = ""
req = urllib.request.Request(url, headers=headers)#可以更有效的多次爬虫
data = urllib.request.urlopen(req, timeout=100)#防止超时,和第一个函数比有相同的部分,这个就不太好重复工作
data = data.read()#进行图片的数据读
fobj = open("images\" + str(count) + ext, "wb")#默认是在编译器存储在同一个文档中,命名形式用count的具体指哈哈,根据读取的格式来结尾,允许读写图片
fobj.write(data)#写数据
fobj.close()#最后要关闭这个进程
except Exception as e:
print(e)
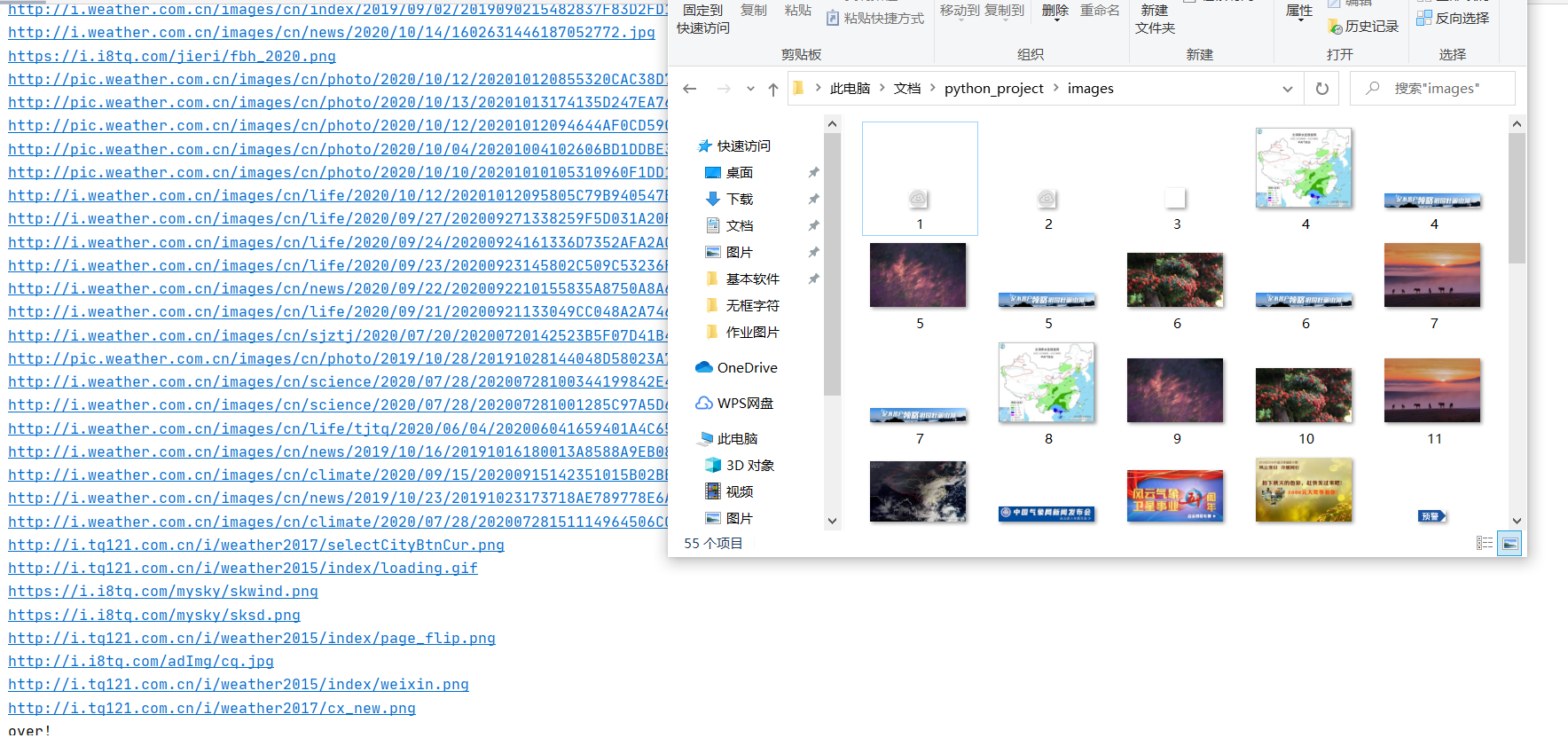
start_url = "http://www.weather.com.cn/"#我爬取的是教务处,其他网站也可以直接更换这条信息即可
headers = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
count = 0
threads = [] #线程池
imageSpider(start_url) # 调用函数
for t in threads:
t.join() #等待其他线程完成
print("over!")
心得体会
显而易见的是多线程更加快速,几乎瞬间,但是结束返回“over”却很慢可能是其他线程没有结束的原因吧!
然后代码呢,就是复现罢了,加了一些注释
相较于单线程,多线程就是加了一个线程池和调用线程的开始和等待的函数以及定义线程
作业二
要求:使用scrapy框架复现作业①
代码
task.py
import scrapy
from ..items import TasktwoItem
"""
这次是作业二的代码
"""
class task(scrapy.Spider):
name = 'task' # 爬虫的名称
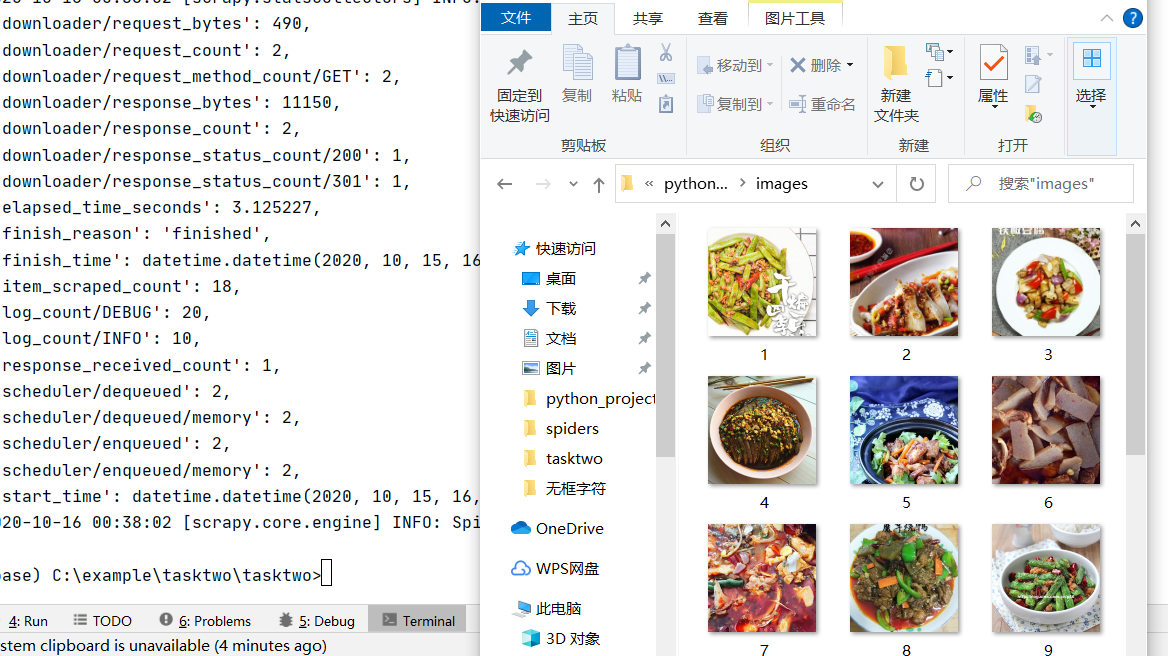
allowed_domains = ['meishi.net'] #网址
start_urls=['http://www.meishij.net/china-food/caixi/chuancai/'] #初始网址
def parse(self,response):
src_list = response.xpath('//div[@class="liststyle1_w clearfix"]//div[@class="listtyle1"]/a/img/@src').extract() #寻找的目标
for src in src_list:
item = TasktwoItem() #获取信息定义为item
item['src'] = src # 保存信息
yield item
items.py
import scrapy
class TasktwoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
pipelines.py
import urllib
from itemadapter import ItemAdapter
from bs4 import UnicodeDammit
# 自认为是关键,可能是之前的用select获取信息的时候经常调用
class TasktwoPipeline:
count = 0 #便于命名
def process_item(self, item, spider):
TasktwoPipeline.count += 1
url = item['src']
if (url[len(url) - 4] == "."): # 判断是否为目标文件(图片)
ext = url[len(url) - 4:] # 获取图片的格式jdp还是png
else:
ext = ""
req = urllib.request.Request(url) # 引入全局变量headers改换头部信息实现多次爬取
data = urllib.request.urlopen(req) # 目标网址打开
data = data.read() # 对网站内容进行读操作
fobj = open("C:\Users\86181\Documents\python_project\images" + str(TasktwoPipeline.count) + ext,
"wb") # 默认是在编译器存储在同一个文档中,命名形式用count的具体指哈哈,根据读取的格式来结尾,允许读写图片
fobj.write(data) # 写数据
fobj.close() # 最后要关闭这个进程
setting.py
BOT_NAME = 'tasktwo' # 自动生成
SPIDER_MODULES = ['tasktwo.spiders'] # 自动生成
NEWSPIDER_MODULE = 'tasktwo.spiders' # 自动生成
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'tasktwo.middlewares.TasktwoDownloaderMiddleware': None, # 选择默认值none 好像是scrapy和最后结果的传输的作用
}
ITEM_PIPELINES = {
'tasktwo.pipelines.TasktwoPipeline': 300, # 允许管道传输
}
心得体会
settings.py文件中有的是需要自己修改的,然后就是debug的时候取消对应的注释,图片是因为自己想要偷懒选取别的网站;
分析后的很好找到要爬取的信息位置

用的语句除了xpath(),其余和之前都相似,然后唯一个让人不适应的地方在于:用断点的形式debug不太会用;
再者,报错的时候看看终端显示DEBUG: <>(寻求这样的信息)会好找到错误;
还有一点要注意就是爬虫名字一定要对!settings.py和spider.py要一致,否则会出现下面的,一般建议是scrapy genspider <名字> <网站>

作业三
要求:使用scrapy框架爬取股票相关信息
代码
task_em.py
import scrapy
from ..items import TaskthreeItem
import re
"""
这次是作业三的代码
"""
# -*- coding: utf-8 -*-
class task_em(scrapy.Spider):
name = 'task_em' # 爬虫的名称
#由于复杂度的关系,所以url直接指定
start_urls=['http://87.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124007929044454484524_1601878281258&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f26&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1601536578736'] #初始网址由于之前写的比较混乱所以就用page=1来代替不做翻页操作
def parse(self,response):
count = 0
pat = '"diff":[(.*?)]'# 因为之前是用正则表达式
data = re.compile(pat, re.S).findall(response.text) #获取数据
data = data[0].strip("{").strip("}").split('},{') # 一页股票数据
for i in range(len(data)):
data_one = data[i].replace('"', "") # 相当于一条记录
count += 1
item = TaskthreeItem() # 获取信息定义为item
stat = data_one.split(',') #数据所在的位置
#接下来要做的就是一一对应传参
item['count'] = count
name = stat[13].split(":")[1]
item['name'] = name
num = stat[11].split(":")[1]
item['num'] = num
lastest_pri = stat[1].split(":")[1]
item['lastest_pri'] = lastest_pri
dzf = stat[2].split(":")[1]
item['dzf'] = dzf
dze = stat[3].split(":")[1]
item['dze'] = dze
cjl = stat[4].split(":")[1]
item['cjl'] = cjl
cje = stat[5].split(":")[1]
item['cje'] = cje
zf = stat[6].split(":")[1]
item['zf'] = zf
top = stat[14].split(":")[1]
item['top'] = top
low = stat[15].split(":")[1]
item['low'] = low
today = stat[16].split(":")[1]
item['today'] = today
yestd = stat[17].split(":")[1]
item['yestd'] = yestd
yield item
pipeline.py
from itemadapter import ItemAdapter
class TaskthreePipeline(object):
def process_item(self, item, spider):
print(item['count'], item['name'], item['num'], item['lastest_pri'], item['dzf'], item['dze'], item['cjl'], item['cje'], item['zf'], item['top'], item['low'], item['today'], item['yestd'])
return item
settings.py
BOT_NAME = 'taskthree' # 自动生成
SPIDER_MODULES = ['taskthree.spiders'] # 自动生成
NEWSPIDER_MODULE = 'taskthree.spiders' # 自动生成
ROBOTSTXT_OBEY = False # 也是debug 的时候发现的貌似是权限的
ITEM_PIPELINES = {
'taskthree.pipelines.TaskthreePipeline': 300,# 允许管道传输
}
items.py
import scrapy
class TaskthreeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 定义变量
count = scrapy.Field()
name = scrapy.Field()
num = scrapy.Field()
lastest_pri = scrapy.Field()
dzf = scrapy.Field()
dze = scrapy.Field()
cjl = scrapy.Field()
cje = scrapy.Field()
zf = scrapy.Field()
top = scrapy.Field()
low = scrapy.Field()
today = scrapy.Field()
yestd = scrapy.Field()

心得体会
做作业三的时候还是困难重重吧!可能是因为还是不太了解scrapy的机制;然后查阅资料(多翻翻书),按照作业二的格式重新再做一遍!
我估计:可能是之前的时候几个文件混乱穿插造成debug<200>,但是仍然没有数据
最后的最后:
就是items.py就是爬取数据的格式类型;
settings.py资源配置;
pipelines.py就是输出数据(将items的数据如何处理,是否print,是否保存到别的文件中);
spider.py就是给你地址,然后定义爬取的数据具体是什么(items.py的item)其实总的而言是省略了:“req = requests.get(url, headers=headers)”