转载自 http://download.csdn.net/source/858994
源地址下是 Word 文档,这里转换成HTML 格式
Lucene 源码剖析
文档内容是如何分析的
Analyzer类负责分析文档结构并提取内容。
6.1 文档分析类Analyzer
6.1.1 org.apache.lucene.store.Analyzer
Analyzer类构建用于分析文本的TokenStream对象,因此(thus)它表示(represent)用于从文本中分解(extract)出组成索引的terms的一个规则器(policy)。典型的(typical)实现首先创建一个Tokenizer,它将那些从Reader对象中读取字符流(stream of characters)打碎为(break into)原始的Tokens(raw Tokens)。然后一个或更多的TokenFilters可以应用在这个Tokenizer的输出上。警告:你必须在你的子类(subclass)中覆写(override)定义在这个类中的其中一个方法,否则的话Analyzer将会进入一个无限循环(infinite loop)中。
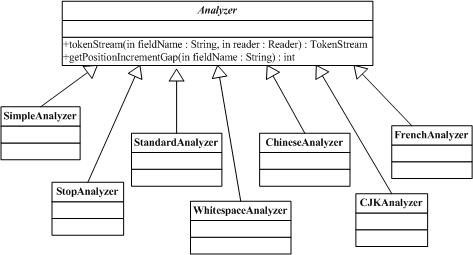
6.1.2 org.apache.lucene.store.StandardAnalyzer
StandardAnalyzer类是使用一个English的stop words列表来进行tokenize分解出文本中word,使用StandardTokenizer类分解词,再加上StandardFilter以及LowerCaseFilter以及StopFilter这些过滤器进行处理的这样一个Analyzer类的实现。
