1.什么是监督性学习?Supervised Machine Learning.
在监督性学习,我们给定一个数据集以及我们已经知道正确输出的结果,然后找到一个输入和输出的关系。
In Supervised learning,we are given a data set and already know what our correct output should look like ,having the idea that there is a relationship between the input and output.
监督性学习的问题被分为两大类,第一类是回归问题,第二类是分类问题。在回归问题,我们试着预测结果在连续输出,意味着我们试图将输入变量映射到某个连续函数。在分类问题中,相反,我们试图预测离散输出的结果。换句话说,我们试图将输入变量映射到离散类别中。
监督性学习目的是在构建能够根据存在不确定性的证据做出预测的模型。监督性学习算法接受已知的输入数据集和对数据的已知响应输出,然后训练模型,让模型能够未新输入数据的响应生成合理的预测。
监督性学习采用分类(classification)和(regression)技术开发预测模型。
1.分类技术可预测离散的响应(输出)--例如:
电子邮件是真正的邮件还是垃圾邮件,肿瘤是恶性还是良性。分类模型可将输入数据划分不同类别。典型应用包括:医学成像,语音识别,信用评估。
2,回归技术可预测连续的响应--例如,电力需求中温度或波动的变化。
典型的应用包括:电力系统负荷预测和算法交易。
应用:
使用监督性学习预测心脏病发作
假设临床医生希望预测某位患者在一年内是否会心脏病发作,他们有一千就医患者的患者相关数据,包括年龄,体重,身高以及血压。他们呢hi到一千的患者在一年内是否出现过心脏病发作,因此,问题在于如何将现有数据合并到模型中,并让该模型能够预测新患者在一年内是否出现心脏病发作。
2. 什么是非监督性学习?UnSupervised Machine Learning.
非监督性学习可发现数据中隐藏的模式或内在结构,这种技术可包含未标记响应的输入数据的数据集执行推理。
聚类是一种最常用的无监督性学习技术,这种技术可通过探索性数据分析发现数据中隐藏的模式或分组。
聚类的应用包括基因序列分析,市场调查和对象识别。![]()
![]()
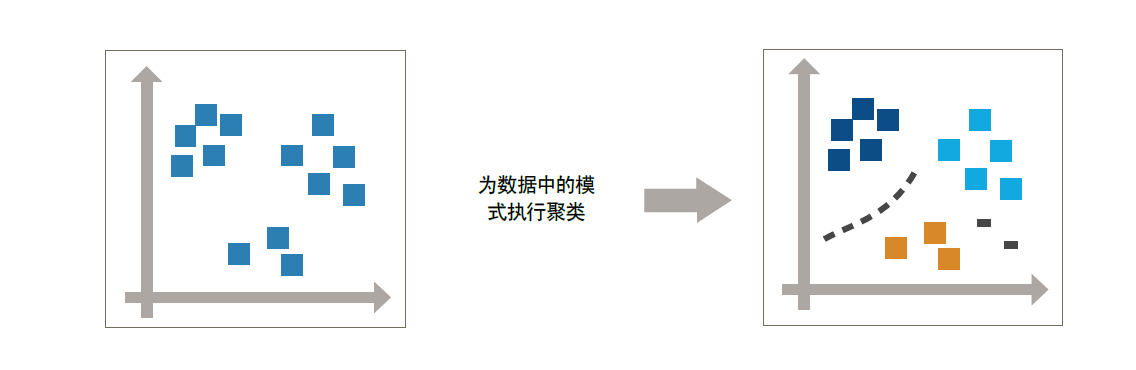
总结:
监督性机器学习就是根据已知的输入和输出训练模型,让模型能够预测未来输出。
非监督性机器学习就是从输入数据中找出隐藏模式或内在结构。

那么如何确定使用哪种算法?
选择正确的算法看似难以驾驭,需要从几十种监督性学习和非监督性学习算法中选择,每种算法又包含不同的学习方法。
没有最佳方法和完全之策。找到正确的算法知识是错过程的一部分,即使经验丰富的数据科学家,也无法说出某种算法是否无需试错即可使用,但是算法的选择还却决我们要处理数据的大小以及类型,要从数据中获取洞察力以及如何使用这些洞察力。这才是机器学习的开始。。
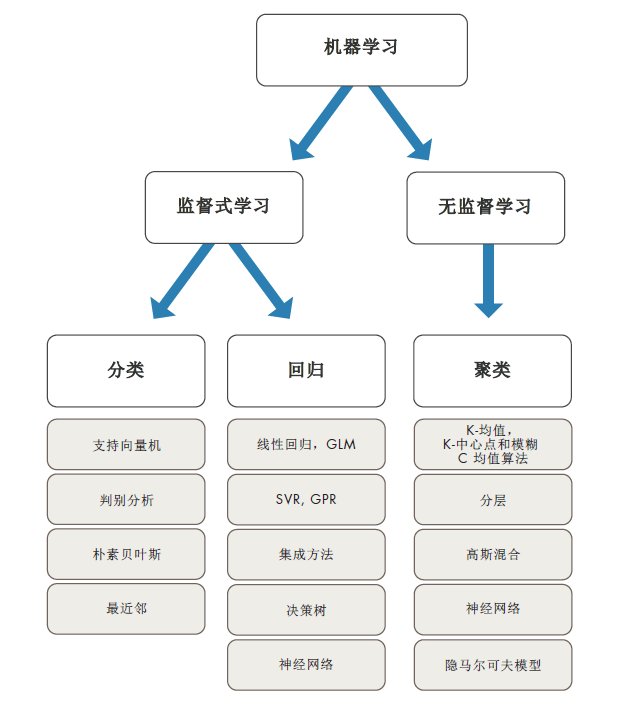
PS:
知识引用
吴恩达的机器学习
matlab的机器学习