对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象。对象序列化机制允许把内存中的 Java 对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点。其他程序一旦获得了这种二进制流(无论是从磁盘中获取的,还是通过网络获取的),都可以将这种二进制流恢复成原来的 Java 对象。
序列化的含义和意义
序列化机制允许将实现序列化的 Java 对象转换成字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以备以后重新恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
对象的序列化(Serialize)指将一个 Java 对象写入 IO 流中,与此对应的是,对象的反序列化(Deserialize)则指从 IO 流中恢复该 Java 对象。
Java9 增强了对象序列化机制,它允许对读入的序列化数据进行过滤,这种过滤可在反序列化之前对数据执行校验,从而提高安全性和健壮性。
如果需要让某个对象支持序列化机制,则必须让它的类是可序列化的(serializable)。为了让某个类是可序列化的,该类必须实现如下两个接口之一
- Serializable
- Externalizable
Java 的很多类已经实现了 Serializable,该接口是一个标记接口,实现该接口无须实现任何方法,它只是表明该类的实例是可序列化的。
所有可能在网络上传输的对象的类都应该是可序列化的,否则程序将会出现异常,比如 RMI(Remote Method Invoke,即远程方法调用,是 JavaEE 的基础)过程中的参数和返回值;所有需要保存到磁盘里的对象的类都必须可序列化,比如 Web 应用中需要保存到 HttpSession 或 ServletContext 属性的 Java 对象。
因为序列化是 RMI 过程的参数和返回值都必须实现的机制,而 RMI 又是 JavaEE 技术的基础——所有的分布式应用常常需要跨平台、跨网络,所以要求所有传递的参数、返回值必须实现序列化。因此序列化机制是 JavaEE 平台的基础。通常建议:程序创建的每个 JavaBean 类都实现 Serializable。
使用对象流实现序列化
如果需要将某个对象保存到磁盘上或者通过网络传输,那么这个类应该实现 Serializable 接口或者 Externalizable 接口之一。关于这两个接口的区别和联系,后面将有更详细的介绍,读者先不去理会 Externalizable 接口。
使用 Serializable 来实现序列化非常简单,主要让目标类实现 Serializable 标记接口即可,无须实现任何方法。
一旦某个类实现了 Serializable 接口,该类的对象就是可序列化的,程序可以通过如下两个步骤来序列化该对象。
①创建一个 ObjectOutputStream,这个输出流是一个处理流,所以必须建立在其他节点流的基础之上。
②调用 ObjectOutputStream 对象的 writeObject() 方法输出可序列化对象。
// 创建个 ObjectOutputStream 输出流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.txt")); // 将一个 Person 对象输出到输出流中 oos.writeObject(per);
下面程序定义了一个 Person 类,这个 Person 类就是一个普通的 Java 类,只是实现了 Serializable 接囗,该接口标识该类的对象是可序列化的。
public class Person implements java.io.Serializable { private String name; private int age; // 注意此处没有提供无参数的构造器! public Person(String name, int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 }
下面程序使用 ObjectOutputStream 将一个 Person 对象写入磁盘文件。
public class WriteObject { public static void main(String[] args) { try ( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.txt"))) { Person per = new Person("孙悟空", 500); // 将per对象写入输出流 oos.writeObject(per); } catch (IOException ex) { ex.printStackTrace(); } } }
上面程序中的第一行粗体字代码创建了一个 ObjectOutputStream 输出流,这个 ObjectOutputStream 输出流建立在一个文件输出流的基础之上;程序第二行粗体字代码使用 writeObject() 方法将一个 Person 对象写入输出流。运行上面程序,将会看到生成了一个 object.txt 文件,该文件的内容就是 Person 对象。
如果希望从二进制流中恢复 Java 对象,则需要使用反序列化。反序列化的步骤如下。
①创建一个 ObjectInputStream 输入流,这个输入流是一个处理流,所以必须建立在其他节点流的基础之上。
②调用 ObjectInputStream 对象的 readObject() 方法读取流中的对象,该方法返回一个 Object 类型的 Java 对象,如果程序知道该 Java 对象的类型,则可以将该对象强制类型转换成其真实的类型。
// 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.txt")); // 从输入流中读取一个Java对象,并将其强制类型转换为Person类 Person p = (Person) ois.readObject();
下面程序示范了从刚刚生成的 object.txt 文件中读取 Person 对象的步骤。
public class ReadObject { public static void main(String[] args) { try ( // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.txt"))) { // 从输入流中读取一个Java对象,并将其强制类型转换为Person类 Person p = (Person) ois.readObject(); System.out.println("名字为:" + p.getName() + " 年龄为:" + p.getAge()); } catch (Exception ex) { ex.printStackTrace(); } } }
上面程序中第一行粗体字代码将一个文件输入流包装成 ObjectInputStream 输入流,第二行粗体字代码使用 readObject() 读取了文件中的 Java 对象,这就完成了反序列化过程。
必须指出的是,反序列化读取的仅仅是 Java 对象的数据,而不是 Java 类,因此采用反序列化恢复 Java 对象时,必须提供该 Java 对象所属类的 class 文件,否则将会引发 ClassNotFoundException 异常。
还有一点需要指出:Person 类只有一个有参数的构造器,没有无参数的构造器,而且该构造器内有一个普通的打印语句。当反序列化读取 Java 对象时,并没有看到程序调用该构造器,这表明反序列化机制无须通过构造器来初始化 Java 对象。
如果使用序列化机制向文件中写入了多个 Java 对象,使用反序列化机制恢复对象时必须按实际写入的顺序读取。
当一个可序列化类有多个父类时(包括直接父类和间接父类),这些父类要么有无参数的构造器,要么也是可序列化的——否则反序列化时将抛出 InvalidClassException 异常。如果父类是不可序列化的,只是带有无参数的构造器,则该父类中定义的成员变量值不会序列化到二进制流中。
对象引用的序列化
前面介绍的 Person 类的两个成员变量分别是 String 类型和 int 类型,如果某个类的成员变量的类型不是基本类型或 String 类型,而是另一个引用类型,那么这个引用类必须是可序列化的,否则拥有该类型成员变量的类也是不可序列化的。
如下 Teacher 类持有一个 person 类的引用,只有 Person 类是可序列化的,Teacher 类才是可序列化的。如果 Person 类不可序列化,则无论 Teacher 类是否实现 Serializable、Externalizable 接口,则 Teacher类都是不可序列化的。
public class Teacher implements java.io.Serializable { private String name; private Person student; public Teacher(String name, Person student) { this.name = name; this.student = student; } // 此处省略了name和student的setter和getter方法 }
现在假设有如下一种特殊情形:程序中有两个 Teacher 对象,它们的 student 实例变量都引用到同一个 Person 对象,而且该 Person 对象还有一个引用变量引用它。如下代码所示。
Person per = new Person("孙悟空", 500); Teacher t1 = new Teacher("唐僧", per); Teacher t2 = new Teacher("菩提祖师", per);
上面代码创建了两个 Teacher 对象和一个 Person 对象,这三个对象在内存中的存储示意图如下图所示。
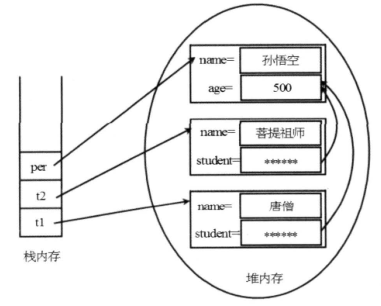
这里产生了一个问题——如果先序列化 t1 对象,则系统将该 t1 对象所引用的 Person 对象一起序列化;如果程序再序列化 t2 对象,系统将一样会序列化该 t2 对象,并且将再次序列化该 t2 对象所引用的 Person对象;如果程序再显式序列化 Person 对象,系统将再次序列化该 Person 对象。这个过程似乎会向输出流中输出三个 Person 对象。
如果系统向输出流中写入了三个 Person 对象,那么后果是当程序从输入流中反序列化这些对象时,将会得到三个 Person 对象,从而引起 t1 和 t2 所引用的 Person 对象不是同一个对象,这显然与上图所示的效果不一致——这也就违背了 Java 序列化机制的初衷。
所以,Java 序列化机制采用了一种特殊的序列化算法,其算法内容如下。
- 所有保存到磁盘中的对象都有一个序列化编号。
- 当程序试图序列化一个对象时,程序将先检查该对象是否己经被序列化过,只有该对象从未(在本次虚拟机中)被序列化过,系统才会将该对象转换成字节序列并输出。
- 如果某个对象已经序列化过,程序将只是直接输出一个序列化编号,而不是再次重新序列化该对象。
根据上面的序列化算法,可以得到一个结论——当第二次、第三次序列化 Person 对象时,程序不会再次将 Person 对象转换成字节序列并输出,而是仅仅输出一个序列化编号。假设有如下顺序的序列化代码:
oos.writeObject(t1);
oos.writeObject(t2);
oos.writeObject(per);
上面代码依次序列化了 t1、t2 和 per 对象,序列化后磁盘文件的存储示意图如下图所示。
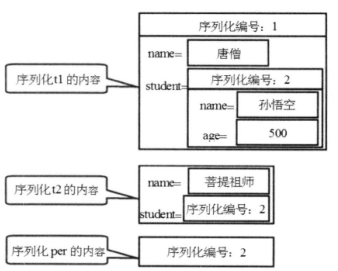
通过上图可以很好地理解 Java 序列化的底层机制,通过该机制不难看出,当多次调用 writeObject() 方法输出同一个对象时,只有第一次调用 writeObject() 方法时才会将该对象转换成字节序列并输出。
下面程序序列化了两个 Teacher 对象,两个 Teacher 对象都持有一个引用到同一个 Person 对象的引用,而且程序两次调用 writeObject() 方法输出同一个 Teacher 对象。
public class WriteTeacher { public static void main(String[] args) { try ( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("teacher.txt"))) { Person per = new Person("孙悟空", 500); Teacher t1 = new Teacher("唐僧", per); Teacher t2 = new Teacher("菩提祖师", per); // 依次将四个对象写入输出流 oos.writeObject(t1); oos.writeObject(t2); oos.writeObject(per); oos.writeObject(t2); } catch (IOException ex) { ex.printStackTrace(); } } }
上面程序中的粗体字代码4次调用了 writeObject() 方法来输出对象,实际上只序列化了三个对象,而且序列的两个 Teacher 对象的 student 引用实际是同一个 Person 对象。下面程序读取序列化文件中的对象即可证明这一点。
public class ReadTeacher { public static void main(String[] args) { try ( // 创建一个ObjectInputStream输出流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("teacher.txt"))) { // 依次读取ObjectInputStream输入流中的四个对象 Teacher t1 = (Teacher) ois.readObject(); Teacher t2 = (Teacher) ois.readObject(); Person p = (Person) ois.readObject(); Teacher t3 = (Teacher) ois.readObject(); // 输出true System.out.println("t1的student引用和p是否相同:" + (t1.getStudent() == p)); // 输出true System.out.println("t2的student引用和p是否相同:" + (t2.getStudent() == p)); // 输出true System.out.println("t2和t3是否是同一个对象:" + (t2 == t3)); } catch (Exception ex) { ex.printStackTrace(); } } }
上面程序中的粗体字代码依次读取了序列化文件中的4个 Java 对象,但通过后面比较判断,不难发现 t2 和 t3 是同一个 Java 对象,t1的 student 引用的、t2 的 student 引用的和 p 引用变量引用的也是同一个 Java 对象——这证明了上图所示的序列化机制。
由于 Java 序列化机制使然:如果多次序列化同一个 Java 对象时,只有第一次序列化时才会把该 Java 对象转换成字节序列并输出,这样可能引起一个潜在的问题——当程序序列化一个可变对象时,只有第一次使用 writeObject() 方法输出时才会将该对象转换成字节序列并输出,当程序再次调用、writeObject() 方法时,程序只是输出前面的序列化编号,即使后面该对象的实例变量值已被改变,改变的实例变量值也不会被输出。如下程序所示。
public class SerializeMutable { public static void main(String[] args) { try ( // 创建一个ObjectOutputStream输入流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("mutable.txt")); // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("mutable.txt"))) { Person per = new Person("孙悟空", 500); // 系统会per对象转换字节序列并输出 oos.writeObject(per); // 改变per对象的name实例变量 per.setName("猪八戒"); // 系统只是输出序列化编号,所以改变后的name不会被序列化 oos.writeObject(per); Person p1 = (Person) ois.readObject(); // ① Person p2 = (Person) ois.readObject(); // ② // 下面输出true,即反序列化后p1等于p2 System.out.println(p1 == p2); // 下面依然看到输出"孙悟空",即改变后的实例变量没有被序列化 System.out.println(p2.getName()); } catch (Exception ex) { ex.printStackTrace(); } } }
程序中第一段粗体字代码先使用 writeObject() 方法写入了一个 Person 对象,接着程序改变了 Person 对象的 name 实例变量值,然后程序再次输出 Person 对象,但这次的输出已经不会将 Person 对象转换成字节序列并输出了,而是仅仅输出了一个序列化编号。
程序中①②号粗体字代码两次调用 readObject() 方法读取了序列化文件中的 Java 对象,比较两次读取的 Java 对象将完全相同,程序输出第二次读取的 Person 对象的 name 实例变量的值依然是“孙悟空”,表明改变后的 Person 对象并没有被写入——这与 Java 序列化机制相符。
注意:当使用 Java 序列化机制序列化可变对象时一定要注意,只有第一次调用 writeObject() 方法来输出对象时才会将对象转换成字节序列,并写入到 ObjectOutputStream;在后面程序中即使该对象的实例变量发生了改变,再次调用 writeObject() 方法输出该对象时,改变后的实例变量也不会被输出。
Java9 增加的过滤功能
Java9 为 ObjectInputStream 增加了 setObjectInputFilter()、getObjectInputFilter() 两个方法,其中第一个方法用于为对象输入流设置过滤器。当程序通过 ObjectInputStream 反序列化对象时,过滤器的 checkInput()方法会被自动激发,用于检查序列化数据是否有效。
使用 checkInput() 方法检查序列化数据时有3种返回值。
- Status.REJECTED:拒绝恢复。
- Status.ALLOWED:允许恢复。
- Status.UNDECIDED:未决定状态,程序继续执行检查。
ObjectInputStream 将会根据 ObjectInputFilter 的检查结果来决定是否执行反序列化,如果 checkInput() 方法返回 Status.REJECTED,反序列化将会被阻止;如果 checkInput() 方法返回 Status.ALLOWED,程序将可执行反序列化。
下面程序对前的 ReadObject.java 程序进行改进,该程序将会在反序列化之前对数据执行检查。
public class FilterTest { public static void main(String[] args) { try ( // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.txt"))) { ois.setObjectInputFilter((info) -> { System.out.println("===执行数据过滤==="); ObjectInputFilter serialFilter = ObjectInputFilter.Config.getSerialFilter(); if (serialFilter != null) { // 首先使用ObjectInputFilter执行默认的检查 ObjectInputFilter.Status status = serialFilter.checkInput(info); // 如果默认检查的结果不是Status.UNDECIDED if (status != ObjectInputFilter.Status.UNDECIDED) { // 直接返回检查结果 return status; } } // 如果要恢复的对象不是1个 if (info.references() != 1) { // 不允许恢复对象 return ObjectInputFilter.Status.REJECTED; } if (info.serialClass() != null && // 如果恢复的不是Person类 info.serialClass() != Person.class) { // 不允许恢复对象 return ObjectInputFilter.Status.REJECTED; } return ObjectInputFilter.Status.UNDECIDED; }); // 从输入流中读取一个Java对象,并将其强制类型转换为Person类 Person p = (Person) ois.readObject(); System.out.println("名字为:" + p.getName() + " 年龄为:" + p.getAge()); } catch (Exception ex) { ex.printStackTrace(); } } }
上面程序中的粗体字代码为 ObjectInputStream 设置了 ObjectInputFiIter 过滤器(程序使用 Lambda 表达式创建过滤器),程序重写了 checkInput() 方法。
重写 checkInput() 方法时先使用默认的 ObjectInputFilter 执行检查,如果检查结果不是 Status.UNDECIDED,程序直接返回检查结果。接下来程序通过检验序列化数据,如果序列化数据中的对象不唯一(数据已被污染),程序拒绝执行反序列化;如果序列化数据中的对象不是 Person 对象(数据被污染),程序拒绝执行反序列化。通过这种检查,程序可以保证反序列化出来的是唯一的 Person 对象,这样就让反序列化更加安全、健壮。
自定义序列化
在一些特殊的场景下,如果一个类里包含的某些实例变量是敏感信息,例如银行账户信息等,这时不希望系统将该实例变量值进行序列化;或者某个实例变量的类型是不可序列化的,因此不希望对该实例变量进行递归序列化,以避免引发 java.io.NotSerializableException 异常。
提示:当对某个对象进行序列化时,系统会自动把该对象的所有实例变量依次进行序列化,如果某个实例变量引用到另一个对象,则被引用的对象也会被序列化;如果被引用的对象的实例变量也引用了其他对象,则被引用的对象也会被序列化,这种情况被称为递归序列化。
通过在实例变量前面使用 transient 关键字修饰,可以指定 Java 序列化时无须理会该实例变量。如下 Person 类与前面的 Person 类几乎完全一样,只是它的 age 使用了 transient 关键字修饰。
public class Person implements java.io.Serializable { private String name; private transient int age; // 注意此处没有提供无参数的构造器! public Person(String name, int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 }
提示:transient 关键字只能用于修饰实例变量,不可修饰 Java 程序中的其他成分。
下面程序先序列化一个 Person 对象,然后再反序列化该 Person 对象,得到反序列化的 Person 对象后程序输出该对象的 age 实例变量值。
public class TransientTest { public static void main(String[] args) { try ( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("transient.txt")); // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("transient.txt"))) { Person per = new Person("孙悟空", 500); // 系统会per对象转换字节序列并输出 oos.writeObject(per); Person p = (Person) ois.readObject(); System.out.println(p.getAge()); } catch (Exception ex) { ex.printStackTrace(); } } }
上面程序中的第一行粗体字代码创建了一个 Person 对象,并为它的 name、age 两个实例变量指定了值;第二行粗体字代码将该 Person 对象序列化后输出;第三行粗体字代码从序列化文件中读取该 Person 对象;第四行粗体字代码输出该 Person 对象的 age 实例变量值。由于本程序中的 Person 类的 age 实例变量使用 transient 关键字修饰,所以程序第四行粗体字代码将输出0。
使用 transient 关键字修饰实例变量虽然简单、方便,但被 transient 修饰的实例变量将被完全隔离在序列化机制之外,这样导致在反序列化恢复 Java 对象时无法取得该实例变量值。Java 还提供了一种自定义序列化机制,通过这种自定义序列化机制可以让程序控制如何序列化各实例变量,甚至完全不序列化某些实例变量(与使用 transient 关键字的效果相同)。
在序列化和反序列化过程中需要特殊处理的类应该提供如下特殊签名的方法,这些特殊的方法用以实现自定义序列化。
- private void writeObject(java.io.ObjectOutputStream out) throws IOException;
- private void readObject(iava.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
- private void readObjectNoData() throws ObjectStreamException;
writeObject() 方法负责写入特定类的实例状态,以便相应的 readObject() 方法可以恢复它:通过重写该方法,程序员可以完全获得对序列化机制的控制,可以自主决定哪些实例变量需要序列化,需要怎样序列化。在默认情况下,该方法会调用 out.defaultWriteObject 来保存 Java 对象的各实例变量,从而可以实现序列化 Java 对象状态的目的。
readObject() 方法负责从流中读取并恢复对象实例变量,通过重写该方法,程序员可以完全获得对反序列化机制的控制,可以自主决定需要反序列化哪些实例变量,以及如何进行反序列化。在默认情况下,该方法会调用 in.defaultReadObject 来恢复 Java 对象的非瞬态实例变量。在通常情况下,readObject()方法与 writeObject() 方法对应,如果方法中对 Java 对象的实例变量进行了一些处理,则应该在 readObject() 方法中对其实例变量进行相应的反处理,以便正确恢复该对象。
当序列化流不完整时,readObjectNoData() 方法可以用来正确地初始化反序列化的对象。例如,接收方使用的反序列化类的版本不同于发送方,或者接收方版本扩展的类不是发送方版本扩展的类,或者序列化流被篡改时,系统都会调用 readObjectNoData() 方法来初始化反序列化的对象。
下面的 Person 类提供了 writeObject() 和 readObject() 两个方法,其中 writeObject() 方法在保存 Person 对象时将其 name 实例变量包装成 StringBuffer,并将其字符序列反转后写入;在 readObject() 方法中处理 name 的策略与此对应——先将读取的数据强制类型转换成 StringBuffer,再将其反转后赋给 name 实例变量。
public class Person implements java.io.Serializable { private String name; private int age; // 注意此处没有提供无参数的构造器! public Person(String name, int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 private void writeObject(java.io.ObjectOutputStream out) throws IOException { // 将name实例变量的值反转后写入二进制流 out.writeObject(new StringBuffer(name).reverse()); out.writeInt(age); } private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException { // 将读取的字符串反转后赋给name实例变量 this.name = ((StringBuffer) in.readObject()).reverse().toString(); this.age = in.readInt(); } }
上面程序中用粗体字标出的方法用以实现自定义序列化,对于这个 Person 类而言,序列化、反序列化 Person 实例并没有任何区别——区别在于序列化后的对象流,即使有 Cracker 截获到 Person 对象流,他看到的 name 也是加密后的 name 值,这样就提高了序列化的安全性。
注意:writeObject() 方法存储实例变量的顺序应该和 readObject() 方法中恢复实例变量的顺序一致,否则将不能正常恢复该 Java 对象。
对 Person 对象进行序列化和反序列化的程序与前面程序没有任何区别,故此处不再赘述。
还有一种更彻底的自定义机制,它甚至可以在序列化对象时将该对象替换成其他对象。如果需要实现序列化某个对象时替换该对象,则应为序列化类提供如下特殊方法。
ANY-ACCESS-MODIFIER Object writeReplace() throws ObjectStreamExcepeion;
此 writeReplace() 方法将由序列化机制调用,只要该方法存在。因为该方法可以拥有私有(private)、受保护的(protected)和包私有(package-private)等访问权限,所以其子类有可能获得该方法。例如,下面的 Person 类提供了 writeReplace() 方法,这样可以在写入 Person 对象时将该对象替换成 ArrayList。
public class Person implements java.io.Serializable { private String name; private int age; // 注意此处没有提供无参数的构造器! public Person(String name, int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 // 重写writeReplace方法,程序在序列化该对象之前,先调用该方法 private Object writeReplace() throws ObjectStreamException { ArrayList<Object> list = new ArrayList<>(); list.add(name); list.add(age); return list; } }
Java 的序列化机制保证在序列化某个对象之前,先调用该对象的 writeReplace() 方法,如果该方法返回另一个 Java 对象,则系统转为序列化另一个对象。如下程序表面上是序列化 Person 对象,但实际上序列化的是 ArrayList。
public class ReplaceTest { public static void main(String[] args) { try ( // 创建一个ObjectOutputStream输出流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("replace.txt")); // 创建一个ObjectInputStream输入流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("replace.txt"))) { Person per = new Person("孙悟空", 500); // 系统将per对象转换字节序列并输出 oos.writeObject(per); // 反序列化读取得到的是ArrayList ArrayList list = (ArrayList) ois.readObject(); System.out.println(list); } catch (Exception ex) { ex.printStackTrace(); } } }
上面程序中第一行粗体字代码使用 writeObject() 写入了一个 Person 对象,但第一行粗体字代码使用 readObject() 方法返回的实际上是一个 ArrayList 对象,这是因为 Person 类的 writeReplace() 方法返回了一个 ArrayList 对象,所以序列化机制在序列化 Person 对象时,实际上是转为序列化 ArrayList 对象。
根据上面的介绍,可以知道系统在序列化某个对象之前,会先调用该对象的 writeReplace() 和 writeObject() 两个方法,系统总是先调用被序列化对象的 writeReplace()方法,如果该方法返回另一个对象,系统将再次调用另一个对象的 writeReplace() 方法......直到该方法不再返回另一个对象为止,程序最后将调用该对象的 writeObject() 方法来保存该对象的状态。
与 writeReplace() 方法相对的是,序列化机制里还有一个特殊的方法,它可以实现保护性复制整个对象。这个方法就是:
ANY-ACCESS—MODIFIER Object readResolve() throws ObjectStreamException;
这个方法会紧接着 readObject() 之后被调用,该方法的返回值将会代替原来反序列化的对象,而原来 readObject() 反序列化的对象将会被立即丢弃。
readResolve() 方法在序列化单例类、枚举类时尤其有用。当然,如果使用 Java5 提供的 enum 来定义枚举类,则完全不用担心,程序没有任何问题。但如果应用中有早期遗留下来的枚举类,例如下面的 Orientation 类就是一个枚举类。
public class Orientation implements java.io.Serializable { public static final Orientation HORIZONTAL = new Orientation(1); public static final Orientation VERTICAL = new Orientation(2); private int value; private Orientation(int value) { this.value = value; } }
在 Java5 以前,这种代码是很常见的。Orientation 类的构造器私有,程序只有两个 Orientation 对象,分别通过 Orientation 的 HORIZONTAL 和 VERTICAL 两个常量来引用。但如果让该类实现 Serializable 接口,则会引发一个问题,如果将一个 Orientation.HORIZONTAL 值序列化后冉读出,如下代码片段所示。
oos = new ObjectOutputStream(new FileOutputStream("transient")); // 写入 Orientation.HORIZONTAL 值 oos.writeObject(Ocientation.HORIZONTAL); // 创建一个 ObjectInputStream 输入流 ois = new ObjectInputStream(new FileInputStream("transient")); // 读取刚刚序列化的值 Orientation ori = (Orientation)ois.readObject();
如果立即拿 ori 和 Orientation.HORIZONTAL 值进行比较,将会发现返回 false。也就是说,ori 是一个新的 Orientation 对象,而不等于 Orientation 类中的任何枚举值——虽然 Orientation 的构造器是 private 的,但反序列化依然可以创建 Orientation 对象。
提示:前面已经指出,反序列化机制在恢复 Java 对象时无须调用构造器来初化 Java 对象。从这个意义上来看,序列化机制可以用来“克隆”对象。
在这种情况下,可以通过为 Orientation 类提供一个 readResolve() 方法来解决该问题,readResolve() 方法的返回值将会代替原来反序列化的对象,也就是让反序列化得到的 Orientation 对象被直接丢弃。下面是为 Orientation 类提供的 readResolve() 方法。
// 为枚举类增加readResolve()方法 private Object readResolve() throws ObjectStreamException { if (value == 1) { return HORIZONTAL; } if (value == 2) { return VERTICAL; } return null; }
通过重写 readResolve() 方法可以保证反序列化得到的依然是 Orientation 的 HORIZONTAL 或 VERTICAL 两个枚举值之一。
提示:所有的单例类、枚举类在实现序列化时都应该提供 readResolve() 方法,这样才可以保证反序列化的对象依然正常。
与 writeReplace() 方法类似的是,readResolve() 方法也可以使用任意的访问控制符,因此父类的 readResolve() 方法可能被其子类继承。这样利用 readResolve() 方法时就会存在一个明显的缺点,就是当父类已经实现了 readResolve() 方法后,子类将变得无从下手。如果父类包含一个 protected 或 public 的 readResolve() 方法,而且子类也没有重写该方法,将会使得子类反序列化时得到一个父类的对象——这显然不是程序要的结果,而且也不容易发现这种错误。总是让子类重写 readResolve() 方法无疑是一个负担,因此对于要被作为父类继承的类而言,实现 readResolve() 方法可能有一些潜在的危险。
通常的建议是,对于 final 类重写 readResolve() 方法不会有任何问题;否则,重写 readResolve() 方法时应尽量使用 private 修饰该方法。
另一种自定义序列化机制
Java 还提供了另一种序列化机制,这种序列化方式完全由程序员决定存储和恢复对象数据。要实现该目标,Java 类必须实现 Externalizable 接口,该接口里定义了如下两个方法。
- void readExternal(ObjectInput in):需要序列化的类实现 readExternal() 方法来实现反序列化。该方法调用 DataInput(它是 ObjectInput 的父接口)的方法来恢复基本类型的实例变量值,调用 ObjectInput 的 readObject() 方法来恢复引用类型的实例变量值。
- void writeExternal(ObjectOutput out):需要序列化的类实现 writeExternal() 方法来保存对象的状态。该方法调用 DataOutput(它是 ObjectOutput 的父接口)的方法来保存基本类型的实例变量值,调用 ObjectOutput 的 writeObject() 方法来保存引用类型的实例变量值。
实际上,采用实现 Externalizable 接口方式的序列化与前面介绍的自定义序列化非常相似,只是 Externalizable 接口强制自定义序列化。下面的 Person 类实现了 Externalizable 接口,并且实现了该接口里提供的两个方法,用以实现自定义序列化。
public class Person implements java.io.Externalizable { private String name; private int age; // 注意必须提供无参数的构造器,否则反序列化时会失败。 public Person() { } public Person(String name, int age) { System.out.println("有参数的构造器"); this.name = name; this.age = age; } // 省略name与age的setter和getter方法 public void writeExternal(java.io.ObjectOutput out) throws IOException { // 将name实例变量的值反转后写入二进制流 out.writeObject(new StringBuffer(name).reverse()); out.writeInt(age); } public void readExternal(java.io.ObjectInput in) throws IOException, ClassNotFoundException { // 将读取的字符串反转后赋给name实例变量 this.name = ((StringBuffer) in.readObject()).reverse().toString(); this.age = in.readInt(); } }
上面程序中的 Person 类实现了 java.io.Externalizable 接口(如程序中第一行粗体字代码所示),该 Person 类还实现了 readExternal()、writeExternal() 两个方法,这两个方法除方法签名和 readObject()、writeObject() 两个方法的方法签名不同之外,其方法体完全一样。
如果程序需要序列化实现 Externalizable 接口的对象,一样调用 ObjectOutputStream 的 writeObject() 方法输出该对象即可;反序列化该对象,则调用 ObjectInputStream 的 readObject() 方法,此处不再赘述。
需要指出的是,当使用 Externalizable 机制反序列化对象时,程序会先使用 public 的无参数构造器创建实例,然后才执行 readExternal() 方法进行反序列化,因此实现 Externalizable 的序列化类必须提供 public 的无参数构造器。
关于两种序列化机制的对比如下图所示。

虽然实现 Externalizable 接口能带来一定的性能提升,但由于实现 Externalizable 接口导致了编程复杂度的增加,所以大部分时候都是采用实现 Serializable 接口方式来实现序列化。
关于对象序列化,还有如下几点需要注意。
- 对象的类名、实例变量(包括基本类型、数组、对其他对象的引用)都会被序列化:方法、类变量(即 static 修饰的成员变量)、transient 实例变量(也被称为瞬态实例变量)都不会被序列化。
- 实现 Serializable 接口的类如果需要让某个实例变量不被序列化,则可在该实例变量前加 transient 修饰符,而不是加 static 关键字。虽然 static 关键字也可达到这个效果,但关键字不能这样用。
- 保证序列化对象的实例变量类型也是可序列化的,否则需要使用 transient 关键字来修饰该实例变量,要不然,该类是不可序列化的。
- 反序列化对象时必须有序列化对象的 class 文件。
- 当通过文件、网络来读取序列化后的对象时,必须按实际写入的顺序读取。
版本
根据前面的介绍可以知道,反序列化 Java 对象时必须提供该对象的 class 文件,现在的问题是,随着项目的升级,系统的 class 文件也会升级,Java 如何保证两个 class 文件的兼容性?
Java 序列化机制允许为序列化类提供一个 private static final 的 serialVersionUID 值,该类变量的值用于标识该 Java 类的序列化版本,也就是说,如果一个类升级后,只要它的 serialVersionUID 类变量值保持不变,序列化机制也会把它们当成同一个序列化版本。
分配 serialVersionUID 类变量的值非常简单,例如下面代码片段:
public class Test { //为该类指定一个 serialVersionUID 类变量值 private static final long serialVersionUID = 512L; }
为了在反序列化时确保序列化版本的兼容性,最好在每个要序列化的类中加入 private static final long serialVersionUID 这个类变量,具体数值自己定义。这样,即使在某个对象被序列化之后,它所对应的类被修改了,该对象也依然可以被正确地反序列化。
如果不显式定义 serialVersionUID 类变量的值,该类变量的值将由 JVM 根据类的相关信息计算,而修改后的类的计算结果与修改前的类的计算结果往往不同,从而造成对象的反序列化因为类版本不兼容而失败。
可以通过 JDK 安装路径的 bin 目录下的 serialver.exe 工具来获得该类的 serialVersionUID 类变量的值,如下命令所示。
serialver Person
运行该命令,输出结果如下:
Person:static final long serialVersionUID = -2595800114629327570L;
上面的 -2595800114629327570L 就是系统为该 Person 类生成的 serialVersionUID 类变量的值。如果在运行 serialver 命令时指定 -show 选项(不要跟类名参数),即可启动如图所示的图形用户界面。
不显式指定 serialVersionUID 类变量的值的另一个坏处是,不利于程序在不同的 JVM 之间移植。因为不同的编译器对该类变量的计算策略可能不同,从而造成虽然类完全没有改变,但是因为 JVM 不同,也会出现序列化版本不兼容而无法正确反序列化的现象。
如果类的修改确实会导致该类反序列化失败,则应该为该类的 serialVersionUID 类变量重新分配值。那么对类的哪些修改可能导致该类实例的反序列化失败呢?下面分三种情况来具体讨论。
- 如果修改类时仅仅修改了方法,则反序列化不受任何影响,类定义无须修改 serialVersionUID 类变量的值。
- 如果修改类时仅仅修改了静态变量或瞬态实例变量,则反序列化不受任何影响,类定义无须修改 serialVersionUID 类变量的值。
- 如果修改类时修改了非瞬态的实例变量,则可能导致序列化版本不兼容。如果对象流中的对象和新类中包含同名的实例变量,而实例变量类型不同,则反序列化失败,类定义应该更新 serialVersionUID 类变量的值。如果对象流中的对象比新类中包含更多的实例变量,则多出的实例变量值被忽略,序列化版本可以兼容,类定义可以不更新 serialVersionUID 类变量的值;如果新类比对象流中的对象包含更多的实例变量,则序列化版本也可以兼容,类定义可以不更新 serialversionUID 类变量的值;但反序列化得到的新对象中多出的实例变量值都是null(引用类型实例变量)或0(基本类型实例变量)。