1 索引的基本概念
索引的定义:索引是数据库高效获取数据的数据结构
- 这种数据结构以某种方式引用(指向)数据,可以在数据结构上进行高效查找
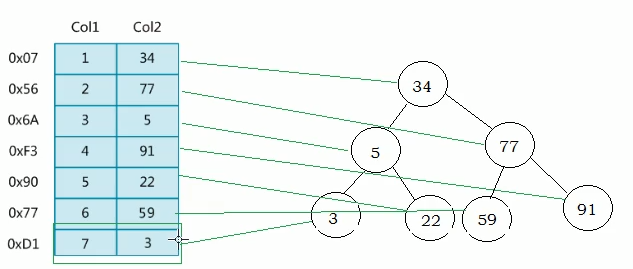
实例:二叉查找树通过二叉树的结构提高查找数据的效率(下图)。
优势:
- 提高数据检索效率,降低IO成本。
- 降低数据排序成本,减少CPU开销
劣势:
-
影响数据表更新的效率(INSERT UPDATE DELETE),需要额外维护索引信息。
-
额外占用空间,数据库的索引也是一张表,包含主键与索引字段并指向实体类的记录。
2 索引结构的分类
2-1 四种结构概述
MYSQL支持四种索引结构:
| 名称 | 特点 |
|---|---|
| B tree 索引 | 最常用 |
| Hash 索引 | |
| R tree 索引(空间索引) | 用作地理数据存储 |
| Full Text 索引 | 通过倒排索引,也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。 |
注意点:一般索引默认指的就是B+树索引结构组织的索引,其中聚合索引,复合索引,前缀索引,唯一索引默认都是B+树索引。
2-2 多路平衡查找树知识点(B树与B+树)
B树的知识点复习
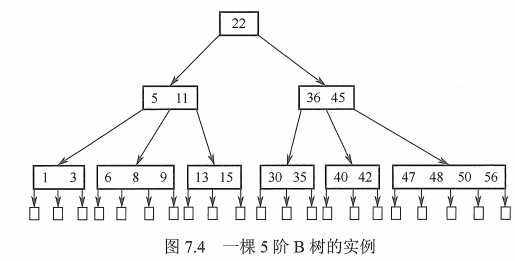
基本概述
B树也叫多路平衡查找树,令B树所有节点孩子个数的最大值为m,那么这个树就是m阶B树。
一棵m阶B树必须满足以下性质(从节点子树个数,节点的内容,节点的关键字与子树个数关系回答):
-
节点的子树个数(小于阶数m):
- 根节点(非终端节点):至少有2棵子树
- 非叶节点(不包括根节点):至少有 上取整[m/2] 棵子树。
-
节点的关键字个数: 等于节点子树个数减去1
-
节点的内容
- 非叶节点:带有信息包括关键字个数,顺序排列的关键字(方便查找记录),以及子树的指针。

- 叶节点:没有信息,通常以空指针替代
B数的查找
查找分为2个基本步骤:
1)在B树中找结点(磁盘进行,B树的高度与磁盘读取次数相关,B树层数多分支少,有利于磁盘IO) 2)节点中找关键字(内存进行,顺序查找,折半查找)
B树插入与删除可以参考王道的资料。
B+树的知识点复习
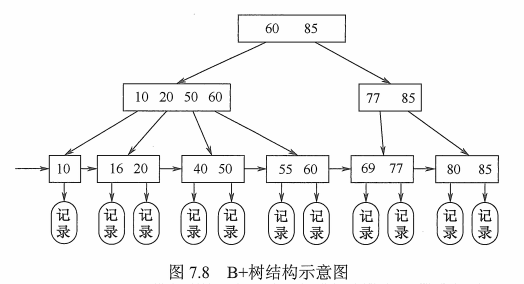
概述: B+树是为了满足数据库而出现的B树的变形树。
一棵m阶B树必须满足以下性质:
-
节点的子树个数(小于等于阶数m):
- 根节点(非终端节点):至少有2棵子树
- 非叶节点(不包括根节点):至少有 上取整[m/2] 棵子树。
-
节点的关键字个数: 等于节点子树个数
-
节点的内容
-
非叶节点:包含子节点关键子的最大值以及指向子节点的指针,关键字按照大小排序
-
叶节点:含有所有关键字以及指向相应记录的指针,关键字按照大小排序
-
B树与B+树区别
- 2种树的节点的关键字个数与节点子树的个数关系不同
- 节点的内容
- B+树只有叶节点存储指向数据记录的指针,并且叶节点之间会相互连接,方便范围查询,非叶节点仅起到索引作用。叶节点会与非叶节点存在关键字重复。
- B树各个节点关键字不会重复。叶节点不存储信息。
2-3 MYSQL中B+树
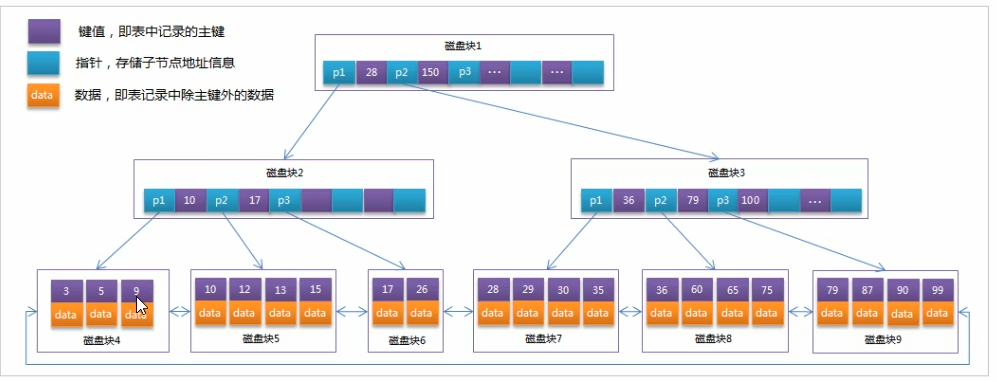
特点:在原有的B+树的基础上,添加了相邻叶子节点的访问指针,形成了带有顺序指针的B+树,提高区间访问的性能。
注意点:
为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?
- B+的磁盘读写代价更低
- B+的非叶节点没有指向关键字具体信息的指针,更加节约磁盘空间。
- B+-tree的查询效率更加稳定。
- 任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当
3 索引分类
可以大致分为以下三类:
1)单值索引
基本思想:每一个单值索引是对表中的一列建立索引。一个数据表中有多列数据的话,那么可以建立多个单值索引。
2)唯一索引
基本思想:对建立索引的列进行约束,列中的值必须具有唯一性,但允许有空值。
3)复合索引
基本思想:对表中多列数据建立索引,
- 实例:比如可以对学生表的id与name共2列数据建立索引。
4 索引的基本语法
数据表准备
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL,
PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2);
insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China');
insert into `country` (`country_id`, `country_name`) values(2,'America');
insert into `country` (`country_id`, `country_name`) values(3,'Japan');
insert into `country` (`country_id`, `country_name`) values(4,'UK');
4-1 索引的创建,查看,删除,alert命令改变
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
UNIQUE|FULLTEXT|SPATIAL:可选项,唯一|全文|空间
[USING index_type] 默认使用B+ tree
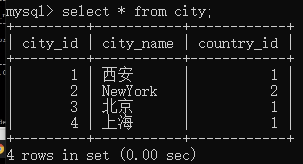
对city表建立索引:
- city_id是主键,数据库会默认给该列创建索引,注意该索引默认就是唯一索引。
- 为city_name这一列数据创建一个普通索引
create index idx_city_name on city(city_name);

上面2张图的分析:
- 可以看到表的主键会有数据库自动创建一个主键索引,索引的名称(Key_name)为PRIMARY, 由于主键本身的特性,其创建的索引与唯一索引有相似的特点,但他们本质是不同的,在Non_unique为0可以判断出。
- 第二个索引是单列索引,但不是唯一索引,在Non_unique为1可以判断出
通过
show index from 表名; # 查看这个表所建立的索引。
DROP INDEX index_name ON tbl_name; # 删除这个表的索引
alert命令
alter table tb_name add primary key(column_list); # 为表添加一个主键并创建索引
alter table tb_name add unique index_name(column_list); # 为表添加唯一索引
alter table tb_name add index index_name(column_list); # 为表添加普通索引
alter table tb_name add fulltext index_name(column_list); # 为表添加全文索引
5 索引的设计原则
问1:哪些表需要建立索引?
建立索引的表应满足2个要求:
- 查询频次高
- 数据量大
问2:哪些字段需要建立索引?
最佳候选字段应当从where子句中选取,如果子句中字段比较多,应该优先选择效果比较好的关键字段。
问3:建立索引时应优先选择那种类型的索引?
优先使用唯一索引,区分度高,索引效率高
问4:索引字段长度该如何确定?
索引长度应尽可能短,短索引能够提高磁盘IO的效率,磁盘单次IO能够获得更多的索引值。
问5:组合索引的一些常识?
组合索引可以利用最左前缀,N个列组合而成的索引相当于创建了N个索引。
- 当查询只用到N个索引的一部分字段时,也能够借助组合索引提升查询的效率。
组合索引简介:
创建复合索引:
CREATE INDEX idx_name_email_status
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
参考资料
20210222