爬虫的核心思想:模拟浏览器正常访问服务器,一般情况只要浏览器能访问的,都可以爬,如果被反爬,则考虑反复测试添加Request Header数据,知道可以爬取为止。
反爬思路目前知道的有:User-Agent,Cookie,Referer,访问速度,验证码,用户登录及前端js代码验证等。本例遇到js验证 User-Agent Referer Cookie共计4种反爬机制。
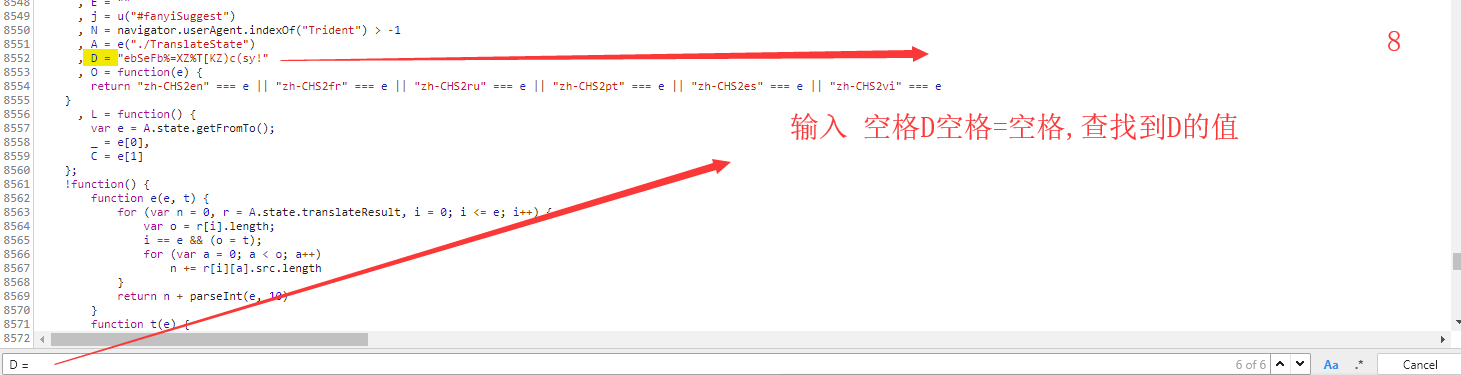
关键部分是,参数headers和data的构造,headers要进行反复测试,data数据里面的变量查找思路。
参考资料:
用Python破解有道翻译反爬虫机制 https://blog.csdn.net/nunchakushuang/article/details/75294947
python破解网易反爬虫机制 https://blog.csdn.net/luosai19910103/article/details/79522067
一些反爬机制 https://blog.csdn.net/javakklam/article/details/79841901
有道翻译页面,左边输入要翻译的字符串,右边会自动输出翻译的结果,如下图
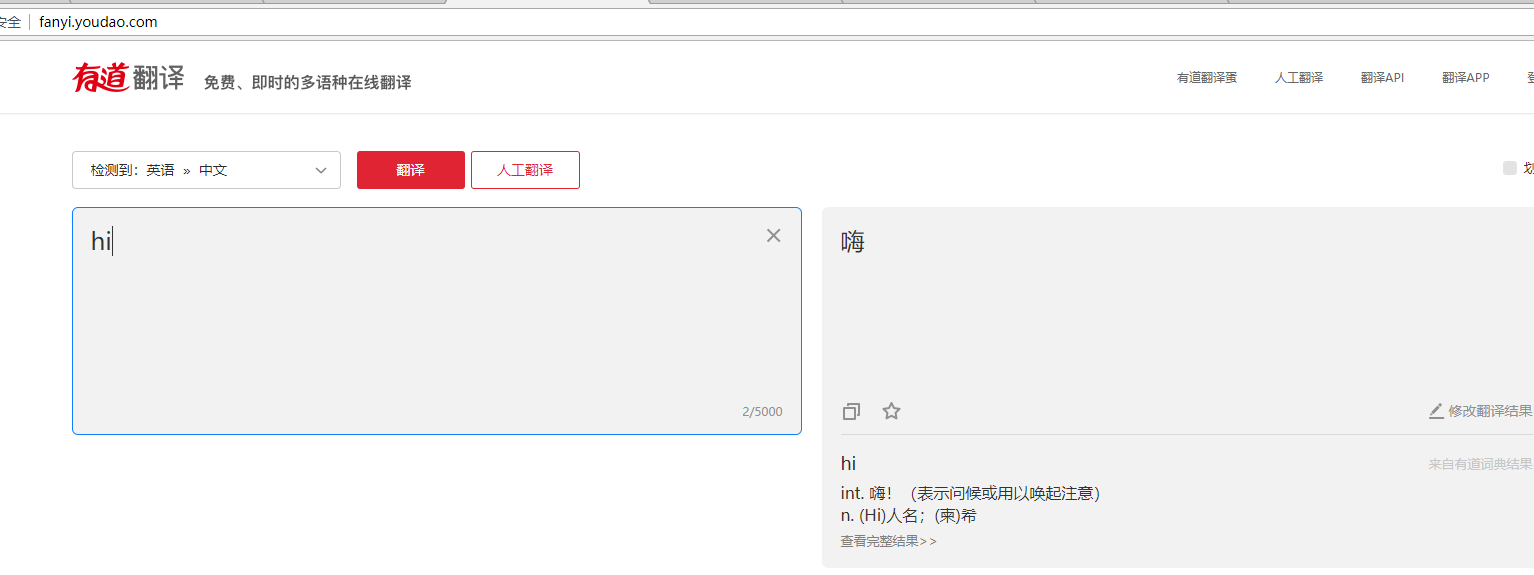
经过多次输入字符测试,发现页面无刷新,猜测可能使用ajax,然后进行抓包分析,发现的确使用ajax传输数据




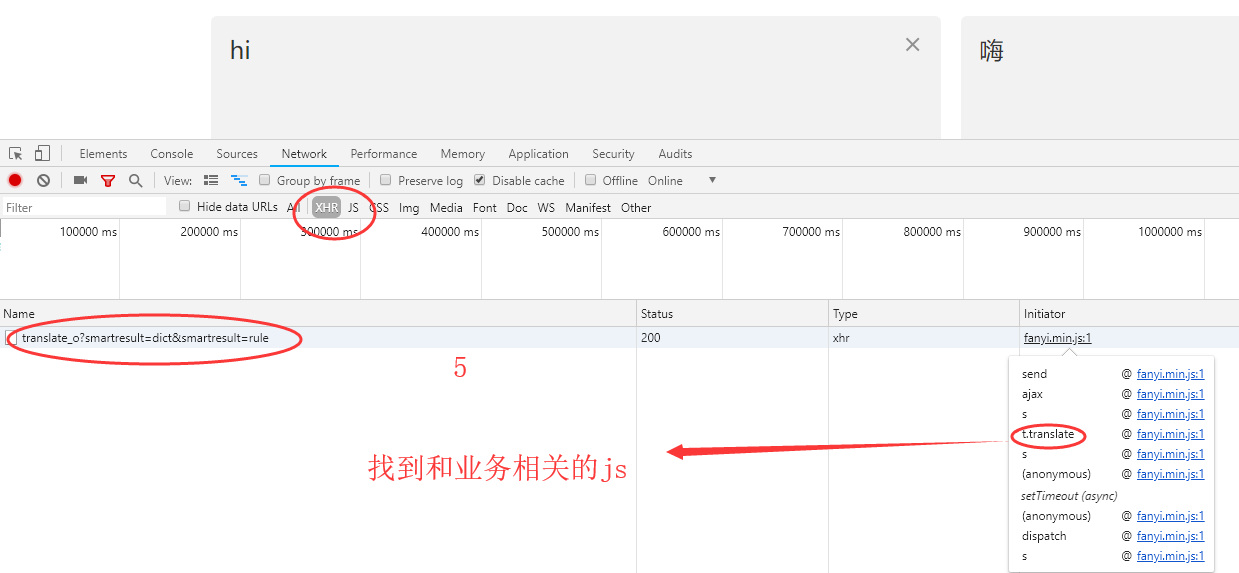
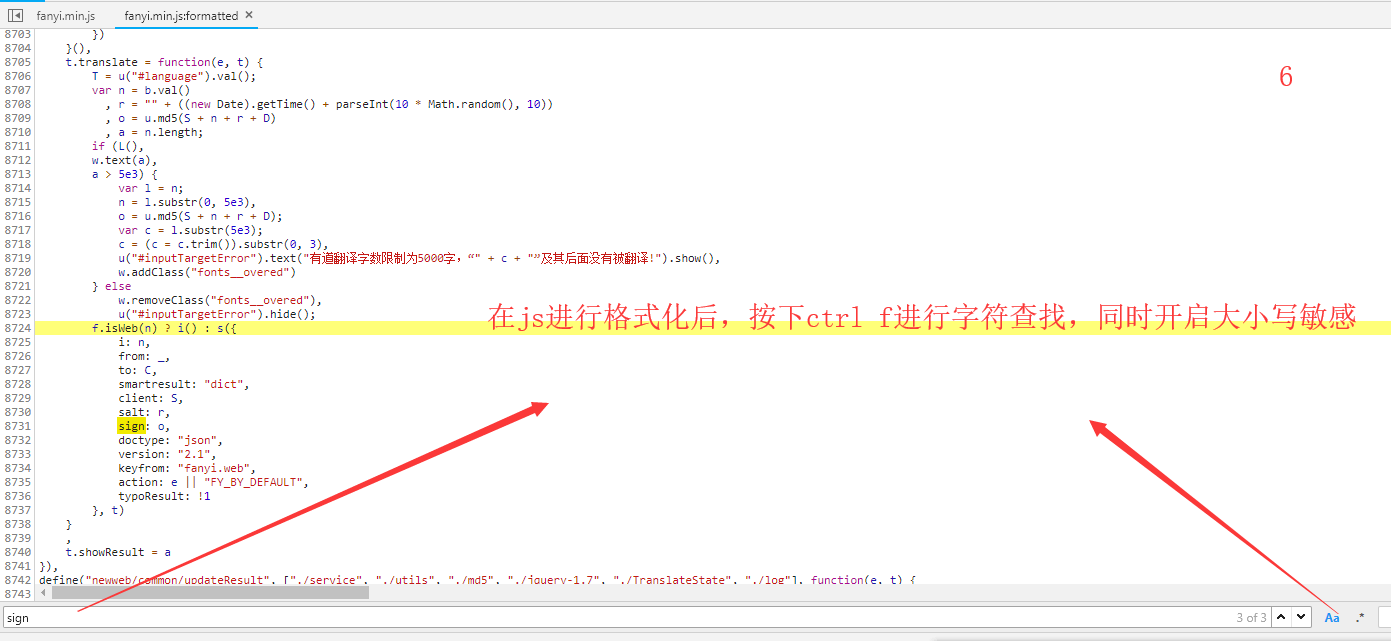
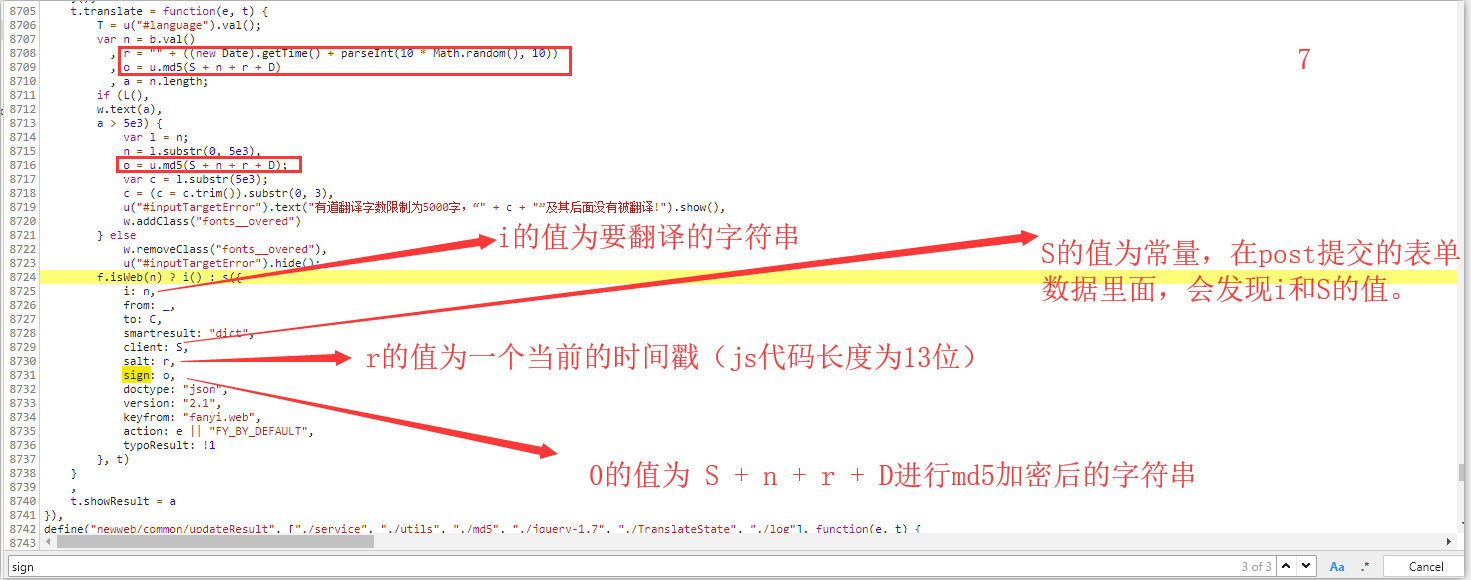
代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib
import urllib2
import time
import hashlib
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
keyword = raw_input('请输入要翻译的字符串: ')
# headers作用模拟浏览器
headers = {
# "Accept": "application/json, text/javascript, */*; q=0.01",
# "Connection": "keep-alive",
# "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "你的浏览器cookie值",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36",
# "X-Requested-With": "XMLHttpRequest",
}
salt = str(int(time.time()*1000))
m = hashlib.md5()
str = "fanyideskweb" + keyword + salt + "ebSeFb%=XZ%T[KZ)c(sy!"
m.update(str)
sign = m.hexdigest().encode('utf-8')
print(sign)
# data为post请求数据
data = {
"i":keyword,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"salt":salt,
"sign":sign,
"doctype":"json",
"version":"2.1",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTIME",
"typoResult":"false"
}
# 对post上传的数据进行urlencode编码
data = urllib.urlencode(data)
# urllib 仅可以接受URL,不能创建 Request 类实例,也不能设置参数headers ,但可以对url进行编码,而urllib2不能编码,所以经常一起使用
# 而urllib2.urlopen(url)不能构造复杂的request,所以要使用urllib2.Request(url,data=data,headers=headers),2者都是有data参数时表示post提交数据,headers的值为模仿浏览器请求头里面的的数据,格式为字典,让服务器接受的数据看起来像使用浏览器访问。
request = urllib2.Request(url,data=data,headers=headers)
response = urllib2.urlopen(request)
print(response.read())
代码测试,如下图
