协同过滤分为 memory-based 和 model based
1. memory-based 利用用户物品之间相似度进行推荐
一种是 item-item 即喜欢这个物品的用户还喜欢..
一种是 user-item 即与你有相似爱好的用户还喜欢..
现在有个评分矩阵R,行表示用户,列表示物品,R(i,j)表示用户i对物品j的评分,R(:,j)表示所有用户对物品j的评分列,R(i,:)表示用户i对所有物品的评分行,用户与物品没有交互,评分自然为0,可以知道一般的矩阵R是稀疏的。
由user-item 计算每个用户的相似度,一般取(余弦相似度),即 cos(R(i,:),R(k,:)), 利用在sklearn中的模块很容易计算得到用户相似矩阵
from sklearn.metrics.pairwise import pairwise_distances user_similarity = pairwise_distances(R, metric='cosine')
由item-item 计算每件商品相似度,
item_similarity = pairwise_distances(R.T, metric='cosine')
得到相似度就可以计算预测矩阵P, 即将用户与商品之间没有交互的R(i,j)赋上一个预测值
先考虑 item-item 我们可以知道如果物品m与某个物品b相似度较高,那么 与b有交互的用户k对b的评分会很接近于m,最简单的是m=b,那么评分相等,可以给出公式来预估k对m的评分,其中分母起到正则化的作用

用户k对物品m的评分预测:分子表示 物品m与其他所有物品b相似度 与 用户对其他物品b 的乘积 的和,相当于加权平均
考虑user-item 如果两个用户相似,自然他们对某个物品评分应该接近,但如果总有些用户a喜欢给物品评很高的分,这时候即使两个用户不相似,按照item-item 的公式,他们也能占到很高的权重,这就相当于一种干扰,一种噪声, 这样,对每个用户评分做一个平均,标准化

用户k对物品m的评分预测: 用户k对所有物品评分平均+ (用户k与其他所有用户a相似度 与 (其他用户a对m的评分-其他用户a对所有物品的平均评分)的加权和)/分母
这样我们就可以编写预测函数
def predict(R, similarity, type='item'): if type == 'user': mean_user_rating = R.mean(axis=1)# axis=1 计算每行 rating_d = (R - mean_user_rating[:, np.newaxis]) #np.newaxis根据 R 调整矩阵 prediction = mean_user_rating[:, np.newaxis] + similarity.dot(rating_d) / np.array([np.abs(similarity).sum(axis=1)]).T elif type == 'item': prediction = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)]) return prediction
通常我们还要对预测结果进行评价,有多种评价函数,一般可以用RMSE(根平均平方误差)
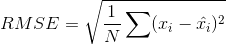
自然我们要拿R的非0值进行比较,计算预测前后的误差
from sklearn.metrics import mean_squared_errordef rmse(prediction, test_R): prediction = prediction[test_R.nonzero()].flatten() test_R= test_R[test_R.nonzero()].flatten() return sqrt(mean_squared_error(prediction, test_R))
2 model-based 采用矩阵因子分解来近似填充原矩阵
一般来说矩阵R是稀疏的,考虑矩阵计算中的奇异值分解(SVD),通过将其分解成三个矩阵,其中S对角元素称为奇异值,通过过滤前k大的奇异值,可以近似保存原先矩阵的信息,正如一个图像矩阵,选取合适的k,重新计算得到的新图像可以在感官上与原图像无差异。
具体公式如

X 是m×n , U 是m×k , S 是 k×k , V.T 是k×n
这样通过计算就可以得到预测矩阵X
import scipy.sparse as sp from scipy.sparse.linalg import svds U, s, VT = svds(train_R, k = 15) #选择k=15 S=np.diag(s) X = np.dot(np.dot(U, S), VT)
本文主要介绍了memory-based 和 model-based的协同过滤方法